Seedance 2.0 Is Finally Out: First Impressions
ByteDance opened up the public release of Seedance 2.0 today, April 15. They had promised the model late last year, but access stayed locked to commercial partners for months, with delay after delay. As of today, anyone can try it.
The pitch is strong. It’s a multimodal video generation model that takes text, up to 9 reference images, 3 reference video clips, and 3 audio tracks all in the same call. On top of that, it produces up to 15 seconds of output with native synced audio (dialogue, sound effects, ambient music), supports video extension, surgical editing of characters and objects, and prompt-driven camera planning. ByteDance is pitching it at commercial advertising, explainer videos, film production, e-commerce, and gaming. Translation: for content creators trying to climb out of the “random meme” tier and start producing things that look professional.
If you want a quick visual tour before going further, here’s a great walkthrough from Stefan, of the Stefan 3D AI Lab channel, which I already plugged in the post on AI 3D modeling:
The main interface is Dreamina’s “Photo Studio,” where you pick the generation mode and stack your references. So far I’ve only tested the standard multi-reference mode.
Test 1: lip sync with podcast audio
My first test was simple. I grabbed a few seconds of the opening bumper from my podcast The M.Akita Chronicles, which is generated by AI through an ElevenLabs v3 pipeline, passed in my new anime-style avatar as a reference image, and asked Seedance to make the character lip-sync and gesture along with that audio.
The result is decent. All of that came from a single still image. The lip sync follows the speech reasonably well, the expression has some life to it, and the hand gesture lands at the right beat. But this is a YouTube short or Instagram clip at best. Not the kind of animation you’d open a serious video with.
The feature that actually matters: video reference
And here’s what I think is the only real use of these models for actual work: feeding in video as a reference. Text alone is never going to be precise enough. You can describe a scene with whatever vocabulary you want, swap adjectives, specify lens, angle, framing, and every generation will still hand you back something subtly different. It’s a slot machine. Great for memes, terrible for production.
Most amateurs see one random clip that comes out nice on the first try and go straight to flooding their X and Instagram feeds with it. That’s not control. That’s luck. For film, for ads, for show openers, for anything where the next shot has to match the previous one, you have to be able to tell the model: “do exactly this motion, with exactly this camera.” That’s where reference video changes the game, because it replaces hours of 3D modeling, rigging, animation, and rendering that would cost a fortune in a studio.
For my test, I recycled the model I’d already generated in the post on AI 3D with Hunyuan and Nano Banana, where I tested how far you can take 3D modeling from a prompt and even hit “print” on the result. But for something more cinematic I wanted a model with a proper animation cycle. So I grabbed the Darth Talon model from Sketchfab, which has a short, well-made motion sequence, just because it looked cool.
I imported the FBX into Blender, set up a basic camera and lighting, and did a quick Cycles render. Nothing pretty about it, just a sketch to feed in as motion and framing reference.
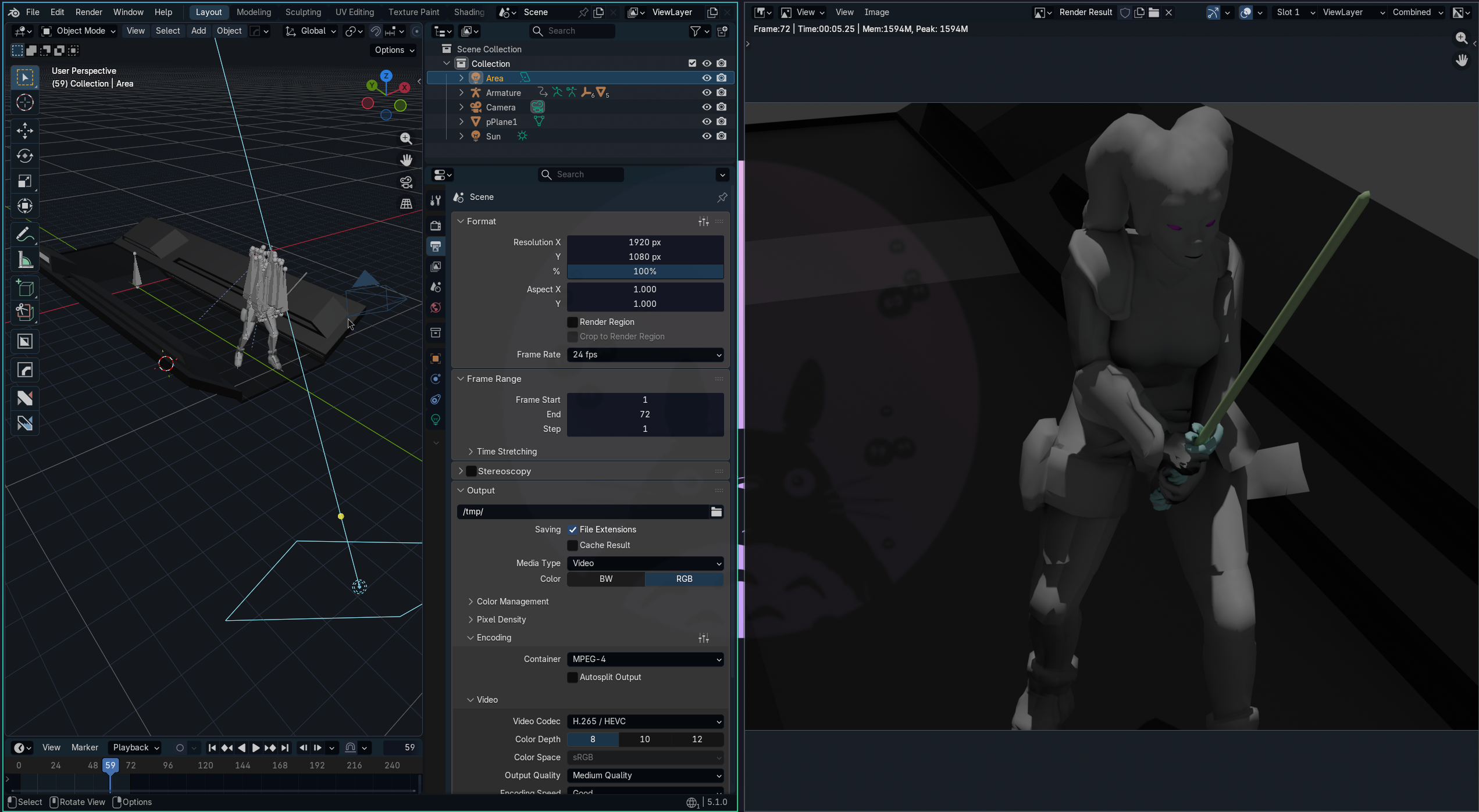
I uploaded that render to Seedance as a video reference along with three t-pose images of the character (front, back, left side) for visual consistency:



First attempt, with a generic prompt:
Not bad. The character keeps its identity, the lighting got a serious upgrade over my raw render, and the clip is coherent. But the motion and camera position drifted noticeably from the reference. The model basically read it as “there’s a character here that looks like that doing something like that,” and improvised the rest.
Then I remembered Stefan’s tutorial: the trick is to literally drop something like Follow exact motion and camera from reference video into the prompt. Tried again:
A lot better. It’s clearly following the reference choreography, the camera angle matches in several beats, and the character looks more polished than anything I could hand-render in a quick Cycles sketch. But it’s still not a frame-for-frame match. In some shots the model is still taking liberties with timing, position, and framing. There are other prompting tricks and parameters to play with, but I stopped here to write this up while the launch is still fresh.
ComfyUI, Runway, and the rest of the ecosystem
Seedance 2.0 also already shipped as a ComfyUI cloud node, which is great for anyone who wants to drop the model into a bigger pipeline without bouncing between web UIs. If you’ve already got an image-gen workflow built in ComfyUI, this is genuinely handy.
And for anyone who wants volume without doing the per-generation credit math, Runway is offering Seedance 2.0 as part of their Unlimited plan, which runs around $76/month annual or $95/month monthly. “Unlimited” means no per-generation charge, but you do trade for lower queue priority at peak hours and an output storage cap. If you iterate a lot, the subscription model makes way more sense than buying credits one at a time.
The price question
Seedance’s own pricing is credit-based. The Standard plan is $24.90/month annual or $49.90/month monthly, and gets you 2,500 credits a month. Every 10 seconds of generated video burns 6 credits.
The math is brutal. With 2,500 credits on Standard, you get about 416 ten-second generations a month. Sounds like a lot, until you remember my own test: it took at least two tries to get close to what I wanted, and even then it wasn’t a one-to-one match. In practice, plan on 3 to 5 regenerations per usable scene. That drops your real number to something like 80 to 140 short clips per month. Maybe enough for a solo creator doing short-form content. Nowhere near enough for production that needs minutes of polished, continuous video.
The higher tiers scale credits roughly linearly, but the same problem holds: at today’s price, Seedance 2.0 is still a tool for short clips and well-made memes, or for pre-vis sketches before you send the real thing to an actual studio. It doesn’t replace continuous professional production. For that use case, Runway with Unlimited is honestly the cheaper option in practice. Full pricing table here.
What nobody wants to talk about: restrictions and deepfakes
Two things I don’t want to leave out. First: Seedance 2.0 took its sweet time getting to the public partly because ByteDance is being a lot more conservative than the competition when it comes to moderation. The model blocks generation that uses real people as reference (celebrities, politicians, public figures) and filters strong-IP characters from Disney, Marvel/DC, Nintendo, and registered trademarks generally. If you want the details of what passes, what doesn’t, and why ByteDance went that way, this MindStudio piece breaks it down. It makes sense: ByteDance operates across dozens of jurisdictions, lives under heavy regulatory scrutiny worldwide, and has the elephant in the room of Hollywood pushing the entire industry with copyright suits over training data and generation. The release got delayed and arrived with heavier filters precisely because of that.
Second point, and this is the one that matters more: for you, the average reader, the message is that deepfakes are no longer hypothetical. Photos on the internet stopped counting as proof a long time ago, because image models like Nano Banana, Hunyuan, and the rest deliver realism that fools anyone. Now video sits in the same bucket. What we just saw above, where a couple of references and two prompts get you a coherent animated scene in minutes, is just the start. The average person, with no training, isn’t going to be able to tell generated video from real video at a glance anymore. And Seedance’s filters only block above-board, legitimate use. Anyone with bad intent will always find a path through open source models, workarounds, or less strict platforms. That’s the world we’re in now, and the sooner we collectively accept it, the better off we are.
No, this doesn’t replace real artists
Let me cut off the usual speech before it shows up in the comments. No, Seedance doesn’t replace VFX artists, directors, editors, none of that. This is a hammer. The tool is the same for everybody. What comes out the other end depends entirely on who’s swinging it.
Anyone who’s actually studied framing, pacing, continuity, art direction, editing, color, composition is going to use Seedance to 10x the work they were already capable of delivering. Anyone who hasn’t studied any of that is going to crank out the same Instagram meme they were already cranking out, just 10x faster. The AI reflects who you are. If you’re a real artist, the tool multiplies you. If you only think you are, the tool multiplies the mediocrity. There’s no miracle here.
This is exactly why the whole “now everyone can be a film director with AI” wave is the same song we’ve heard with the digital camera, with Photoshop, with After Effects, with Premiere, and with every powerful tool that’s shown up in the last 30 years. The technical bar drops. The bar of taste, reference, and study sits exactly where it always has. Good people get more productive. Everyone else still needs to hire real ones to do real work.
Where this goes next
Seedance 2.0 is clearly a step in the right direction, but it’s not the tool that replaces professional production yet. Text alone stays imprecise, video reference helps but still drifts, and the price per minute of polished output is high relative to what you actually get. The good news is that this story always rhymes: Google has Veo, Runway has its own model and is also reselling Seedance, Kling and Hailuo from China keep pushing, and the open source models are gaining ground. OpenAI had Sora, but they shut it down. As competition tightens, quality goes up and price comes down. A year or two from now we’ll be looking back at this post and finding what I just showed pretty quaint. Same as it ever was.