Integration Tests in a Monorepo | Behind The M.Akita Chronicles
This post is part of a series; follow along via the tag /themakitachronicles. This is part 8.
And make sure to subscribe to my new newsletter The M.Akita Chronicles!
–
Unit tests are every developer’s comfort zone. You mock everything, isolate everything, run it in milliseconds, and the green in the terminal gives you a false sense of security. Until the day you deploy and discover that service A writes in a format service B can’t read. Or that the Hacker News RSS switched from Atom to RSS and your parser blew up. Or that Yahoo Finance started returning 429 after the third ticker because the rate limit that worked in tests doesn’t exist in real life.
Unit tests prove the pieces work in isolation. Integration tests prove the system works. And in a project with multiple applications sharing data via the filesystem, the difference between the two is the difference between “the code compiles” and “the newsletter lands in the inbox”.
The Problem: Three Apps, One Filesystem, Zero Guarantees
The project has an unusual architecture: three Rails/Hugo applications in a monorepo, integrated through a shared content/ directory:
akitando-news/
├── marvin-bot/ # Gera conteúdo (Discord bot, AI, scraping)
├── newsletter/ # Monta e envia a newsletter
├── blog/ # Hugo + Hextra → Netlify
├── podcast-tts/ # Servidor TTS (Python/FastAPI)
└── content/ # Markdown + YAML, a cola entre tudomarvin-bot writes Markdown with YAML frontmatter into content/anime/, content/hacker_news/, etc. The newsletter reads those files to assemble the newsletter. The blog serves the same content as static pages. The podcast reads the assembled newsletter to generate the dialogue script.
The contract between these systems is implicit. There’s no schema. No versioned API. No protobuf. The contract is: “the Markdown file has this frontmatter, with these fields, in this structure”. If marvin-bot changes the format of a field — say, switches image from string to array — the newsletter breaks silently. No unit test in either app detects it.
That’s the fundamental flaw of testing distributed systems with unit tests: you’re testing each side of the contract separately, but never the contract itself.
Layer 1: Unit Tests With Paranoid Isolation
Before talking about integration, I need to explain what the unit tests do in this project — because without that foundation, the integration tests would have nothing to stand on.
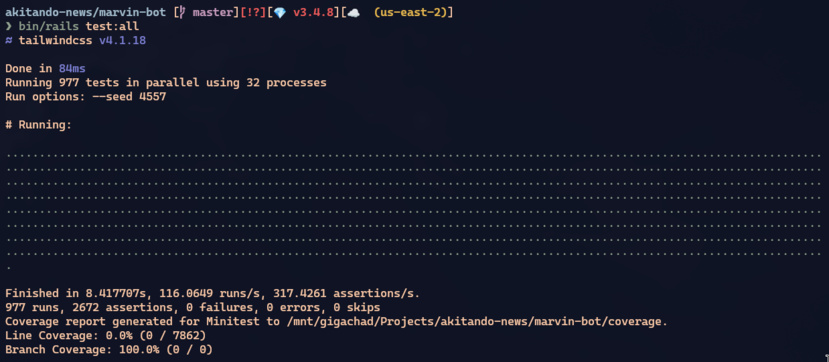
The 977 marvin-bot tests run in parallel using every core on the machine. Each test worker has its own directory:
parallelize(workers: :number_of_processors)
parallelize_setup do |worker|
Rails.application.config.content_dir =
Rails.root.join("tmp", "test_content_w#{worker}").to_s
endBut worker-level isn’t enough. Inside each worker, multiple tests run sequentially — and if one test leaves a file in content/stories/, the next test might find spurious data. The solution: one unique directory per test:
setup do
@base_content_dir = Rails.application.config.content_dir
@test_content_dir = File.join(@base_content_dir, SecureRandom.hex(8))
Rails.application.config.content_dir = @test_content_dir
FileUtils.mkdir_p(File.join(@test_content_dir, "stories"))
FileUtils.mkdir_p(File.join(@test_content_dir, "newsletters"))
FileUtils.mkdir_p(File.join(@test_content_dir, "images"))
end
teardown do
FileUtils.rm_rf(@test_content_dir) if @test_content_dir
Rails.application.config.content_dir = @base_content_dir if @base_content_dir
endPay attention to the teardown line that restores @base_content_dir. Without it, the next test would create its directory inside the previous test’s directory — tmp/test_content_w3/abc123/def456/ — and by test 50 you’d have a path 50 levels deep. I learned this burning an entire afternoon debugging why the tests kept getting slower as the suite progressed.
This pattern — worker-level base + per-test subdirectory + restore on teardown — is identical across both apps. And it’s what lets you run 977 tests in 7 seconds with 32 parallel workers.
The golden rule: the test content_dir must NEVER point to the real ../content. If it does, the teardown’s rm_rf wipes out your production prompts. This isn’t hypothetical — it happened during development.
Layer 2: The Integration Environment
Unit tests mock everything: external APIs, AI, Discord, SES. That’s correct — you don’t want to burn $2 in GPT-5.2 tokens every time you run bin/rails test. But it means the tests never exercise the real pipeline.
The project has a third environment beyond development and test: integration. It’s not test. It’s not staging. It’s a specific mode for running the full pipeline with real data, using real APIs, but without sending actual emails:
# config/environments/integration.rb
# Jobs rodam inline (perform_later vira perform_now)
config.active_job.queue_adapter = :inline
# Emails salvos em arquivo ao invés de enviados via SES
config.action_mailer.delivery_method = :file
config.action_mailer.file_settings = {
location: Rails.root.join("tmp/integration_emails")
}The queue_adapter = :inline is crucial. In production, perform_later enqueues the job into SolidQueue and a separate worker executes it. In integration, it runs right there, in the same process. That turns the asynchronous production pipeline into a synchronous pipeline you can run, observe, and debug sequentially.
SES is swapped for writing to disk — every email becomes an HTML file in tmp/integration_emails/. After running the pipeline, you open those HTMLs in the browser to visually validate that the email renders correctly.
Layer 3: DevCache — LLMs Aren’t Idempotent
Here’s a problem anyone working with AI in production knows: calling GPT-5.2 with the same prompt twice doesn’t return the same answer. And every call costs money. If you’re iterating on the integration pipeline — running, tweaking a prompt, running again — spending $3 per iteration gets expensive fast.
The solution is DevCache: a file-based cache that only activates in the integration env:
module DevCache
CACHE_TTL = 1.day
CACHE_ENVS = %w[integration].freeze
def self.fetch(namespace, key)
return yield unless enabled?
path = cache_path(namespace, key)
if path.exist? && File.mtime(path) > CACHE_TTL.ago
return JSON.parse(path.read, symbolize_names: true)
end
result = yield
path.write(JSON.generate(result))
result
end
endIn production and in test, DevCache.fetch runs the block directly. In integration, it saves the result as JSON and returns the cached value on the next run. TTL of 1 day — enough to iterate within the same day without recomputing, short enough to not serve stale data.
The generation code uses it like this:
summary = DevCache.fetch("summarize", url_key) do
AiChat.summarize(article[:content], source_url: url)
endFirst run: calls GPT-5.2, pays $0.02, saves to tmp/dev_cache/summarize/{md5}.json. Second run: reads from the cache, zero cost. FORCE=1 busts the cache when you want to force regeneration — as an explicit flag, not a default.
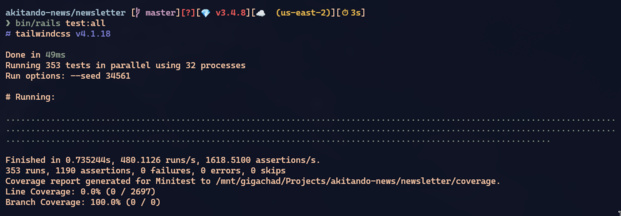
DevCache exists in both apps (marvin-bot and newsletter) with identical implementation. When you run integration:clean, both caches are wiped.
The point: LLM caching in a development environment is a requirement, not an optimization. Without it, iterating on a prompt that needs 8 API calls becomes financially unworkable.
Layer 4: Real Data via Rsync
This is where most projects stop. They have unit tests, maybe a staging environment, and ship it. The problem: staging uses test data. Test data is too clean. It doesn’t have the edge cases real data has:
- Articles with titles in Japanese (anime ranking)
- URLs that redirect 3 times before reaching the destination
- Images that return 200 with Content-Type
text/html(CloudFlare error page) - Previous newsletters with slightly different frontmatter formats
- Stories with
score: nullbecause they were created before the field existed
The solution: rsync from production.
# Limpa conteúdo gerado (preserva stories e imagens de produção)
cd marvin-bot && bin/rails integration:clean
# Sincroniza content/ de produção pra local
rsync -avz --delete production:/path/to/content/ ../content/
# Roda o pipeline completo com dados reais
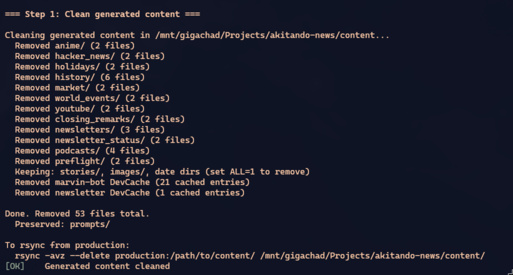
RAILS_ENV=integration bin/rails integration:pipelineintegration:clean is surgical: it removes generated directories (anime/, hacker_news/, newsletters/, podcasts/) but preserves stories/ and images/ — which are user-submitted data coming in via Discord. After the rsync, the local directory is an exact copy of production.
The pipeline then generates every section from that real data. If a parser breaks on a Korean title, you find out here — not in production at 5pm on a Sunday when the 8 jobs run in parallel.
Layer 5: The Full Pipeline
The heart of the integration system is integration:pipeline. It simulates the entire production week in a single run:
RAILS_ENV=integration bin/rails integration:pipelineThe pipeline runs in waves, honoring dependencies:
Wave 1 (paralelo, 8 jobs):
Book, Holidays, History, Geek History,
Anime, Hacker News, YouTube, World Events
Wave 2 (depende de World Events):
Market Recap
Wave 3 (depende de tudo):
Closing Remarks
Preflight → Newsletter Assembly → Podcast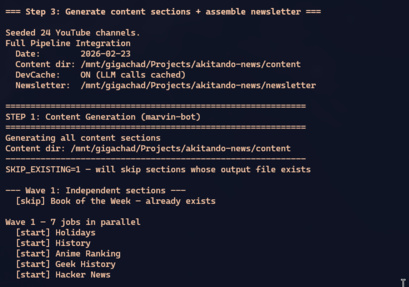
Each wave runs its jobs in parallel threads, exactly like production does with SolidQueue. Parallel execution isn’t an implementation detail here — it’s a test feature. If two jobs try to write to the same file, or if one job reads a file another is in the middle of writing, the bug shows up here.
threads = to_run.map do |name, klass|
Thread.new do
ActiveRecord::Base.connection_pool.with_connection do
run_single_job(name, klass, target_date, results)
end
end
end
threads.each(&:join)with_connection is necessary because each thread needs its own SQLite connection — without it, connections leak and the pool gets exhausted.
At the end, the pipeline prints a status table and a billing summary:
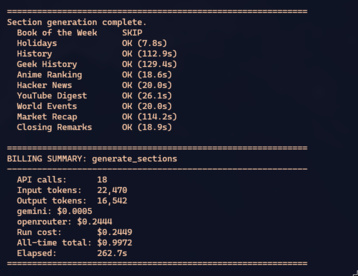
That billing summary isn’t vanity — it’s cost control. If a refactored prompt triples the output tokens, you see it here before going to production and burning 10x on a Sunday with 200 stories.
Layer 6: Preflight — Automated Structural Validation
After generating every section, the pipeline runs ContentPreflight. It doesn’t validate the content — it validates the structure. Each section gets checked:
- Does the file exist? If
content/anime/2026-02-16.mddoesn’t exist, something failed. - Minimum item count? The anime section needs at least 3 items. If it has 1, the generator had a problem.
- Required markers? The Markdown must contain
[COMMENTARY]and[AKITA]— without them, newsletter assembly doesn’t know where to cut. - Specific data? Market recap needs at least 5 ticker rows.
The result is a status per section: pass, degraded, fail, or skip. The pipeline uses this to decide whether the newsletter can be assembled automatically or needs human intervention:
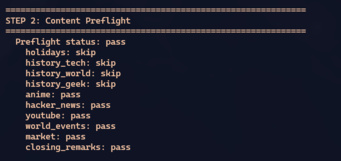
In production, this result goes to Discord as an embed. In the integration pipeline, it’s printed to the terminal. The logic is the same — the notification channel changes.
Layer 7: Cross-App — Newsletter Assembly
Here’s where the monorepo pays dividends. marvin-bot needs to invoke the newsletter to assemble the final newsletter. In production, these are different servers. In the integration pipeline, it’s a system() call:
env_vars = "RAILS_ENV=integration CONTENT_DIR=#{Shellwords.escape(content_dir)}"
cmd = "cd #{newsletter_dir} && #{env_vars} bin/rails integration:generate_all"
system(cmd)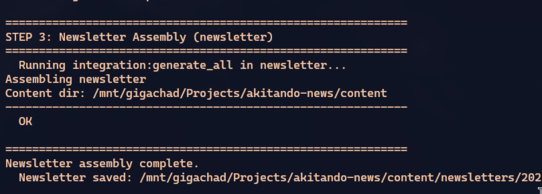
The newsletter reads the files marvin-bot just generated in content/, assembles the newsletter, and saves the result in content/newsletters/. CONTENT_DIR is passed explicitly — both apps point to the same directory.
If the frontmatter format changed and the newsletter can’t parse it, the error shows up here. If the newsletter’s SectionParser has diverged from marvin-bot’s SectionParser (they’re identical copies, but maintained by hand), here’s where you find out.
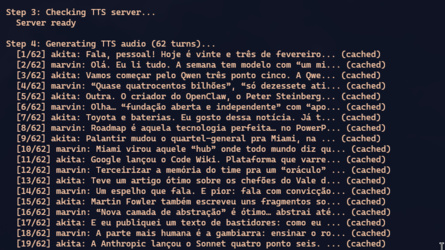
After the newsletter, the podcast: the pipeline invokes podcast:integration, which generates the dialogue script from the assembled newsletter, synthesizes audio via TTS, and builds the final MP3. It’s the longest pipeline — from Markdown newsletter to Spotify-ready MP3, passing through a two-pass LLM and per-turn voice synthesis.
The Value of Testing With Production Data
Let me give concrete examples of bugs that only showed up with real data:
1. Japanese anime titles broke the slugify.
ContentWriter.slugify used Rails’ parameterize, which strips non-ASCII characters. Title: “進撃の巨人 Season 4” → slug: “season-4”. Two anime with the subtitle “Season 4” collided on the filesystem. It never showed up in tests because the fixtures used English titles.
2. The HackerNews parser assumed RSS, but the feed switched to Atom.
rss/channel/item became feed/entry. Unit tests mocked the XML. The parser itself was never tested against the real feed. Running integration with the real rsynced feed, the parser returned zero items — caught by preflight as fail.
3. Yahoo Finance returned 429 after the 5th ticker. Rate limiting didn’t exist in tests (HTTP was mocked). In the real integration, the first 5 tickers went through, then everything failed. The fix — sleeping between requests — would never have been implemented without real data exposing the problem.
4. Images with a valid URL but the wrong Content-Type.
A CDN returned 200 for image URLs, but with an HTML body (Cloudflare error page). UrlValidator.reachable? returned true. ImageProcessor.download_image downloaded the HTML and tried to resize it. mini_magick crashed with an obscure error. The fix: validate Content-Type on the HEAD response — but this scenario would never surface with mocked URLs.
5. Newsletter assembly failed on stories with score: null.
Old stories, created before the score field had a default, had nil in the frontmatter. Assembly tried to do sort_by { |s| s[:frontmatter]["score"] } — nil <=> "high" raises ArgumentError. It only appeared when I rsynced production data that had 3 months of accumulated stories.
None of these bugs would be caught by a unit test. All of them were caught by the integration pipeline with real data.
Practical Tips
1. Separate Cost From Fidelity
The full integration pipeline costs around $0.40 in API calls. Not much, but if you run it 10 times in a day while iterating, that’s $4. DevCache solves this: the first run pays, the following runs are free.
But there are scenarios where you want to pay again — when you change a prompt and need to see the real result. FORCE=1 busts the cache selectively. And SKIP_EXISTING=1 skips sections that have already been generated, saving time when you only want to re-run a specific section.
2. The Integration Environment Is Not Staging
Staging is a server running 24/7 simulating production. The integration environment is a local execution mode you turn on when needed and turn off when you’re done. No dedicated infrastructure required. No separate database required. Same code, same machine, different flags.
The difference is philosophical: staging tests “does the system work on the staging server?”. Integration tests “does the system work with this specific data?”. The first is environment-dependent. The second is data-dependent. And data bugs are more common than environment bugs.
3. Clean Before Rsync, Not After
Order matters: clean the generated content before syncing from production. If you do the opposite — rsync first, clean after — you lose the production data you just downloaded.
integration:clean is surgical by design. It removes anime/, hacker_news/, newsletters/ (generated), but preserves stories/ and images/ (production). That enables an iterative workflow: rsync once, run the pipeline, tweak a prompt, run again — without re-downloading 500MB of content.
4. Preflight Is Your Smoke Test
Don’t trust “ran without exception = correct”. A generation job can run, produce a Markdown with 2 items instead of 10, and return success. Preflight catches that by verifying minimum counts, required markers, and expected structure.
In practice, every LLM bug I’ve found was caught by preflight: truncated responses, wrong format, missing sections. GPT-5.2 is good, but it isn’t deterministic — and when it fails, it fails in creative ways no schema validation would catch.
5. Billing Summary Is Not Optional
If you’re using LLMs in production, every test pipeline needs to report cost. Not for accounting — for engineering. A prompt that works but costs 3x more than the previous one is a performance bug. Input and output tokens per provider, cost per job, total cost — all visible on every run.
6. Monorepo Helps, But Doesn’t Solve
Having the three apps in the same repository helps: a git bisect covers changes on both sides of the contract. A PR that changes the frontmatter format in marvin-bot can also update the parser in newsletter — in the same commit.
But “can” isn’t “guarantees”. The contract between the apps is file-based and implicit. There’s no shared type, no common interface. SectionParser is copied manually between the two apps. If someone edits one and forgets the other, they diverge. The integration test is the only verification that both sides agree.
7. Preview Before Sending
The pipeline doesn’t end at generation. The newsletter has a newsletter:preview that renders the final result as HTML in light and dark mode:
cd newsletter
FILE=../content/newsletters/2026-02-16.md bin/rails newsletter:preview
# → tmp/preview/newsletter_light.html
# → tmp/preview/newsletter_dark.htmlOpening those HTMLs in the browser is the visual integration test. The Markdown can be perfect, the frontmatter correct, every field present — but an anime image shows up stretched because the aspect ratio changed. Or Marvin’s commentary block doesn’t have enough contrast in dark mode. Those bugs are visual — no automated test catches them.
8. The CI Pipeline Is Different From the Integration Pipeline
These are different things. CI runs on every commit:
bin/ci # rubocop + bundler-audit + brakeman + tests (~22s)Integration runs when you want to validate the pipeline end-to-end — before a deploy, after changing prompts, or after rsyncing fresh data from production. CI is fast and cheap. Integration is slow and costs money. Both are necessary.
The Cost of Not Having Integration
Let me be direct: if this project didn’t have the integration pipeline, I would have shipped at least 3 broken newsletters.
One with the anime section missing because the XML parser assumed RSS and the feed was Atom. One with every YouTube image pointing to 404 because the thumbnail URL pattern changed. And one with the market recap showing last month’s tickers because Yahoo Finance blocked the requests and the job failed silently.
Unit tests would have passed in all those scenarios. CI would have gone green. The deploy would have shipped. And at 7am on a Monday, 300 people would have received a newsletter full of holes.
The integration pipeline is expensive — in setup time, in API cost, in maintenance complexity. But it’s orders of magnitude cheaper than sending broken content to real subscribers. Especially when you only get one shot a week.
Conclusion
The testing hierarchy in this project is:
- Unit tests (1,330 across both apps, 7 seconds in parallel, $0): prove each piece works in isolation
- CI pipeline (rubocop + audit + brakeman + tests, ~22 seconds, $0): prove the code is healthy
- Integration pipeline (real data, real APIs, ~3 minutes, ~$0.40): proves the system works
- Visual preview (HTML in the browser, manual, $0): proves the final result is presentable
Each layer catches a different type of bug. None of them is enough alone. And the one that surprises most — the one that catches the bugs you swore didn’t exist — is the third: real data, real pipeline, no mocks.
The confidence you have in your system is proportional to how real the data in your tests is. Mock everything and you get 100% coverage and zero confidence. Test with production data and you get the truth — however inconvenient.