Memória de Agentes IA: Karpathy LLM Wiki e agentmemory na Prática
Atualização (23 de maio de 2026): depois de uma semana rodando o agentmemory em produção pessoal, voltei atrás. A arquitetura escolhida acumula uma classe de bug que não fecha sem reescrever metade do sistema (BM25 reindex a cada restart, janela de 5s de perda de dados, hook errado em ~47% das tool calls do Claude Code, etc). Comecei um substituto em Rust chamado ai-memory que resolve esses problemas. Veja Criei um Sistema de Memória pra Agentes de Código: ai-memory com o relato completo, o ranking das alternativas e como instalar. O resto desse post continua válido como background sobre como compaction funciona nos três agentes, o padrão LLM Wiki do Karpathy, e por que memória externa importa.
Todo mundo que mexe com Claude Code, Codex CLI ou opencode em sessões longas em algum momento topou com a mensagem “context approaching limit” ou viu o agente “esquecer” decisões tomadas três horas atrás. Esse post é um mergulho em como funciona a memória desses agentes hoje, onde ela quebra, e o que dá pra fazer pra ter algo mais parecido com memória de longo prazo. Olhei o código-fonte direto do Codex (Rust), do opencode (TypeScript) e do Claude Code (TypeScript, via o vazamento que circulou recentemente), e fechei testando o agentmemory, um servidor MCP open source que tenta resolver o problema de forma sistemática.
Antes de tudo: o que é “contexto”
Um modelo de linguagem (LLM) não tem memória persistente. O que ele “lembra” durante uma conversa é só o conjunto de tokens que cabem na janela de contexto dele. Cada mensagem trocada, cada arquivo lido, cada saída de comando, cada chamada de ferramenta — tudo isso entra na janela. Quando você usa Claude Code, Codex ou opencode, o agente está montando uma sequência de mensagens (system prompt + histórico + ferramentas + saída delas) e mandando inteira pra API a cada turno.
Isso tem dois efeitos diretos. O primeiro é comportamental: o agente performa melhor quando a parte relevante da conversa está fresca no contexto, e piora à medida que informação importante fica enterrada sob páginas de output de ls e grep. O segundo é financeiro: cada token enviado é cobrado (ou descontado da sua cota), e janelas grandes têm latência maior. Opus 4.7 tem 1M de contexto, GPT 5.5 também, mas só porque a janela cabe não significa que vale a pena enchê-la. Quanto mais cheia, mais lenta a inferência e mais cara a request.
Por isso todos os agentes implementam algum mecanismo de compaction: quando o contexto se aproxima do limite, o agente roda uma chamada LLM extra que resume a conversa até ali em um texto bem menor, descarta o histórico bruto, e continua a sessão em cima desse resumo. O ganho é óbvio (mais espaço pra trabalhar) e o custo também (a parte resumida perde detalhe).
Vamos ver como cada um dos três grandes implementa isso.
Codex CLI: limite por modelo + handoff explícito
O Codex CLI é open source (github.com/openai/codex), então dá pra ler o código direto. A lógica de auto-compaction vive em codex-rs/core/src/session/turn.rs e dispara assim:
let auto_compact_limit = model_info.auto_compact_token_limit().unwrap_or(i64::MAX);
// ... a cada turno ...
let total_usage_tokens = sess.get_total_token_usage().await;
let token_limit_reached = total_usage_tokens >= auto_compact_limit;
if token_limit_reached && needs_follow_up {
let reset_client_session = match run_auto_compact(
&sess, &turn_context, &mut client_session,
InitialContextInjection::BeforeLastUserMessage,
CompactionReason::ContextLimit,
CompactionPhase::MidTurn,
).await { /* ... */ }
}O limite é por modelo (auto_compact_token_limit vem de ModelProviderInfo). Quando bate, o Codex chama o próprio LLM com um prompt específico de compaction (em codex-rs/core/templates/compact/prompt.md):
Você está executando um CHECKPOINT DE COMPACTAÇÃO DE CONTEXTO. Crie um resumo de handoff pra outro LLM que vai retomar a tarefa.
Inclua:
- Progresso atual e principais decisões tomadas
- Contexto importante, restrições ou preferências do usuário
- O que ainda falta ser feito (próximos passos claros)
- Quaisquer dados críticos, exemplos ou referências necessárias pra continuar
A resposta vira o novo contexto, prefixada com um preâmbulo que diz literalmente “another language model started to solve this problem and produced a summary of its thinking process”. O Codex emite eventos pre_compact e post_compact que hooks podem interceptar (rodam em codex-rs/core/src/hook_runtime.rs). Esses hooks são o ponto onde ferramentas externas (como o agentmemory) se plugam pra salvar o estado antes da compaction destruir o histórico.
opencode: buffer de 20K + summarização ancorada
O opencode (github.com/sst/opencode) faz a mesma coisa com uma matemática diferente. Em packages/opencode/src/session/overflow.ts:
const COMPACTION_BUFFER = 20_000
export function usable(input: { cfg, model, outputTokenMax? }) {
const context = input.model.limit.context
const reserved = input.cfg.compaction?.reserved
?? Math.min(COMPACTION_BUFFER, ProviderTransform.maxOutputTokens(input.model, input.outputTokenMax))
return input.model.limit.input
? Math.max(0, input.model.limit.input - reserved)
: Math.max(0, context - ProviderTransform.maxOutputTokens(input.model, input.outputTokenMax))
}
export function isOverflow(input) {
if (input.cfg.compaction?.auto === false) return false
const count = input.tokens.total
|| input.tokens.input + input.tokens.output + input.tokens.cache.read + input.tokens.cache.write
return count >= usable(input)
}Por padrão, opencode reserva 20K tokens como buffer entre o conteúdo e o limite da janela. Quando o total de tokens passa de usable(), marca a sessão como needsCompaction = true e dispara o fluxo de compaction no próximo turno. O prompt de summarization (em packages/opencode/src/agent/prompt/compaction.txt) é mais cirúrgico que o do Codex:
Você é um assistente de sumarização de contexto ancorado pra sessões de coding.
Resuma apenas o histórico de conversa que recebeu. Os turnos mais recentes podem ser mantidos verbatim fora do seu resumo, então foque no contexto mais antigo que ainda importa pra continuar o trabalho.
Se o prompt incluir um bloco
<previous-summary>, trate ele como o resumo ancorado atual. Atualize com o histórico novo preservando detalhes que continuam verdadeiros, removendo detalhes obsoletos e mesclando fatos novos.
Repare na diferença: o opencode mantém um “anchored summary” que é atualizado a cada compaction, não regenerado do zero. Os turnos mais recentes ficam verbatim, e só o histórico antigo é colapsado. É um meio-termo entre o handoff completo do Codex e manter tudo cru.
Claude Code: três níveis de compaction + summary detalhado
O Claude Code é proprietário, mas um vazamento recente expôs a fonte (TypeScript, igual o opencode mas com arquitetura bem diferente). O código mostra que a Anthropic foi mais longe que os concorrentes: o Claude Code tem três níveis de compaction rodando em paralelo, não um.
O primeiro é o microcompact time-based, em src/services/compact/microCompact.ts e timeBasedMCConfig.ts. Quando o gap desde a última mensagem do assistente passa de 60 minutos, o cache de prompt do servidor (TTL de 1h) está garantidamente expirado, então o prefixo inteiro vai ser reescrito de qualquer jeito na próxima request. Antes de mandar, o Claude Code limpa o conteúdo de resultados antigos de ferramentas (Read, Grep, Glob, WebFetch, Bash, etc.) e substitui por [Old tool result content cleared]. Reduz o tamanho da request sem entrar no fluxo caro de summarization. Comentário no código:
/** Trigger when (now − last assistant timestamp) exceeds this many minutes.
* 60 is the safe choice: the server's 1h cache TTL is guaranteed expired
* for all users, so we never force a miss that wouldn't have happened. */
gapThresholdMinutes: numberO segundo nível é o autoCompact, em src/services/compact/autoCompact.ts. Análogo ao do opencode, mas com mais cuidado:
const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000
export const AUTOCOMPACT_BUFFER_TOKENS = 13_000
export const WARNING_THRESHOLD_BUFFER_TOKENS = 20_000
export const ERROR_THRESHOLD_BUFFER_TOKENS = 20_000
export function getAutoCompactThreshold(model: string): number {
const effectiveContextWindow = getEffectiveContextWindowSize(model)
return effectiveContextWindow - AUTOCOMPACT_BUFFER_TOKENS
}Reserva 20K tokens pra saída da summarization, 13K de buffer pra disparar a compaction, e tem warning + error thresholds 20K abaixo desse limite (a barra de status do TUI fica amarela quando passa do warning, vermelha no error). Tem também um circuit breaker: depois de 3 falhas consecutivas de auto-compact, para de tentar — um comentário interno revela que sem isso “1,279 sessions had 50+ consecutive failures (up to 3,272), wasting ~250K API calls/day globally”.
O terceiro nível é o sessionMemoryCompact em sessionMemoryCompact.ts, marcado como experimental, que cruza com o sistema de memória persistente entre sessões.
A diferença mais visível em comparação com Codex e opencode está no prompt de summarization. Onde o Codex pede 4 bullets curtos e o opencode pede um update do “anchored summary”, o Claude Code pede uma estrutura de 9 seções explícitas (src/services/compact/prompt.ts):
- Pedido e Intenção Primária: Capture todos os pedidos e intenções explícitas do usuário em detalhe
- Conceitos Técnicos-Chave: Liste todos os conceitos técnicos, tecnologias e frameworks discutidos.
- Arquivos e Trechos de Código: Enumere arquivos e trechos específicos que foram examinados, modificados ou criados…
- Erros e correções: Liste todos os erros que apareceram e como foram corrigidos…
- Resolução de Problemas: Documente problemas resolvidos e investigações em andamento.
- Todas as mensagens do usuário: Liste TODAS as mensagens do usuário que não são resultados de ferramentas. São críticas…
- Tarefas Pendentes: Liste tarefas pendentes que foram explicitamente solicitadas.
- Trabalho Atual: Descreva em detalhe precisamente o que estava sendo feito imediatamente antes desse pedido de resumo…
- Próximo Passo Opcional: Liste o próximo passo que você vai tomar…
A seção 6 (“All user messages”) é a mais incomum: o resumo precisa conter a lista verbatim de cada mensagem do usuário que não seja resultado de ferramenta. Ou seja, mesmo depois da compaction, o Claude Code preserva o que você pediu, literal. Isso explica por que sessões compactadas no Claude Code parecem manter o tom da conversa melhor que as do Codex (onde o handoff é mais executivo e menos narrativo).
Existe também uma variante PARTIAL_COMPACT_PROMPT que summariza só o trecho mais recente quando há um summary anterior preservado, e uma PARTIAL_COMPACT_UP_TO_PROMPT pra preservar cache hit ao colocar o resumo no início. O comando /compact continua disponível como força manual, e os hooks PreCompact / PostCompact rodam como nos outros agentes.
Comparando os três lado a lado
| Claude Code | Codex | opencode | |
|---|---|---|---|
| Buffer pré-compaction | 13K (autocompact) + 20K (saída) | por modelo via auto_compact_token_limit | 20K (config compaction.reserved) |
| Tipos de compaction | 3 (microcompact, autocompact, sessionMemoryCompact) | 1 (mais variantes remote v1/v2) | 1 (anchored, com summary atualizável) |
| Estrutura do summary | 9 seções fixas + bloco <analysis> de scratchpad | 4 bullets livres (progress, decisions, next, refs) | Atualização do “anchored summary” previamente existente |
| Preservação verbatim | Lista todas mensagens do usuário | Não | Turnos mais recentes ficam intactos fora do summary |
| Circuit breaker | Sim, 3 falhas consecutivas param o ciclo | Não documentado | Não |
| Hooks | PreCompact / PostCompact | pre_compact / post_compact (Rust) | sem hooks de compaction explícitos |
| Microcompact por gap temporal | Sim (60min, sincronizado com TTL de cache) | Não | Não |
A escolha de design conta uma história. O Claude Code investe em preservar narrativa do usuário (as 9 seções, especialmente a 6) e otimizar custo de cache (microcompact por gap, separação clara entre 3 caminhos). O Codex prioriza handoff entre modelos (a frase “summary produced by the other language model” no prefixo do resumo mostra a expectativa de que o próximo turno pode ser executado por outro LLM). O opencode escolheu summarização incremental: o anchored summary é atualizado a cada ciclo, em vez de regenerado. Cada estratégia tem trade-offs, mas é a primeira vez que dá pra olhar lado a lado o código real dos três.
“Vendor lock”? Não existe pra esse tipo de memória
Uma preocupação que aparece muito é que ao começar com Claude Code você fica “preso” a ele, e não dá pra migrar pra opencode ou Codex depois. Isso é mito. Memória de agente, como vimos, é só texto. Não tem formato proprietário binário, não tem schema fechado, não tem state que só o vendor sabe ler. Tudo que o agente carrega é prompt + histórico de mensagens + arquivos de contexto.
Na prática você pode fazer handoff manual entre agentes. Pede pro Claude Code: “escreva um documento markdown em ./HANDOFF.md com o estado atual do projeto, decisões tomadas, próximos passos, e qualquer contexto importante pra um agente diferente continuar.” Sai uma sessão bem feita, fecha o Claude Code, abre o opencode, pede “leia ./HANDOFF.md e continue de onde parou.” E o opencode pega de onde o Claude parou, sem perda significativa (a perda é exatamente a mesma que uma compaction interna teria provocado).
Esse padrão de exportar contexto explicitamente é, inclusive, melhor do que confiar na compaction automática. Você decide quando e o que preservar, ao invés de deixar o agente decidir baseado em pressão de tokens.
O problema: long-term memory desaparece junto
Compaction resolve o problema imediato (espaço no contexto) mas cria um problema mais sutil: informação do início da sessão é eliminada primeiro. Se você passou 30 minutos no turno 5 explorando uma arquitetura, decidiu três trade-offs e descartou duas abordagens, no turno 50 essa exploração inteira pode ter virado uma linha de bullet point. Se você precisar voltar pra um daqueles trade-offs descartados (“por que decidimos não usar Redis aqui?”), o agente não sabe mais.
A solução que venho usando há meses é forçar o agente a escrever em arquivos manualmente. Em projetos importantes mantenho um diretório ./.docs/ ou ./docs/ com arquivos markdown organizados por tópico: arquitetura, decisões, pegadinhas conhecidas, configurações esquisitas, links pra issues relevantes. Quando alguma coisa importante acontece numa sessão, peço: “salva isso em ./.docs/<topico>.md”. Aí na próxima sessão, ou depois de uma compaction, o agente pode reler o arquivo se precisar.
O custo dessa abordagem é disciplina. Eu tenho que lembrar de pedir pra salvar. O agente não vai fazer isso sozinho. E eu tenho que organizar os arquivos pra que ele consiga achar o que precisa depois (o que normalmente significa um arquivo MEMORY.md ou CLAUDE.md no root listando os tópicos).
Existe uma forma mais sistemática de fazer isso. O nome dela é LLM Wiki, popularizada pelo Andrej Karpathy em abril de 2026 num gist no GitHub.
O padrão LLM Wiki do Karpathy
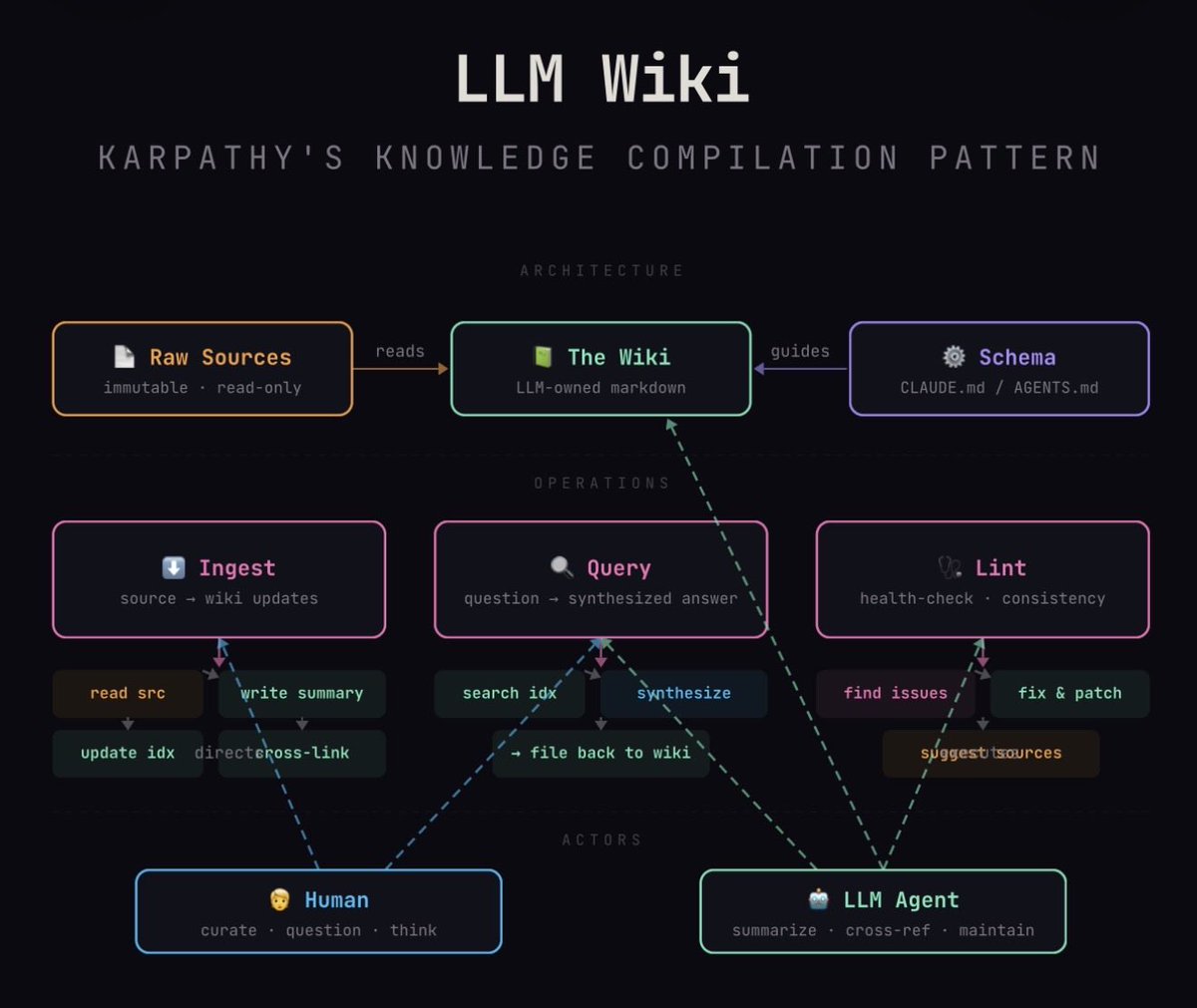
A ideia é simples e poderosa: em vez de tratar conhecimento como algo a recuperar sob demanda (RAG), trata como algo a compilar ao longo do tempo, igual código. A arquitetura tem três camadas:
- Raw Sources — documentos imutáveis (papers, artigos, transcrições, notas) que servem como source of truth.
- Wiki Layer — arquivos markdown gerados e mantidos pelo LLM. Cada conceito vira uma página. Páginas referenciam outras páginas. O LLM atualiza, faz cross-reference, marca contradições.
- Schema — um arquivo (estilo
CLAUDE.mdouSCHEMA.md) que define convenções: como nomear páginas, taxonomia de tags, estrutura mínima de cada entrada.
O workflow tem três operações. Ingest: quando uma fonte nova chega, o LLM lê, extrai o que importa, atualiza 10-15 páginas existentes, cria as que faltam, conserta cross-references. Query: perguntas ganham resposta sintetizada com citações; insights valiosos viram páginas novas. Lint: passes periódicos detectam contradições, claims desatualizadas, conexões faltando.
A vantagem central sobre RAG é que conhecimento compõe. RAG re-derive resposta a cada query, partindo dos mesmos documentos brutos. A wiki sintetiza uma vez, e a próxima query parte da síntese, não dos brutos. Pra programação isso vale ouro: a primeira vez que você descobre que uma biblioteca tem uma pegadinha esquisita com timezone, vira página da wiki. Da segunda vez que o assunto aparece, o agente lê a página, não re-descobre o problema.
O trabalho manual de manter uma wiki sempre matou wikis humanas. Por isso elas morrem. Mas LLMs são bons em escrita e manutenção repetitiva. A aposta do Karpathy é que finalmente temos uma máquina que faz o trabalho chato de manter a wiki viva.
agentmemory: implementação prática do padrão

Eu vinha fazendo essa wiki manualmente em ./.docs/ há meses. Essa semana migrei pra uma ferramenta que automatiza a maior parte do processo: o agentmemory do Rohit Ghumare. É open source (Apache-2.0), e é literalmente uma implementação do padrão LLM Wiki com algumas extensões (confidence scoring, lifecycle de memórias, knowledge graph, hybrid search).
O que ele é, na prática:
- Um daemon Node rodando localmente em
127.0.0.1:3111(REST) e:3113(viewer web com timeline e replay de sessão). Storage em SQLite + index vetorial em memória, zero dependência externa. - Um servidor MCP (
@agentmemory/mcp) que qualquer agente compatível com MCP (Claude Code, Codex, opencode, Cursor, Gemini CLI, etc.) carrega como stdio server. Expõe 51 tools de memória (memory_smart_search,memory_save,memory_sessions,memory_consolidate, etc.). - Plugins de hooks pra Claude Code (12 hooks) e Codex (6 hooks) que capturam observações automaticamente em cada tool call, prompt e evento de compaction.
- Retrieval híbrida: BM25 + vetor + knowledge graph, fundidos com Reciprocal Rank Fusion (RRF, k=60), com diversificação por sessão.
- 4-tier memory consolidation inspirada em como o cérebro humano processa memória durante o sono: Working (raw observations) → Episodic (resumos de sessão) → Semantic (fatos e padrões extraídos) → Procedural (workflows e padrões de decisão).
A última parte é o que torna isso interessante. Não é só um log de tudo que aconteceu. Tem decay (Ebbinghaus curve — memórias que não são acessadas decaem), reforço (memórias acessadas frequentemente fortalecem), eviction de stale, detecção e resolução de contradições. É exatamente o que falta no padrão “escrever em ./.docs/ manualmente”.
Instalação rápida
Tem três jeitos: npm global, npx, ou (o que eu fiz) um prefixo dedicado pra fugir do mise/Node version churn. A versão one-liner do README do projeto:
npm install -g @agentmemory/agentmemory # uma vez — `agentmemory` no PATH
agentmemory # sobe o daemon em :3111
agentmemory demo # popula sessões de exemplo + valida recall
agentmemory connect claude-code # configura seu agente (também: codex, cursor, gemini-cli, ...)Pra detalhes completos, o README do agentmemory cobre todas as variações (Docker, source build, Windows, embedding providers). Pra quem usa mise pra gerenciar Node, vale instalar num prefixo dedicado (algo como ~/.local/share/agentmemory-npm/) e subir o daemon via systemd user unit pra fugir do problema de pacotes globais sumirem quando o mise troca de versão de Node. Mas o caminho do README serve a maioria dos casos.
Depois de subir o daemon, o passo principal é registrar o servidor MCP no agente que você usa.
Pro Claude Code, edite ~/.mcp.json:
{
"mcpServers": {
"agentmemory": {
"command": "/path/to/agentmemory-mcp",
"env": { "AGENTMEMORY_URL": "http://localhost:3111" }
}
}
}Verifique com claude mcp list. Deve aparecer agentmemory: ✓ Connected.
Pro Codex CLI, edite ~/.codex/config.toml:
[mcp_servers.agentmemory]
command = "/path/to/agentmemory-mcp"
[mcp_servers.agentmemory.env]
AGENTMEMORY_URL = "http://localhost:3111"Pro opencode, edite ~/.config/opencode/opencode.json e adicione na raiz do objeto:
{
"mcp": {
"agentmemory": {
"type": "local",
"command": ["/path/to/agentmemory-mcp"],
"enabled": true,
"environment": { "AGENTMEMORY_URL": "http://localhost:3111" }
}
}
}Depois disso, os três agentes compartilham o mesmo servidor de memória. Salvou uma decisão no Claude Code, faz memory_smart_search no Codex e ela aparece.
Pra forçar o agente a consultar memória no início de tarefas não-triviais, vale adicionar uma linha no CLAUDE.md (ou equivalente):
At the start of non-trivial tasks, call `memory_smart_search` with the task
keywords. Use `memory_save` or `memory_lesson_save` when capturing decisions,
patterns, or preferences worth keeping.Caso contrário o agente usa as tools quando achar que faz sentido, mas vai esquecer em sessões puramente exploratórias.
Vantagem prática: handoff sem fricção
Aqui mora a coisa que mais me convenceu. Lembra do padrão de export-pra-markdown que descrevi antes, pra migrar entre agentes? Com agentmemory, isso fica automático. Salvou uma decisão arquitetural numa sessão de Claude Code (memory_save type=architecture content="usamos cookie store em vez de session store porque X"). Abre o opencode no mesmo projeto. Pergunta sobre persistência de sessão. O opencode chama memory_smart_search, recupera a entrada, e parte daí.
Esquece o “exportar pra markdown, abrir o outro agente, mandar ler”. Os dois agentes lêem do mesmo lugar. Vendor lock perde o sentido nesse setup, porque a fonte da memória é externa a ambos.
Os trade-offs que ficam
Não é mágica. Algumas coisas pra ter na cabeça:
A camada de embedding ideal é uma API paga (Voyage, OpenAI, Cohere). Sem isso o agentmemory usa MiniLM local via @xenova/transformers, que funciona mas é mais lento na primeira ingest e menos acurado em buscas semânticas complexas. Pra quem aceita rodar um modelo local, é solução real. Pra quem quer máxima qualidade de recall, vale a chave de API.
O daemon roda como processo permanente. Precisa de um systemd unit (eu rodo em user mode) ou launchd no macOS. Não é “rode o servidor quando lembrar” — tem que estar sempre up, senão os hooks do plugin perdem eventos.
A consolidação de 4 tiers usa um LLM pra processar. Sem chave de provider configurada, o agentmemory roda em “no-op mode” — ainda indexa observações e busca, mas não comprime nem consolida. Você ainda tem o equivalente da wiki, só que sem o “lint periódico” do Karpathy.
E como toda ferramenta nova, a documentação tem buracos. Algumas coisas pra ficar de olho que não estão no README upstream: o state path real depende de como o daemon é iniciado (relativo ao cwd), a porta 49134 do iii engine bindeia em 0.0.0.0 por default (passa pelo firewall, vale conferir), o import-jsonl não respeita o flag --dry-run apesar de o help global dizer que sim. Vale ler o README do projeto antes, e estar disposto a debugar quando a docs falhar.
Memória é texto. Texto precisa de gestão.
A síntese que eu tiro disso tudo é simples. Memória de agente, no fundo, é texto. Não tem schema proprietário, não tem formato binário, não tem state secreto. Isso é libertador: você não fica preso a um vendor, pode mover entre Claude Code, Codex e opencode na hora que quiser, manualmente ou via uma camada externa como o agentmemory.
Mas texto solto vira lixo rápido. Sem compaction, a janela de contexto enche e o agente fica lento e caro. Com compaction, perde-se memória de longo prazo. Sem disciplina de salvar em arquivos, decisões importantes evaporam na próxima compaction. Sem estrutura nos arquivos, eles viram um amontoado que o agente nem consegue ler eficientemente.
A solução é uma combinação de quatro camadas:
- Compaction resolve o problema de janela de contexto cheia. Os três grandes (Claude Code, Codex, opencode) fazem isso sozinhos.
- Markdown manual em
./.docs/ou./docs/é o fallback de base que sempre funciona, com a desvantagem de exigir disciplina do programador. - Padrão LLM Wiki (Karpathy) eleva o markdown manual a um workflow estruturado: source / wiki / schema, com ingest / query / lint.
- agentmemory (ou ferramentas similares via MCP) automatiza a wiki, adiciona consolidação em tiers, retrieval híbrida, lifecycle de memória, e como bônus serve os três agentes do mesmo daemon.
A parte mais subestimada disso tudo é o efeito composto. Uma decisão arquitetural salva hoje fica disponível pra todas as sessões futuras, em qualquer agente. Uma pegadinha de biblioteca descoberta na terça-feira não precisa ser re-descoberta no domingo. É o tipo de produtividade que demora algumas semanas pra aparecer (porque você precisa de massa crítica de memórias salvas), mas que muda o jogo quando engata.
Vale testar. Se você usa Claude Code, Codex ou opencode todo dia e nunca configurou nada de memória de longo prazo, comece pelo simples (um ./.docs/ no repo atual). Quando bater a frustração da terceira “explicação que eu já dei”, aí instala o agentmemory.