Claude Code's Source Code Leaked. Here's What We Found Inside.
Updated April 2, 2026: if you already read this yesterday, jump straight to the new update section.
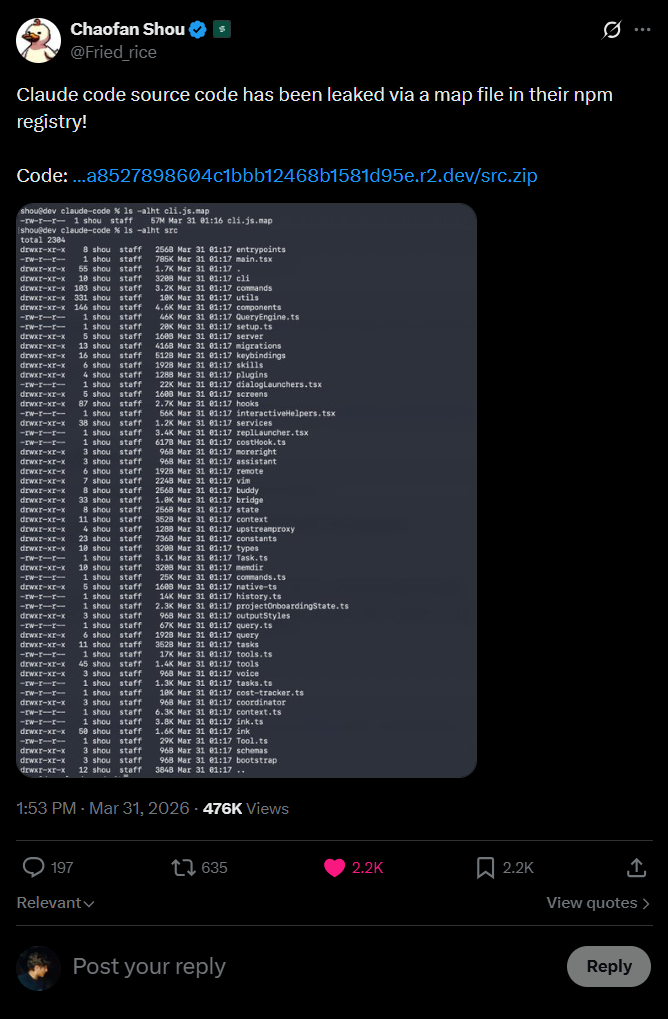
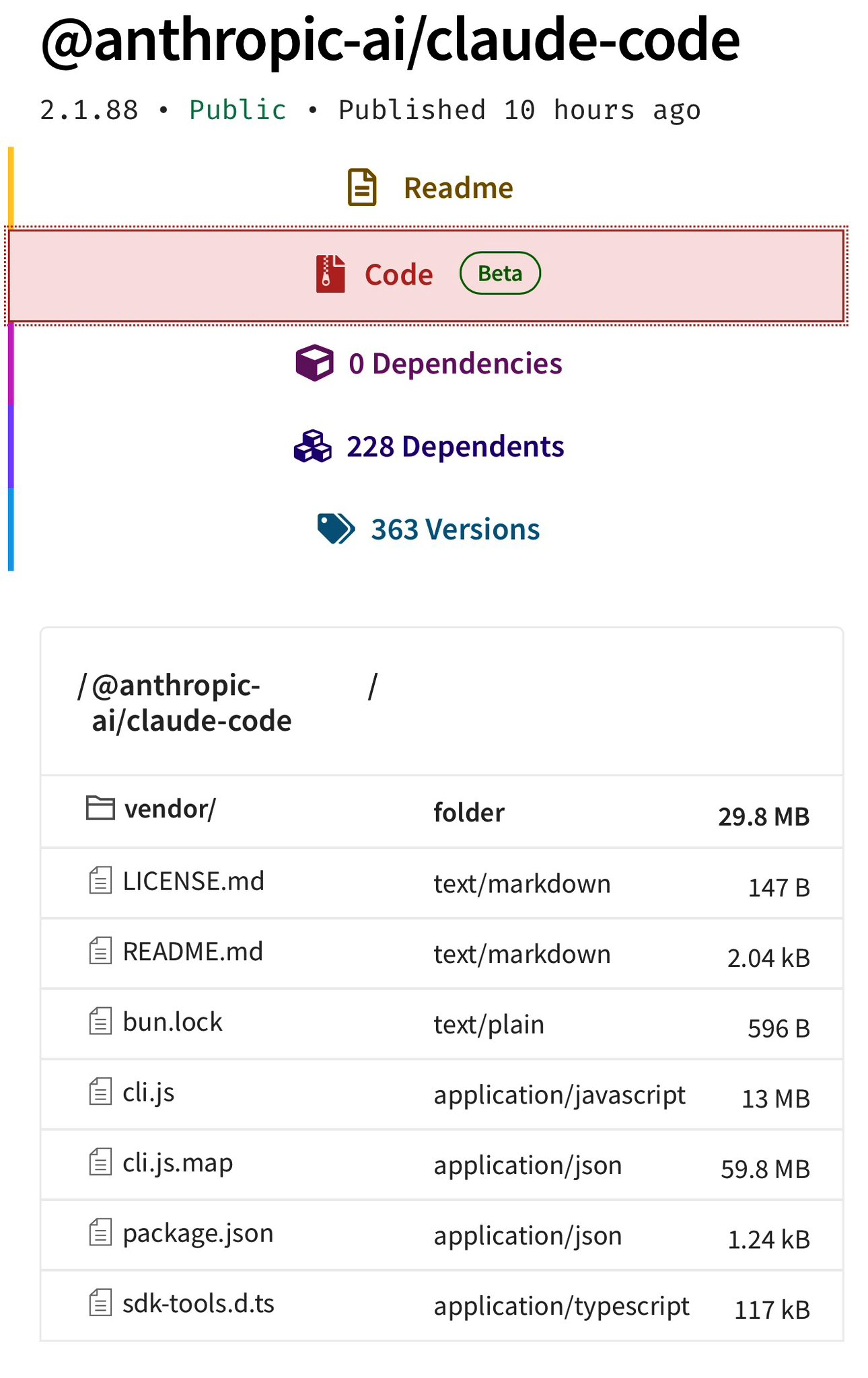
This morning (March 31, 2026), security researcher Chaofan Shou discovered that the entire source code for Claude Code, Anthropic’s official CLI for AI coding, was sitting there for anyone to grab on the public npm registry. 512,000 lines of TypeScript. 1,900 files. All of it exposed through a 59.8 MB source map file accidentally bundled into version 2.1.88 of the @anthropic-ai/claude-code package.
Within hours the code had been mirrored on GitHub, picked apart by thousands of developers, and Anthropic had put out a statement calling it “human error in release packaging, not a security breach.” Which is technically true and ignores that the result is the same.
I use Claude Code every day. Some of the articles you read here, I wrote with it. So I figured I’d take a look at what’s inside. I actually started writing this piece in Claude Code itself, but my Max plan ran out before I finished. I closed the rest in Codex.
How the leak happened
Claude Code is bundled with Bun, the JavaScript runtime Anthropic acquired in late 2024. When you build with Bun, source maps are generated by default. Those .map files contain the full original source code, not just mappings. Every file, every comment, every internal constant, every system prompt.
The initial theory was that a known Bun bug had caused the leak: even with development: false, source maps were still being served and bundled in. But Jarred Sumner, Bun’s creator, shut that down: “This has nothing to do with claude code. This is with Bun’s frontend development server. Claude Code is not a frontend app. It is a TUI. It doesn’t use Bun.serve() to compile a single-file executable.” In other words, the Bun bug affects the frontend dev server, not the build process that generated the Claude Code npm package.
What actually happened is simpler: somebody at Anthropic forgot to add *.map to .npmignore or didn’t configure the bundler to skip source map generation in production builds. And worse: according to The Register, the source map didn’t just point to the original files, it referenced a ZIP hosted on Anthropic’s own Cloudflare R2 bucket. npm happily served it to anyone running npm pack, and the rest was mirroring work.
The irony is that the code contains a whole system called “Undercover Mode” built specifically to prevent Anthropic’s internal information from leaking in commits and PRs. They built a subsystem to stop the AI from revealing internal codenames, and then a source map exposed everything.
What’s inside: the hidden features
The source code reveals 44 feature flags covering functionality that’s ready but not yet shipped. This isn’t vaporware. It’s real code hiding behind flags that compile to false in external builds. Let me highlight the most interesting ones.
KAIROS: a Claude that never stops
Inside the assistant/ directory, there’s a mode called KAIROS, a persistent assistant that doesn’t wait for you to type. It observes, logs, and acts proactively on things it notices. Maintains append-only daily log files, receives <tick> prompts at regular intervals to decide whether to act or stay quiet, and has a 15-second budget: any proactive action that would block the user’s workflow for more than 15 seconds gets deferred.
KAIROS-exclusive tools: SendUserFile (sends files to the user), PushNotification (push notifications), SubscribePR (monitors pull requests). None of this exists in the public build.
BUDDY: a Tamagotchi in the terminal
I’m not making this up. Claude Code has a complete pet companion system in the Tamagotchi style called “Buddy.” A deterministic gacha system with 18 species, rarity, shiny variants, procedurally generated stats, and a “soul” written by Claude on the first hatch.
The species is determined by a Mulberry32 PRNG seeded by the hash of the userId. Same user always gets the same buddy. There are 5 stats (DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK), 6 eye styles, 8 hat options, and sprites rendered as 5-line ASCII art with animations. The code references April 1-7, 2026 as the teaser window, with full launch slated for May 2026.
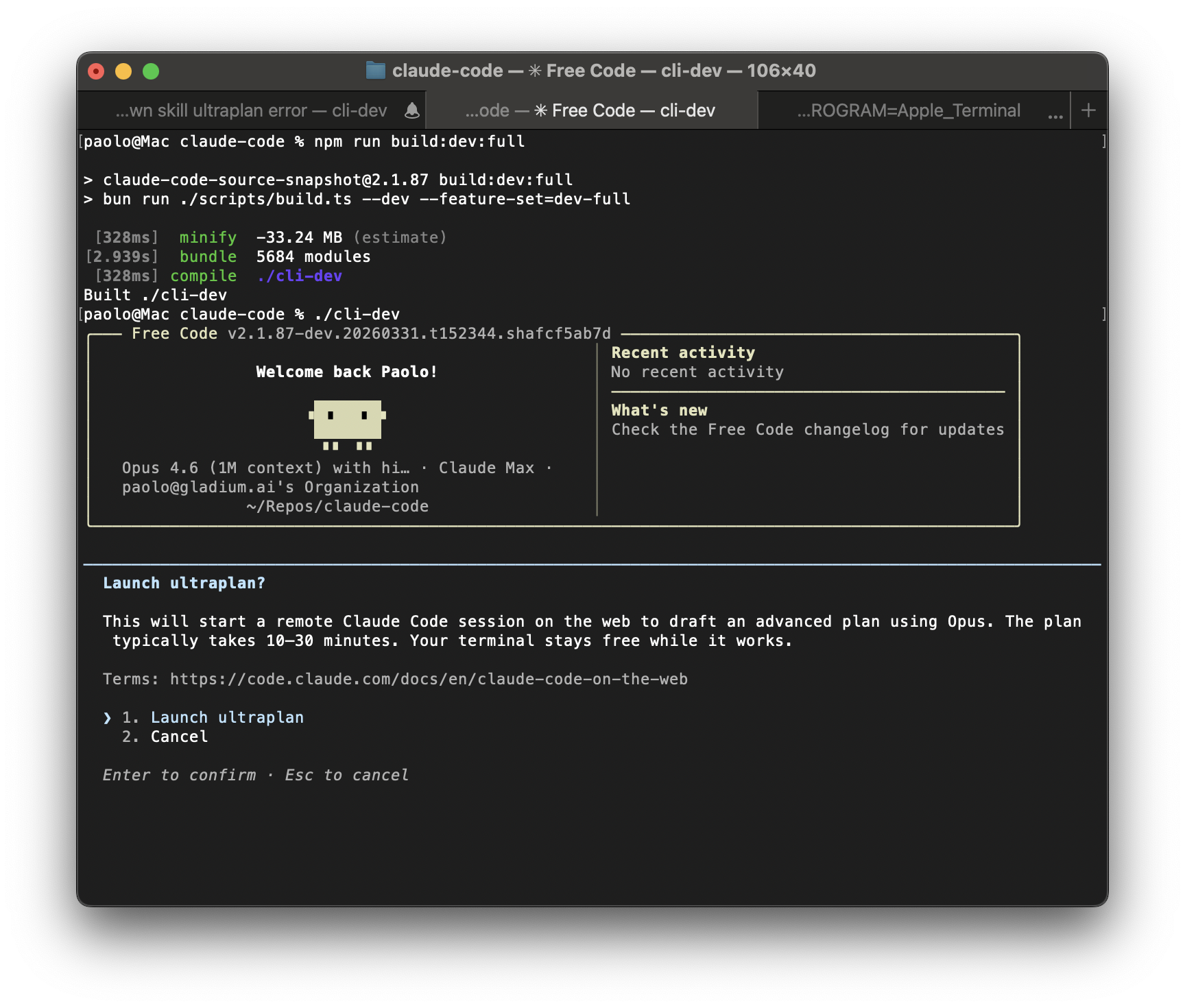
ULTRAPLAN: 30 minutes of remote planning
ULTRAPLAN offloads complex planning tasks to a remote session running Opus 4.6, gives it up to 30 minutes to think, and lets you approve the result through the browser. The terminal shows polling every 3 seconds, and once approved, a sentinel value __ULTRAPLAN_TELEPORT_LOCAL__ “teleports” the result back into the local terminal.
Multi-Agent: “Coordinator Mode”
The multi-agent orchestration system in the coordinator/ directory turns Claude Code from a single agent into a coordinator that spawns, directs and manages multiple workers in parallel. Parallel research, synthesis by the coordinator, implementation by workers, verification by workers. The prompt teaches parallelism explicitly and forbids lazy delegation: “Do NOT say ‘based on your findings’ - read the actual findings and specify exactly what to do.”
And there’s more. The leak also shows in-process teammates with AsyncLocalStorage to isolate context, workers in separate processes via tmux/iTerm2 panes, memory synchronization between agents, and flags ready for BRIDGE_MODE, VOICE_MODE, WORKFLOW_SCRIPTS, AFK mode, advisor-tool and history snipping. None of that guarantees a launch, but it suggests a roadmap that’s a lot further along than the public version lets on.
The memory architecture
The memory system caught my eye. It’s not a “store everything and retrieve” approach. It’s a three-layer architecture:
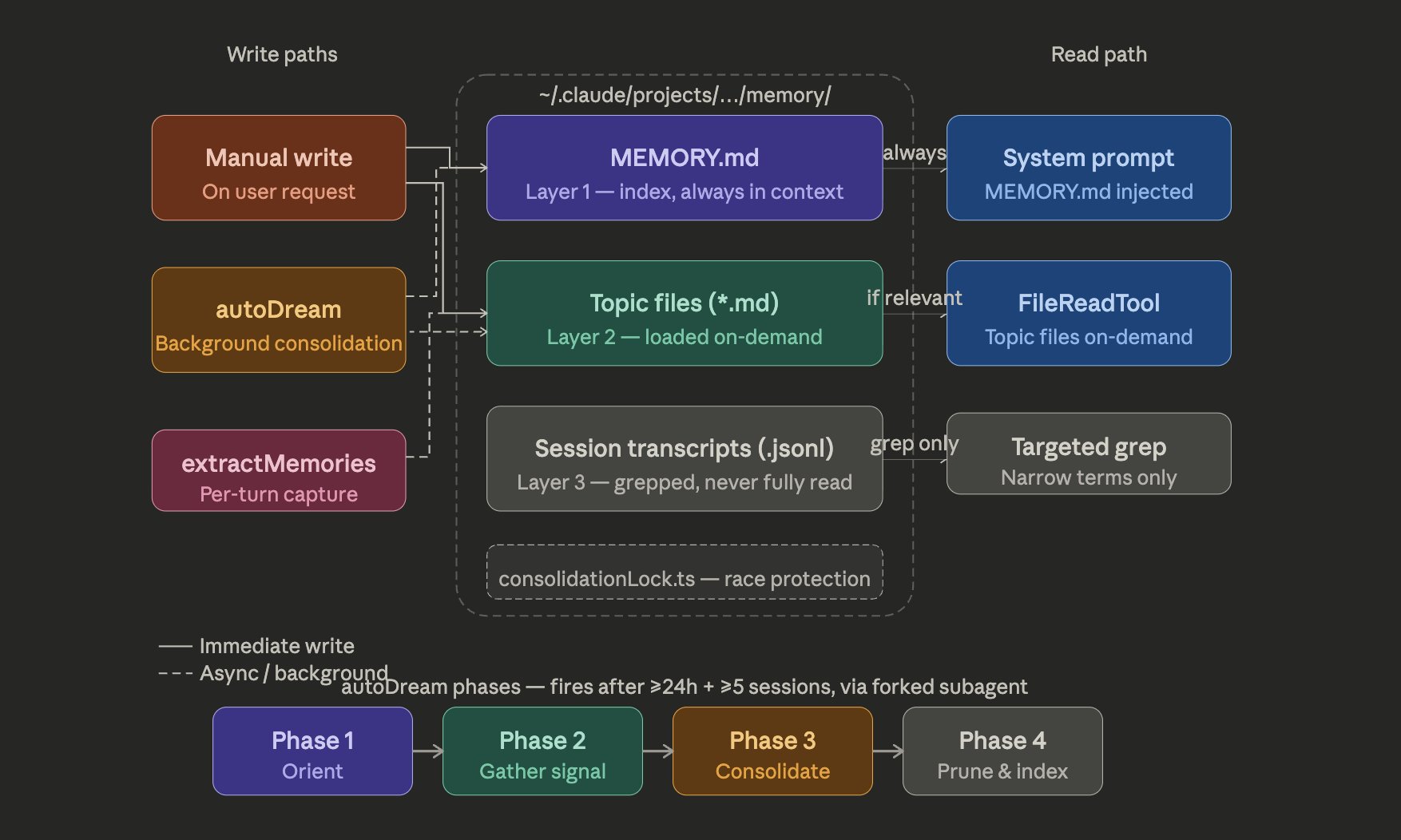
MEMORY.md is a lightweight pointer index (~150 characters per line) that stays permanently loaded in the context. It doesn’t store data, it stores locations. The actual knowledge lives distributed across “topic files” fetched on demand. Raw transcripts are never reloaded into the context whole, only searched with grep for specific identifiers.
And it comes with an important discipline: the system writes to the topic file first and only then updates the index. MEMORY.md doesn’t become a fact dump. It stays a map. If you let the index turn into storage, it pollutes the permanent context and degrades the whole system.
The “Dream” system (services/autoDream/) is a memory consolidation engine that runs as a background subagent. The name is intentional. It’s Claude dreaming.
The dream has a three-gate trigger: 24 hours since the last dream, at least 5 sessions since the last dream, and acquiring a consolidation lock (preventing concurrent dreams). All three have to pass.
When it runs, it follows four phases: Orient (ls in the memory directory, read the index), Gather (look for new signals in logs, stale memories, transcripts), Consolidate (write or update topic files, convert relative dates to absolute, delete contradicted facts), and Prune (keep the index under 200 lines and ~25KB).
There are four memory types: user (user profile), feedback (corrections and confirmations), project (context about ongoing work), reference (pointers to external systems). The taxonomy explicitly excludes things derivable from the code (patterns, architecture, git history, file structure).
The dream subagent gets read-only bash. It can look at the project but can’t modify anything. It’s purely a consolidation pass.
And there’s another detail I found elegant: memory isn’t treated as truth. It’s treated as a hint. The system assumes that memory may be stale, wrong or contradicted, so the model still has to verify before trusting it. That’s the opposite of the fantasy of “throw everything in a vector database and let the magic happen.”
“Undercover Mode”
Anthropic employees (identified by USER_TYPE === 'ant') use Claude Code on public and open source repositories. Undercover Mode (utils/undercover.ts) prevents the AI from accidentally revealing internal information in commits and PRs.
When active, it injects into the system prompt:
## UNDERCOVER MODE - CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. Your commit
messages, PR titles, and PR bodies MUST NOT contain ANY Anthropic-internal
information. Do not blow your cover.
NEVER include in commit messages or PR descriptions:
- Internal model codenames (animal names like Capybara, Tengu, etc.)
- Unreleased model version numbers (e.g., opus-4-7, sonnet-4-8)
- Internal repo or project names
- Internal tooling, Slack channels, or short links
- The phrase "Claude Code" or any mention that you are an AI
- Co-Authored-By lines or any other attributionThere’s no way to turn it off. If the system isn’t sure it’s in an internal repository, it stays in undercover mode. That confirms something kind of uncomfortable: Anthropic uses Claude Code to contribute to open source, and the agent is instructed to hide that it’s an AI.
The internal codenames are animal names: Tengu (codename for the Claude Code project), Fennec (Opus), Capybara, Numbat (in testing). “Fast Mode” is internally called “Penguin Mode” with endpoint claude_code_penguin_mode and kill-switch tengu_penguins_off.
The most paranoid parts
There’s a piece of the analysis I almost missed because I was looking more at the hidden features. But maybe the most revealing thing about Anthropic’s mindset is in the defense mechanisms against copying and abuse.
According to Alex Kim’s analysis, there’s an anti-distillation mode that can ask the server to inject fake tools into the system prompt. The idea is to poison traffic recorded by anyone trying to distill Claude Code’s behavior to train a competitor. There’s also a second mechanism for summarizing connector text, cryptographically signed, so that part of the observable traffic doesn’t match the original raw reasoning. It’s not perfect protection. It’s another layer of friction. But it shows the company is explicitly thinking about copy-by-observation, not just traditional security.
And there’s the more aggressive part: client attestation. Every request includes a billing header with a placeholder cch=00000, and the Bun native runtime replaces that with a hash computed below the JavaScript layer. In other words, looking like Claude Code isn’t enough. The binary tries to prove that it is Claude Code. That helps explain why the fight with third-party tools like OpenCode got so sensitive: it wasn’t just a commercial or legal issue. There was technical enforcement built into the transport.
Update: the DRM died in less than 24 hours
Remember when I mentioned client attestation as “the most aggressive part”? Yeah. It lasted less than a day.
For context: Anthropic had been waging a war against third-party tools since January 2026. First came the server-side blocking of OAuth tokens from non-official clients. Then in March, the OpenCode maintainer merged a PR removing all Claude authentication from the project. The commit message was two words: “anthropic legal requests.” The Register reported that Anthropic updated its terms of service to make it explicit that OAuth tokens from Pro/Max subscriptions can only be used in the official Claude Code and on Claude.ai. People paying $100-200/month for Max who wanted to use the tool of their choice were left holding the bag.
The technical mechanism behind the block was the cch= header. With the leaked code you can see the system has two parts. The first is a version suffix: the cc_version field includes 3 hex characters derived from the user’s first message via SHA-256, using a 12-character salt embedded in the JavaScript. The second is the body hash itself: the entire body of the request (messages, tools, metadata, model, thinking config, everything) is serialized as compact JSON with the cch=00000 placeholder, then hashed with xxHash64 using a fixed seed. The result is masked with 0xFFFFF (20 bits) and formatted as 5 lowercase hex characters. The placeholder is replaced with the computed hash before the request leaves the process.
The detail that makes the difference: that substitution happens inside the Bun native runtime, written in Zig, below the JavaScript layer. Bun literally mutates the JavaScript string in-place, overwriting the 00000 bytes in the string buffer with the computed hash. If you ran the same bundle in Node or in a stock Bun, the placeholder would go to the server as-is and the request would be rejected.
And then the leak happened. With the source code exposed, @StraughterG (Jay Guthrie) announced that same night: “Yesterday I said Anthropic’s compiled Zig cch= hash was banning 3rd-party Claude clients. Tonight, the DRM is dead. We extracted the algorithm from the binary. It’s not advanced cryptography. It’s a static xxHash64 seed.”
The seed is 0x6E52736AC806831E. The full algorithm, as he explained in a thread of tweets, fits in a few lines of TypeScript:
import xxhash from "xxhash-wasm";
const { h64Raw } = await xxhash();
const body = JSON.stringify(request); // com cch=00000 no placeholder
const hash = h64Raw(new TextEncoder().encode(body), 0x6E52736ACn | (0x806831En << 32n));
const cch = (hash & 0xFFFFFn).toString(16).padStart(5, "0");
// substituir cch=00000 por cch={valor calculado}
@paoloanzn celebrated: “we cracked it. the cch= signing system in claude code is fully reverse engineered.” And he immediately put the bypass in free-code, a fork of Claude Code with telemetry removed, system prompt guardrails stripped, and all 54 experimental feature flags unlocked.
The technical point that matters: xxHash64 is not cryptography. It’s a checksum hash designed for speed, not security. The seed is static, embedded in the binary. It changes with each version of Claude Code, but within a version it’s the same for everyone. The “security” depended entirely on nobody being able to extract the seed from the compiled Zig binary. With the source code leaked, that obscurity evaporated in hours.
Now any third-party client — OpenCode, Claw-Code, whatever — can intercept the fetch(), hash the body with the correct seed, and pass the server’s validation as if it were the official Claude Code. The barrier Anthropic built to protect its $2.5 billion ARR business model was, in the end, security by obscurity over a non-cryptographic hash.
The third detail is small but says a lot about real product in production: the system detects user frustration with regex. Yes, regex. Profanity, insults, “this sucks,” that kind of thing. It’s funny to see an LLM company doing sentiment analysis with wtf|ffs|shit, but it’s also the kind of pragmatic solution you reach for when you need a cheap immediate answer, not conceptual elegance.
What the code reveals about how you use Claude Code
@iamfakeguru compiled a thread with seven technical findings from the code that any user should know:
Claude Code has a 2,000-line cap per file read. When you ask it to read a larger file, it silently truncates. Tool results are cut off at 50,000 characters. The context window compression system drops old messages to fit more new context. And there’s a difference between the access level of Anthropic employees (USER_TYPE === 'ant') and public access: internal tools like ConfigTool and TungstenTool are invisible in the external build.
The most useful finding from the thread is how Anthropic employees work around the limitations external users face. The code reveals that USER_TYPE === 'ant' unlocks internal tools, exclusive beta headers (cli-internal-2026-02-09), access to staging (claude-ai.staging.ant.dev), and a ConfigTool that lets you change configurations at runtime. External builds compile all of this to false via dead code elimination.
But the point that matters is: the CLAUDE.md you put at the root of your project gets read in full by Claude Code and injected into the system prompt. It’s literally the place where you control how the agent behaves. @iamfakeguru published a complete override with 10 mechanical rules, and then put the whole file in a separate repository: iamfakeguru/claude-md.
I’m not going to paste the whole block here. What matters is the content: it forces post-edit verification (tsc and eslint before declaring success), it imposes re-reading files before editing, it requires reading large files in chunks, it assumes silent truncation of long results, and it tells you to break larger work into phases or parallel subagents. In other words: it turns into explicit rules everything that external users were having to figure out empirically.
These aren’t magic instructions. They’re guardrails. The difference is that now we know which limits the system actually has and we can write a CLAUDE.md that works with them, not against them.
Cache bugs that cost real money
@altryne (Alex Volkov) reported cache invalidation bugs that make uncached tokens cost 10-20x more than cached ones. There are two bugs: a string substitution bug in Bun that affects the standalone CLI (workaround: use npx @anthropic-ai/claude-code instead of the installed binary), and another in the --resume flag that breaks the cache with no known workaround. Over 500 users reported similar quota exhaustion issues. If you’ve been feeling like Claude Code was burning tokens faster than expected over the past few days, it probably wasn’t your imagination.
“Staff engineer spaghetti”
The code analysis revealed real problems. A comment in the source itself admits: “1,279 sessions had 50+ consecutive failures (up to 3,272) in a single session, wasting ~250K API calls per day globally.” The fix was three lines: limit consecutive failures to three before disabling compaction.
The print.ts file has 5,594 lines with a single 3,167-line function containing twelve levels of nesting. main.tsx is 803,924 bytes in a single file. interactiveHelpers.tsx is 57,424 bytes. These are files no human can review with confidence.
The most viral reaction came from @thekitze: he asked GPT-5.4 to evaluate the codebase and the score came in at 6.5/10. The description: “This is not junior spaghetti. This is staff-engineer spaghetti: performance-aware, feature-flagged, telemetry-instrumented, surgically optimized spaghetti.” In other words, it isn’t bad code from inexperience. It’s bad code from pressure to ship fast without paying the cost of cleaning up afterwards.
@thekitze also elaborated in another thread on how the code shows a lack of basic engineering practices. And this is where I feel vindicated.
I’ve been repeating in several posts on vibe coding that speed without discipline produces exactly this. The principles I defend, small increments, tests at every step, review before committing, continuous refactoring, CI that rejects high cyclomatic complexity, are the same Extreme Programming principles that have worked since the early 2000s. Anthropic apparently didn’t follow any of them on their own product.
A 3,167-line function with 12 levels of nesting isn’t something that appears overnight. It’s accumulation. It’s the result of dozens of additions where nobody stopped to refactor because “it works, don’t touch it.” It’s the classic anti-pattern of vibe coding without discipline: generate code with AI, see that it compiles, commit, repeat. Without rigorous review. Without complexity limits in CI. Without the basic rule that if a function passes 50 lines, it needs to be broken up.
The irony is that Anthropic sells the most popular vibe coding tool on the market and doesn’t practice what I call responsible vibe coding. Claude Code is worth $2.5 billion in ARR. The code that generates that revenue is rated 6.5/10.
The “clean room” question
With the entire source code public, there’s a serious legal and competitive implication. And here I think a lot of people started using the term “clean room” with a lightness that doesn’t fit the subject.
A real clean room isn’t just “I rewrote it in another language” or “I didn’t copy and paste.” The classic model is much more annoying: one group studies the original and produces a functional spec; another group, isolated, implements from that spec without ever seeing the original code. The whole point is to reduce contamination risk.
@braelyn_ai raised another interesting point: with generative tools, somebody could try a “clean room rebuild” using tests, observable behavior and documentation, without reusing the original implementation. In theory, that makes sense. In practice, what shows up in the heat of a leak usually lands in a much grayer zone.
The Claw-Code case illustrates this well. The project presents itself as an independent rewrite and has already shifted focus to Python and Rust, but the README itself admits direct study of the exposed code and even mentions a parity audit against a local archive. So I wouldn’t call that a clean room in the strictest classic sense. I’d call it an inspired reimplementation, with a deliberate attempt to move away from the leaked snapshot.
That doesn’t mean every reimplementation is doomed. Software copyright doesn’t protect abstract ideas, generic tool flow, high-level architecture or “a CLI that does X.” It protects concrete expression. But that’s exactly why discipline matters. The more a project wants to maintain independence, the less it should rely on the leaked material as a direct benchmark.
There’s a more pragmatic detail in there: the literal copies of the leaked source will probably disappear quickly when the first DMCAs start arriving. Mirrors fall easily. That’s why a reimplementation matters more than a raw mirror. It doesn’t erase the legal discussion, but it changes the type of fight quite a bit and the chances of staying online.
That’s more or less what I did myself when I rewrote OpenClaw in Rust. The point wasn’t to copy line by line. It was to understand the behavior and rewrite the whole piece in my own code.
The satirical site malus.sh appeared today offering “Clean Room as a Service” with the tagline “Robot-Reconstructed, Zero Attribution.” The joke: AI robots recreate open source projects eliminating attribution obligations, with guarantees like “This has never happened because it legally cannot happen. Trust us.” and indemnification via an offshore subsidiary in a jurisdiction that doesn’t recognize software copyright. It’s satire, but it’s satire that describes what someone is going to actually try to do.
Update on April 2, 2026
Since the text above opens in the heat of March 31, it’s worth recording what happened right after. I decided to add this update after reading this tweet from @k1rallik, which captures the post-leak mood well but mixes verifiable facts with a touch too much epic.
First: the DMCA part got messier than it looked. The notice itself published in the github/dmca repository says GitHub processed the takedown against the entire network of 8,100 repositories, because the notification claimed that “all or most of the forks” were infringing to the same extent as the main repository. The next day, Anthropic published a partial retraction: it asked for the reinstatement of all the removed repositories, except nirholas/claude-code and 96 forks listed individually. So the thesis that the initial attempt was too broad is correct. The final picture, however, isn’t “8,100 repositories were taken down.” What happened was a formal walk-back after the mass removal.
Second: the Claw-Code project really did blow up. By the time I was updating this post, GitHub was already showing 142,829 stars and 101,510 forks. That alone is enough to say the story has moved out of the “curious fork of the leak” category and into the “real competitive side effect” category. The viral tweet that went around today is right about the size of the damage but exaggerates some details. The project’s own README describes itself as “the fastest repo in history to surpass 50K stars” and says the milestone came in two hours. I couldn’t independently confirm that historical record, so I’d rather treat that as the project’s own claim, not as a settled fact.
Third: the Rust part also needs nuance. Yes, there’s already a Rust workspace on the main branch and the Cargo.toml is at version 0.1.0. But I couldn’t find a public release on GitHub to support the line “release 0.1.0 already shipped” as a formal launch. What I can say with confidence is something else: the project already has a Python base, already has a Rust workspace, and has already drawn enough attention to keep existing even without the literal mirror of the leaked code.
What Anthropic should have done
Anthropic responded fast. They pulled the compromised package, put out a public statement, and cleaned up what they could. But the damage was done. The code was mirrored before the takedown. Mirrors on GitHub, analyses in blogs, threads on X/Twitter. There’s no way to un-publish something on the internet.
What bothers me isn’t the leak itself. Bugs happen. What bothers me is that this was avoidable with basic engineering practices:
- Add
*.mapto.npmignore. One line. - Configure the bundler to not generate source maps in production builds. One flag.
- Have a CI check that rejects publication if the package contains
.map. A 5-line script. - Have a release pipeline with manual review before publishing to npm. Process, not code.
None of these are hard. They’re all the kind of thing that gets dropped when you’re moving too fast and don’t have discipline in the release process. It’s exactly what I preach as disciplined vibe coding: moving fast doesn’t mean skipping the guardrails.
And the second failure: the quality of the code itself. 512,000 lines with 3,000-line functions and 12 levels of nesting isn’t engineering. It’s accumulation. It’s what happens when you generate code with AI without rigorous review, without continuous refactoring, without CI that rejects high cyclomatic complexity. The irony of being precisely the company that sells the most popular vibe coding tool in the world doesn’t go unnoticed.
Sources
- Kuberwastaken/claude-code - Complete breakdown of the leaked code
- Alex Kim - Claude Code Source Leak: fake tools, frustration regexes, undercover mode
- VentureBeat - Claude Code’s source code appears to have leaked
- The Register - Anthropic accidentally exposes Claude Code source code
- Fortune - Anthropic leaks its own AI coding tool’s source code
- Cybernews - Full source code for Anthropic’s Claude Code leaks
- Gizmodo - Source Code for Anthropic’s Claude Code Leaks at the Exact Wrong Time
- Anthropic - Anthropic acquires Bun as Claude Code reaches $1B milestone
- Bun Issue #28001 - Source maps incorrectly served in production
- Hacker News - Claude’s system prompt is over 24k tokens with tools
- malus.sh - Clean Room as a Service (satire)
- @iamfakeguru - Thread with 7 technical findings from the code
- @altryne - Cache bugs that cost 10-20x more
- @thekitze - “Staff-engineer spaghetti” 6.5/10
- @braelyn_ai - Clean room and legal implications
- GitHub DMCA - Anthropic takedown notice processed against the network of 8.1K repositories
- GitHub DMCA - Anthropic’s partial retraction the next day
- ultraworkers/claw-code - Python and Rust reimplementation that became the main post-leak project
- @mem0ai - Analysis of the memory architecture
- @himanshustwts - Memory architecture summary
- iamfakeguru/claude-md - Override published with the complete CLAUDE.md
- @StraughterG - “the DRM is dead” - reverse engineering of the cch= hash
- @StraughterG - xxHash64 seed and TypeScript bypass code
- @paoloanzn - “we cracked it” - confirmation of the reverse engineering
- paoloanzn/free-code - Fork of Claude Code with telemetry removed and features unlocked
- a10k.co - What’s cch? Reverse Engineering Claude Code’s Request Signing
- The Register - Anthropic clarifies ban on third-party tool access to Claude