Teaching People to Question the News | Frank Investigator
Heads up: Frank Investigator is an experimental project, in active development, and isn’t meant to be the final word on any article it analyzes. It doesn’t tell you what’s true or false. What it does is ask the questions the article refused to ask, identify known rhetorical patterns, and search for external sources the author left out. If you want to help, contribute on GitHub or send feedback. If you want to follow the results, The Makita Chronicles newsletter is going to have a new section called “Notícias Duvidosas” (Dubious News) where I’ll publish the investigator’s summary and a link to the full report.
With that out of the way, let me explain why I built this.
The problem with the Brazilian press
I’m fed up.
Fed up of opening the newspaper and having to do mental gymnastics to separate information from narrative. Fed up of outlets like Folha de São Paulo, UOL, Carta Capital, Brasil 247, O Globo and several others that use misleading headlines, omit context on purpose, transpose evidence from other countries with no caveat, and create the appearance of consensus among outlets that are all saying the same thing because they’re following the same coordinated agenda.
This isn’t conspiracy theory. It’s a verifiable editorial pattern. And the worst part: most readers don’t have the time or the tools to notice. You read the headline, read the first two paragraphs, and walk away with the impression the article planted in your head.
What Frank Investigator does
You give it a news article URL. The system fetches the article with a headless Chromium (to get past paywalls and cookie walls), extracts the content while filtering out ads and sidebars, and decomposes the text into verifiable claims. Then the real analysis starts: divergence between headline and body, rhetorical fallacies (false causality, appeal to authority, strawman, bait-and-pivot), source distortion, temporal manipulation, selective citation, authority laundering. It expands the links cited in the article to verify whether the sources actually say what the author claims. It evaluates each claim with consensus from 3 AI models (Claude Sonnet 4.6, GPT-5.4, Gemini 3.1 Pro) through OpenRouter. It detects contextual gaps, coordinated campaigns across outlets, and measures the ratio between passion and evidence. 15 stages in total.
The central principle is “Truth Above Consensus”: a primary source (official data, government document, original academic study) vetoes any number of secondary sources repeating the same information. Ten newspapers repeating the same thing without a primary source still adds up to zero.
Let me show you five real examples.
Example 1: The Noelia Castillo case (BBC)

The BBC published a story with the headline “Noelia Castillo dies: a 25-year-old’s fight in the Spanish courts against her father to receive euthanasia.” At first glance it looks like a story about the right to euthanasia and a family dispute. A young quadriplegic woman who fought against her religious father’s opposition to exercise her right to die.
Except when you compare it with other outlets, like Veja, facts come up that the BBC almost completely omitted. And those facts change everything.
Noelia was taken from her family by the Spanish government at age 13 and placed under state custody. While she was under that custody, she suffered multiple gang rapes. The sexual violence resulted in serious psychiatric damage and a mental health history that already added up to 67% disability rating before the events of 2022. When she attempted suicide in October 2022 by jumping from the fifth floor of a building, she was left paraplegic. Her disability rating rose to 74%.
The euthanasia request was approved by Catalonia’s Guarantee and Evaluation Commission. The procedure was scheduled for August 2, 2024, but was suspended for over 600 days because of the father’s appeals. Five judicial instances ruled on it. The Constitutional Court dismissed any violation of fundamental rights. Spain’s Supreme Court denied the appeal. The European Court of Human Rights rejected the suspension request. On Friday, March 26, 2026, Noelia underwent euthanasia at the Sant Camil Residential Hospital, in Catalonia’s Garraf region.
But there’s a detail that Veja mentions that’s disturbing: Noelia reportedly expressed doubts before the procedure. And the hospital allegedly accelerated the process because her organs were already committed for donation.
The Frank Investigator report compared the coverage from several outlets.

The cross-analysis of the articles showed that some outlets, like the BBC, omitted facts that change the interpretation of the entire case. Others, like Veja, included the full context. The episode of gang sexual violence in October 2022, the criminal investigation, the psychiatric history since age 13, all of that appears in some coverage but is completely absent in others. And among the outlets that omitted these facts, none touched on the ethical question of whether the physical basis for the euthanasia request derives from a suicide attempt.
The convergent framing across outlets is one of “judicial battle,” “death she asked for,” “to stop suffering,” “to leave in peace,” softening the definitive nature of the procedure and positioning Noelia as the heroic protagonist and the father as the obstructive antagonist. The father, Gerônimo Castillo, and his Christian Lawyers are labeled “ultra-Catholics” or “ultra-conservatives” without any independent source backing that editorial classification.

Narrative coordination came in at 55%. It doesn’t seem to be active coordination between newsrooms, but thematic editorial alignment: everyone bought the autonomy-of-the-individual narrative without questioning it. What raises the score is the convergence of omissions. No outlet explains the legal distinction between the ECHR “actively authorizing” the euthanasia and simply refusing the provisional protective measures the father requested, which is what actually happened. The medical and bioethical implications of approving euthanasia in a case stemming from a suicide attempt show up nowhere. And any voice critical of the procedure is automatically framed as religious or ideological, never as medical or legal.
It’s the kind of case where the omission is the manipulation. The outlets that omitted these facts didn’t lie at any point. But by framing it as a “family dispute over euthanasia rights” and omitting the causal chain (state custody → gang rapes → psychiatric damage → suicide attempt → paraplegia → euthanasia), the reader walks away with an impression that’s radically different from reality. Comparing coverage is exactly the kind of thing the investigator does well: exposing what each outlet chose to show and what it chose to hide.
Example 2: “Government cuts taxes on nearly a thousand imports” (UOL)

UOL published that the government cut import taxes on nearly a thousand products, from medicine to hops. Positive headline, framed as a benefit to the consumer. Several other outlets ran the same thing with similar framing: the government did something good, prices are going down.
Except Gazeta do Povo tells the other half of the story. The government didn’t cut old taxes. What actually happened was: at some point before February 2025, the government raised import tariffs on more than 1,200 items, a measure that would have generated an estimated R$ 14 billion in revenue. Then, under social-media and public pressure, it partially backed down. Tariffs on around 970 capital goods, computing and telecommunications items were dropped to zero. Taxes on 120 IT products were reduced. And now they’re calling that a “tax cut.”
In other words: they raised taxes, took public pressure, partially walked it back, and rebranded it as a generous concession. The majority of the 1,200+ items that had tariffs raised still have higher tariffs than before. No final consumer prices went down. Prices went back to where they were for some products, and remain higher for most.
The Frank Investigator report cross-checked the articles and exposed what was omitted.

What the comparison between articles exposes: none of the outlets with the positive framing mentions that most of the 1,200+ items with raised tariffs still have higher tariffs after the two rounds of “cuts.” The fiscal impact on the R$ 14 billion revenue target from the original increases — nobody calculates it. Voices from the domestic industry that may be hurt by the tariff reduction on imported competitors — none. The Gecex’s objective criteria for defining “insufficient supply in the internal market” — they don’t show up.
The two articles analyzed build the same positive framing for the government. The paradox that the “cuts” are a partial reversal of increases made by the same government the previous year stays buried or simply absent.
It’s the classic kind of manipulation through reframing. Nobody lied. But “government cuts taxes” and “government backs down on tax hike after public pressure” describe the same event with opposite impressions. The editorial choice of which version to publish IS the manipulation.
Example 3: “Globo apologizes for PowerPoint” (Brasil 247)

This case blew up over the past few days. GloboNews showed a diagram on the Estúdio I program connecting President Lula, his ministers and Daniel Vorcaro, owner of Banco Master, who’s at the center of documented fraud. Globo later issued a public retraction, called the material “erroneous and incomplete,” and fired an editor.
Brasil 247 published a story with the headline “Globo apologizes for PowerPoint that tried to dump the Master case on Lula’s lap.”
The Frank Investigator report exposed what’s going on under the hood:

The central fact is real: Globo apologized and fired someone. But Brasil 247’s framing goes way beyond what the facts support. The headline saying “tried to dump it on Lula” attributes deliberate intent where the documents point to an editorial mistake. Globo’s retraction described the material as “erroneous and incomplete,” not as an attempt to incriminate anyone.
What stands out in this case is the coordinated campaign. The investigator gave it 62% narrative coordination.

Several outlets editorially aligned with the government used the phrase “without evidence” in a convergent way to describe the association between Lula and the Master case. All of them focused on Globo’s mistake as the central narrative point, instead of investigating the actual connections. No outlet mentioned which other political names were excluded from the original PowerPoint. None investigated Vorcaro’s documented connections with different spheres of power. The focus is meta-journalistic: they criticize the broadcaster instead of covering the scandal.
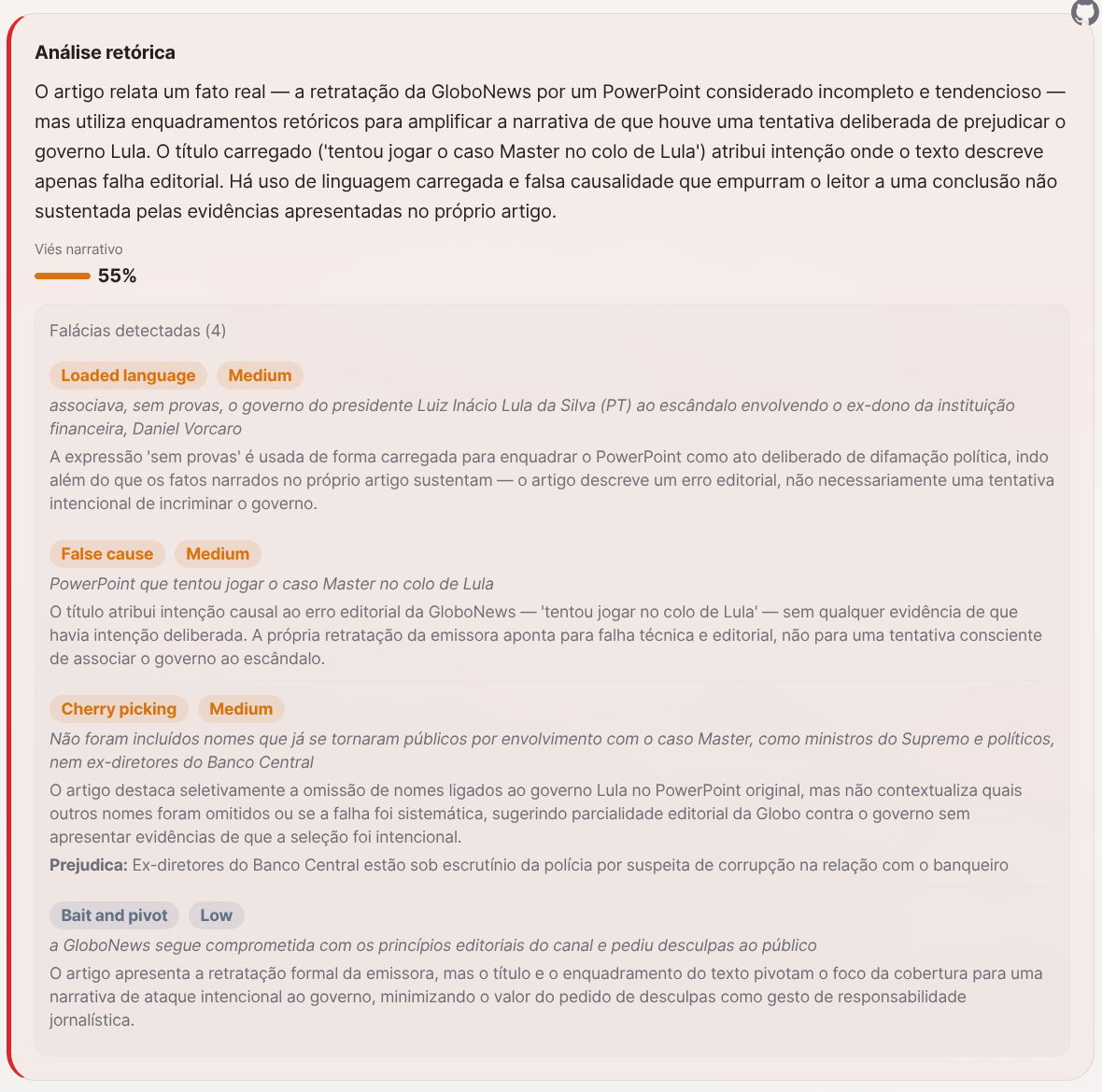
The fallacies detected: loaded language (“tried to dump,” “without evidence” used to frame an editorial mistake as a deliberate political attack), false causality (Globo’s retraction doesn’t prove the connections are false), cherry-picking (highlights the omission of names tied to the Lula government without contextualizing which other names were omitted), and bait-and-pivot (uses Globo’s apology as a hook to minimize the Banco Master scandal).
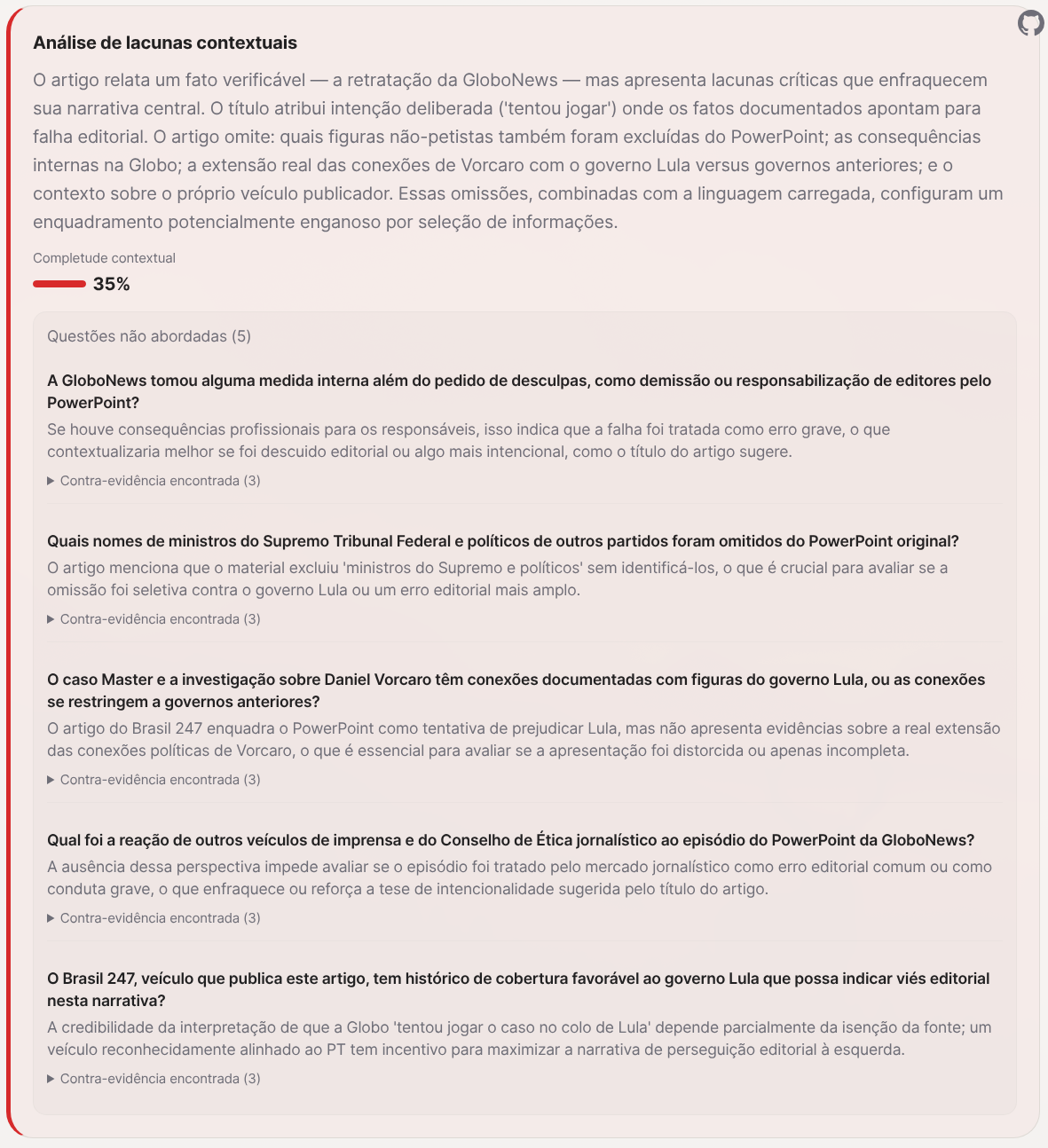
And the questions none of these outlets asked: which Supreme Court justices and politicians from other parties were also excluded from the PowerPoint? Does the Master case have documented connections to Lula government figures, or are they limited to previous administrations? Does Brasil 247, which is publishing this article, have a declared editorial alignment with the Lula government? What was the journalism Ethics Council’s reaction?
Overall confidence: 13%. The article doesn’t fabricate facts. But it selects, frames and omits in a way that builds a narrative the data doesn’t support.
Example 4: “Why expensive fuel is good” (Folha)

The economist Bernardo Guimarães published a column on Folha arguing that expensive fuel is good for society because it stimulates innovation in clean energy. He cites real academic articles (Popp 2002, NBER) and has verifiable academic credentials (PhD from Yale, professor at FGV EESP). It looks solid.
The full Frank Investigator report shows another picture.

The article is right to cite real studies. But it omits who pays the bill. The column completely ignores the distributive impact: low-income populations, residents of peripheral and rural areas, who depend more on personal vehicles and have less access to clean alternatives. For an economist, ignoring distributive effects is either incompetence or editorial choice.
There’s a worse problem. The empirical evidence he cites (US patents, electric vehicle data in California between 2014-2017) is transposed to Brazil with no caveat at all. Brazil has an ethanol matrix and flex-fuel infrastructure that completely changes the causal mechanism. The article treats it as if the Brazilian consumer were in the same situation as the Californian one, which is false.
And there’s the context the article mentions in passing but doesn’t develop: the war in Iran is making fuel prices rise around the world. Brazil should be in a privileged position thanks to the pre-salt and to ethanol. But decades of mismanagement and corruption at Petrobras mean we’re paying the same price as the rest of the world. Instead of questioning that, the column sells the idea that “at least it’ll stimulate clean energy.” It’s a rationalization of a problem that shouldn’t exist.

The investigator identified 5 questions the article refused to address, with 35% contextual completeness. The fallacies detected include false dilemma (presents expensive fuel as the only viable climate policy), cherry-picking (acknowledges short-term inelasticity but emphasizes only long-term effects), and loaded language (describes alternatives as “playing at planting a little sapling”).
Overall confidence: 25%. It isn’t fabricated disinformation. It’s opinion with cherry-picked evidence in favor of the thesis and omission of relevant counterpoints.
Example 5: “There’s no strong cinema without streaming regulation” (O Globo)
Renata Magalhães, president of the Brazilian Academy of Cinema, gave an interview in Miriam Leitão’s column on O Globo arguing that regulating streaming is a necessary condition for strengthening Brazilian cinema.
The Frank Investigator report found serious problems.

First: the central claim that “many films have low audiences” appears with no empirical data. No numbers, no historical series. It’s a pure authority claim with no analytical basis.
Second: there’s an internal contradiction the article doesn’t resolve. The text opens by saying that Brazilian cinema is “in international spotlight” (awards, festivals). And then immediately argues that the absence of regulation prevents the industry from being strengthened. But if Brazilian cinema is already winning international awards without that regulation, the argument that the regulation is a necessary condition collapses. The article doesn’t address that contradiction.
And here’s the elephant in the room that none of these articles mentions: people simply don’t want to watch most of these films. Internationally awarded Brazilian cinema is made to compete in Cannes and at the Oscars, not to fill movie theaters in Brazil. Instead of asking why the Brazilian audience isn’t interested, the industry would rather ask for streaming regulation to force platforms to fund and screen content that has no spontaneous audience. It’s the classic playbook: use public money and regulation to keep alive an industry that doesn’t sustain itself in the market.
The interviewee is the president of the Brazilian Academy of Cinema. She has a direct institutional interest in the regulation. The article doesn’t present any opposing voice and doesn’t discuss the costs to consumers: subscription price increases, catalog reduction. A single source, with a declared conflict of interest, with no counterpoint.

And here comes the coordinated campaign, with 55% narrative coordination. Multiple outlets reproduce the same emotional framing: cinema “at risk,” regulation as “essential.” None of the identified sources discusses comparable empirical international evidence on the effectiveness of content quotas (Europe has experiences with contradictory results). None mentions the Brazilian Academy of Cinema’s conflicts of interest. The fact that the internationally awarded Brazilian productions were made without the proposed regulation is omitted convergently across all outlets. Only one isolated site (targethd.net) mentioned negative impacts on consumers.
Overall confidence: 9%. The article is legitimate editorial advocacy, but with analytical flaws that limit its informational value to nearly zero.
What the investigator analyzes
The 5 examples above show different patterns, but the analysis criteria are the same.
The strongest signal of manipulation is omission. It isn’t what the article says that misleads, it’s what it leaves out. The contextual gap analysis identifies the questions the article should have answered and didn’t, and searches for counter-evidence on each one. In the examples above, articles that omit most of the relevant context aren’t informing anyone. And when cross-comparison between outlets shows that some covered the facts and others didn’t, like in the Noelia case or the tax cut, it’s hard to argue that the omission was accidental.
Then comes the detection of coordinated campaigns. Several newspapers covering the same subject is normal. All of them using the same loaded language, focusing on the same points and omitting the same counterpoints at the same time isn’t. The strongest signal of coordination isn’t what outlets say in common, but what they omit in common.
There’s also reframing, which is more subtle. In the tax case, the government raised tariffs, backed down under pressure, and the outlets called it a “cut.” Nobody lied technically, but the choice of framing completely changes the interpretation. This kind of manipulation is harder to detect because each individual statement is defensible.
The rhetorical fallacies catch specific constructions: false dilemma (“either you regulate or cinema dies”), bait-and-pivot (open with a positive fact and pivot to a crisis narrative), loaded language (“without evidence” used to attribute intent). Each detected fallacy comes with the exact citation of the passage and the explanation of why that construction is problematic.
And there’s the principle that ties it all together: if 10 outlets repeat the same claim citing each other, the LLM consensus has to reflect that the chain of evidence is circular, not that the claim is well supported. Volume of coverage is not a proxy for truth.
Why you can’t “just ask ChatGPT”
The first reaction many people will have is: “why do I need this if I can just paste the article into ChatGPT and ask it to analyze?”
Try it. Take a political article and ask ChatGPT to criticize it. It’ll criticize. Take the same article and ask it to confirm. It’ll find arguments to confirm. The LLM isn’t searching for truth. It’s predicting which response you most likely want to hear given the framing of your question. If you ask “analyze the problems with this article,” the model will find problems. If you ask “is this article correct?”, it’ll find merits. It’s automated confirmation bias.
There’s another problem. General-purpose LLMs are trained to be agreeable. The sycophantic tendency (agreeing with the user) is documented in every large model. If your conversation history indicates you’re left-leaning, the model tends to frame answers in a way that pleases that profile. If you’re right-leaning, same thing in the other direction. It’s not lying on purpose. It’s optimizing for user satisfaction, which is literally the metric it was trained for via RLHF.
And worse: LLMs hallucinate. If they don’t have enough evidence to support the answer they think you want to hear, they invent it. They fabricate plausible citations and data, attribute statements to people who never made them. If you ask it to criticize an article about fuel, it might invent a fictional study that “proves” the opposite of the article. It sounds convincing. But it doesn’t exist.
Frank Investigator was built precisely to avoid these problems. The first design decision is that no human asks the LLM a question. There’s no open-ended prompt like “analyze this article.” Each step in the pipeline has structured prompts that ask for specific analyses: “list the rhetorical fallacies in this passage,” “identify which contextual information is missing,” “compare the headline with the body.” The model doesn’t know whether the operator agrees or disagrees with the article, because the operator never expresses an opinion. That eliminates confirmation bias at the root.
To deal with hallucination, every analyzer that uses an LLM includes the instruction “CRITICAL — NO HALLUCINATION: Only reference URLs, sources, claims, quotes, and data that are EXPLICITLY present in the input provided to you. Do not invent, guess, or fabricate any URL, source name, statistic, quote, or claim. If you cannot verify something from the provided text, mark it as unverifiable — never fill in details.” It doesn’t eliminate hallucination completely, but it cuts it down a lot. And since 3 models from different companies (Anthropic, OpenAI, Google) answer the same questions, when one hallucinates the other two usually disagree. The consensus is weighted by confidence, not by simple majority. If two models say “supported” with 70% confidence and one says “mixed” with 95%, the “mixed” weighs more. The further apart the disagreement, the bigger the penalty on final confidence. If one model starts giving inconsistent answers, it gets put in quarantine and the other two carry on.
But the safeguard I consider most important is the primary source veto. If a primary source (IBGE data, court ruling, original study) contradicts a claim, confidence is capped at 60% and the verdict is forced to “mixed,” even if all 3 LLMs say “supported.” Ten newspaper articles repeating a claim don’t override one official datum that contradicts it. Along the same lines, if 5 stories “confirm” a claim but they all come from the same editorial group (Folha/UOL, Globo/G1/Valor), the system knows they’re the same voice and reduces the weight. Volume doesn’t replace independence.
None of this makes the system perfect. But it’s categorically different from pasting text into ChatGPT and asking “what do you think?”.
The numbers
| Metric | Value |
|---|---|
| Commits | 129 |
| Active days of work | ~9 |
| Lines of Ruby (code) | 19,444 |
| Lines of test code | 9,190 |
| Test files | 108 |
| Total lines (code) | 24,301 |
| Services (analyzers + services) | 80 |
| Misinformation analyzers | 15 |
| ActiveRecord models | 14 |
| Background jobs | 19 |
| Database migrations | 31 |
| Pipeline stages | 15 |
| LLM models in consensus | 3 |
| Locales | 2 (en, pt-BR) |
Stack: Ruby 4.0.1, Rails 8.1.2, SQLite with WAL mode, Solid Queue (jobs inside Puma), Solid Cable (WebSockets), Tailwind CSS v4, headless Chromium via Ferrum CDP, deploy with Kamal to GitHub Container Registry. AGPL-3.0.
The development process
The project has 129 commits in 9 active days of work (March 11-16 and 25-27). The first day was the heaviest: more than 60 commits on March 11 alone, going from zero to a working system with content extraction, claim decomposition, LLM evaluation, and a web interface with live updates via Turbo Streams.
The commits tell the story. It started with the foundation:
1e32d5a - Initial Frank Investigator foundation
564eb97 - Add recursive source crawling and RubyLLM scaffold
c8c5357 - Add Brazil source registry and authority connectors
3d30617 - Add U.S. authority profiles, source role modeling, and specialized connectorsThen came the misinformation analyzers, one by one:
a65fef7 - Add rhetorical fallacy analyzer for detecting narrative manipulation
5dcf99d - Add headline-body divergence detection and headline citation amplification
a113efd - Add smear campaign defense with circular citation and viral volume detection
56d501a - Add media ownership modeling, syndication detection, and independence analysisThe hardening phase against noise and false positives is the one that took the most time:
46e4bc5 - Add pre-fetch defenses: URL filtering, circuit breaker, fetch prioritization
168fea1 - Add post-fetch content gate, claim noise filter, and duplicate content skip
b2843d7 - Add paywall detection, pricing noise filter, and ofertas.* host rejection
b1b230d - Rewrite Chromium fetcher with Ferrum CDP for anti-bot evasionThen came the interface, deployment, and the more advanced analyzers:
c5afcea - Replace custom CSS with Tailwind CSS v4 and rewrite all templates
95a8ec4 - Add Docker deployment with bin/deploy script
ccfacc9 - Add coordinated narrative detection across media outlets
ba3e2f4 - Add 6 new misinformation detection analyzers with cross-analysis
fda984b - Add LLM-generated investigation summary with quality assessment
a4ebe78 - Add contextual gap analysis to detect manipulation through omissionAnd in the most recent commits, simultaneous 3-model consensus and test optimization:
5cc9c05 - Enable 3-model LLM consensus: Sonnet 4.6, GPT-4.1 Mini, Gemini 2.5 Pro
cdf5fb5 - Batch 5 content analyzers into single LLM call, add anti-hallucination
28c305e - Add WebMock stubs for LLM and web search — tests run in 1.4s (was 540s)The tests that used to run in 9 minutes now run in 1.4 seconds with WebMock stubbing of every LLM and web search call. That made a huge difference in iteration speed.
Limitations
News fact-checking is a hard problem. A single article doesn’t contain everything needed for a complete analysis. The author chose what to include and what to omit, and that choice is already the first level of manipulation. The sources cited inside the article were selected by the author to support their narrative, not to give a balanced view.
Frank Investigator doesn’t tell you what’s true and what’s false. The result is a report with strong and weak points, not a “true” or “false” stamp. Even with all the safeguards I described above, the counter-evidence searched for automatically may not be the most relevant. The fallacies detected can have false positives. The coordinated campaign analysis depends on what web search returns at the moment of the lookup.
Use the reports as a starting point to form your own opinion, not as a final verdict.
The project is open source, AGPL-3.0. If you want to contribute, test, report bugs or suggest improvements: GitHub. If you want to follow the analyses, the The Makita Chronicles newsletter is going to have a “Notícias Duvidosas” (Dubious News) section with the summary and a link to the full report of each investigation.