RAG Está Morto? Contexto Longo, Grep e o Fim do Vector DB Obrigatório
Já tem um tempo que essa coceira não me larga. No começo da onda de LLMs, lá em 2022/2023, a gente tinha 4k de contexto no GPT 3.5, 8k se esticasse, 32k era luxo. Pra fazer qualquer coisa com documento real, você não tinha escolha: tinha que recortar o texto em pedaços, gerar embeddings, jogar num vector database, fazer similarity search, pegar os top-5 chunks e rezar pra que os pedaços certos aparecessem.
Daí virou indústria. Pinecone, Weaviate, Qdrant, Chroma, Milvus, pgvector, LangChain, LlamaIndex, Haystack. Tutorial em todo canto, “construa seu chatbot com seus PDFs”, consultorias inteiras vivendo disso. Virou meio que o “hello world” de LLM aplicado: documento → chunk → embed → vector DB → query.
Hoje, em abril de 2026, o Claude Opus 4.6 tem 1 milhão de tokens de contexto. O Sonnet 4.6, idem. O Gemini 3.1 Pro também. O GPT 5.4 fica numa janela menor mas ainda confortável, na casa das centenas de milhares. E pra alguns modelos já tem modos experimentais de 2M tokens. A pergunta que não me larga é: pra que cargas d’água eu preciso montar uma stack vector pra resolver problema que cabe na janela do modelo?
E mais: vector database tem problemas reais que ninguém gosta muito de falar. Falsos vizinhos. Chunking arbitrário que parte definição do uso. Embeddings que envelhecem mal. Sem dizer que quando o resultado vem errado, você não tem a menor ideia do porquê.
A tese que eu venho amadurecendo é simples: na maioria dos casos, um grep bem feito mais uma janela de contexto generosa do modelo bate uma stack RAG completa. É mais barato, é mais fácil de manter, e quando dá pau você consegue debugar. Bora destrinchar.
O que o vazamento do Claude Code mostrou
Antes de entrar na parte teórica, vale falar de algo que aconteceu há poucos dias e que reforça muito essa discussão. Em 31 de março de 2026, a Anthropic, sem querer, publicou no npm a versão 2.1.88 do pacote @anthropic-ai/claude-code com um source map de quase 60 MB anexado, e cerca de 512 mil linhas de TypeScript da ferramenta interna deles vazaram pro mundo. Eu já tinha escrito sobre o incidente na semana passada, com mais detalhe sobre o que apareceu no código.
O que interessa pra essa discussão é o sistema de memória do Claude Code. Em vez de jogar tudo num vector DB, a arquitetura tem três camadas. Um MEMORY.md que fica permanentemente carregado no contexto, mas não guarda dado nenhum: é só um índice de ponteiros, umas 150 caracteres por linha, mantido abaixo de 200 linhas e uns 25 KB. Os fatos de verdade ficam em “topic files” buscados sob demanda quando o agente precisa. E os transcripts brutos das sessões anteriores nunca são relidos inteiros, só pesquisados com grep atrás de identificador específico. Sem embedding. Sem Pinecone. Disciplina de escrita (topic file primeiro, índice depois) e busca lexical, só isso.
O loop principal do Claude Code também tem um sistema escalonado pra lidar com contexto enchendo. Como eu detalhei no post anterior, são cinco estratégias diferentes de compactação de contexto, com nomes tipo microcompact (limpa resultados de tool antigos por tempo), context collapse (resume trechos longos da conversa), e autocompact (que dispara quando o contexto chega perto do limite). O CLAUDE.md, que muita gente pensava que era só uma convenção, é primeira classe na arquitetura: o sistema relê o arquivo a cada iteração da query.
O que isso me diz: a melhor ferramenta de coding agent que existe hoje, feita pela empresa que vende o modelo mais caro do mercado, não usa vector DB. Usa arquivos no disco, índice em markdown, busca lexical, e estratégias inteligentes de compactação quando o contexto estoura. Eles poderiam ter botado embedding, eles têm dinheiro pra rodar o que quisessem, e escolheram não. O motivo, na minha leitura, é exatamente o que esse post defende: pra recuperar texto de arquivos que você controla, com contexto generoso disponível, vector DB é peso morto. Melhor investir em compactar bem o que você já tem na janela do que indexar tudo num banco externo.
Tem um detalhe curioso de segurança que veio junto: a galera percebeu que o pipeline de compactação tem uma vulnerabilidade chamada de “context poisoning”. Conteúdo que parece instrução, vindo de um arquivo que o modelo lê (tipo um CLAUDE.md de um repo clonado), pode acabar sendo preservado pelo modelo de compactação como se fosse “feedback do usuário”, e o modelo seguinte segue isso como instrução genuína. É um vetor de ataque novo. Mas isso é assunto pra outro post.
O sistema “Dream” e a consolidação de memória
Mas o que mais me chamou atenção pro debate de RAG, e que eu já destrinchei na semana passada, é o sistema chamado autoDream. É um subagente forkado, com bash read-only no projeto, que roda em background enquanto você não está usando a ferramenta. O job dele é literalmente sonhar: consolidar memória. O nome não é à toa, e a analogia óbvia (que eu não consegui evitar) é a do cérebro humano consolidando memória durante o sono, transformando experiência de curto prazo em conhecimento mais estável.
Pra um sonho rodar, três portas têm que abrir ao mesmo tempo: 24 horas desde o último sonho, no mínimo 5 sessões desde o último, e um lock de consolidação que impede sonhos concorrentes. Quando dispara, segue quatro fases. Orient (faz ls no diretório de memória, lê o índice). Gather (busca sinais novos em logs, memórias desatualizadas e transcripts). Consolidate (escreve ou atualiza os topic files, converte data relativa em absoluta, deleta fato que foi contraditado). E Prune, que é a faxina final que mantém o índice abaixo das 200 linhas.
A decisão de fazer o autoDream como subagente forkado é o detalhe que importa aqui. Ele não roda no mesmo loop do agente principal. Por quê? Porque consolidação de memória é processo barulhento. O modelo tem que reler transcript antigo, comparar com o que está no MEMORY.md, decidir o que fica e o que sai, fazer hipótese sobre coisa que viu em sessão anterior. Se isso rodasse no contexto principal, poluía o “train of thought” do agente que está tentando ajudar você na tarefa do momento. Forkando, separa as duas coisas. O agente principal continua focado no que você pediu, o autoDream faz a faxina em paralelo, sem permissão de escrita no projeto.
E o jeito como ele acha o que tem que consolidar é busca lexical, pura e dura. Os transcripts ficam em arquivos JSONL no disco, e o autoDream usa grep pra procurar sinais novos. Grep mesmo, em log de texto. Pensa nisso por um segundo. A consolidação de memória do agente mais avançado do mundo, feita por uma das empresas mais ricas de IA, é um subagente forkado fazendo grep em log de texto. Se vector DB fosse a resposta certa pra esse tipo de problema, a Anthropic tinha botado vector DB. Não botaram.
E tem um detalhe que pra mim é o ouro escondido do leak inteiro, e que cabe perfeitamente nesse argumento. No autoDream, memória é tratada como pista. O sistema parte do princípio de que o que está armazenado pode estar velho, errado, contraditado por algo que aconteceu depois, e o modelo tem que verificar antes de confiar. O pitch do vector DB é o oposto disso: indexa tudo, busca por similaridade, devolve top-k, confia no resultado. O Claude Code escolheu o caminho conservador. Indexa pouco, busca por palavra, devolve pista, e desconfia até bater o olho no fato real.
A estratégia inteira tem duas camadas. Dentro da sessão, contexto generoso mais grep mais compactação inteligente (microcompact, context collapse, autocompact). Entre sessões, um subagente que consolida memória de forma assíncrona, usando grep nos transcripts e tratando o resultado como dica, não como verdade. Embedding e vector DB não aparecem em nenhum dos dois lugares. A escolha consciente foi leitor inteligente comendo texto bruto, não leitor burro consumindo top-k de embedding.
A lição prática pro nosso debate é simples. Os agentes mais avançados do mercado tão indo na direção de contexto generoso, busca lexical e compactação inteligente, não na direção de pipeline RAG clássico. Se a Anthropic, com toda a infraestrutura e talento que tem, escolheu esse caminho pra Claude Code, a gente que tá construindo aplicação interna com uma fração do orçamento deveria pelo menos considerar a mesma direção.
Onde a história começou a virar
Quando o teto era 32k de contexto, retrieval era o gargalo do problema inteiro. Você tinha que pré-filtrar agressivo, porque qualquer coisa que entrasse na janela era espaço sagrado. Vector DB foi a única forma decente de fazer essa pré-filtragem semântica. A lógica era: “o leitor (LLM) é caro e burro, então o retriever tem que ser inteligente e seletivo”.
Hoje a equação virou. O leitor agora é o cara mais inteligente da mesa, e a janela cresceu pra caber documento inteiro. Aí o retriever pode (e talvez deva) voltar pra ser burro. Quanto mais burro, melhor. Você quer alta cobertura e baixa precisão, e deixa o modelo fazer a parte fina. Grep faz exatamente isso. BM25 também. E ripgrep voa em cima de milhões de linhas sem pestanejar.
E não é só achismo meu. Os benchmarks BEIR já mostraram faz tempo que BM25 bate ou empata com vários retrievers densos quando o domínio sai de onde os embeddings foram treinados. A própria Anthropic publicou um post sobre Contextual Retrieval basicamente dizendo a mesma coisa: sinal lexical mais julgamento de LLM bate embedding puro na maior parte das tarefas de conhecimento. E olha o Claude Code, a ferramenta que eu uso todo dia há 500 horas: ele navega o repositório com Glob e Grep. Sem vector DB, sem embedding, sem LangChain. Funciona ridiculamente bem.
Os problemas reais do vector database que ninguém anuncia
A propaganda de vector DB vende o sonho da busca semântica perfeita. A realidade é mais bagunçada.
Falsos vizinhos é o primeiro. Cosine similarity premia similaridade tópica, não relevância. Você pergunta “como tratamos erro de autenticação” e o DB devolve todo chunk que menciona autenticação. O chunk que efetivamente responde pode estar em décimo lugar, ou nem ter aparecido porque o redator do doc usou “login” em vez de “auth”.
Chunking é o segundo, e é um desastre disfarçado. Janela de 512 tokens, overlap de 64, parece razoável até você perceber que sua tabela importante foi cortada no meio, a definição de uma função ficou separada do uso, e o pedaço da documentação com o comando exato ficou órfão sem o contexto da seção. A fronteira do chunk costuma ser exatamente onde a resposta morava.
Quando falha, falha sem deixar pista. Quando o BM25 não acha, você sabe o porquê: a palavra não tá lá. Quando o vector DB devolve lixo, você recebe um chunk plausível e errado, sem nenhum sinal diagnóstico. Boa sorte debugando isso em produção às duas da manhã.
Índice envelhece. Cada update do documento pede re-embedding. Se você tem 10 mil docs e uns 200 mudam por dia, isso vira processo de batch, monitoramento, fila, retry, custo de API de embedding, e uma janela de inconsistência inevitável entre o que tá no disco e o que tá no índice. Grep não tem nada disso. Arquivo mudou? Próxima query já vê.
E tem o custo de operação que ninguém soma. Pinecone cobra por vector. Weaviate pede cluster pra manter. pgvector evita servidor novo mas você continua com schema, índice e pipeline de re-embedding. Cada uma dessas coisas pede tempo de engenheiro, monitoramento, teste, deploy. Tudo isso pra fazer uma busca que muitas vezes o rg resolve em 200ms.
Comparando a complexidade
Olha o desenho:
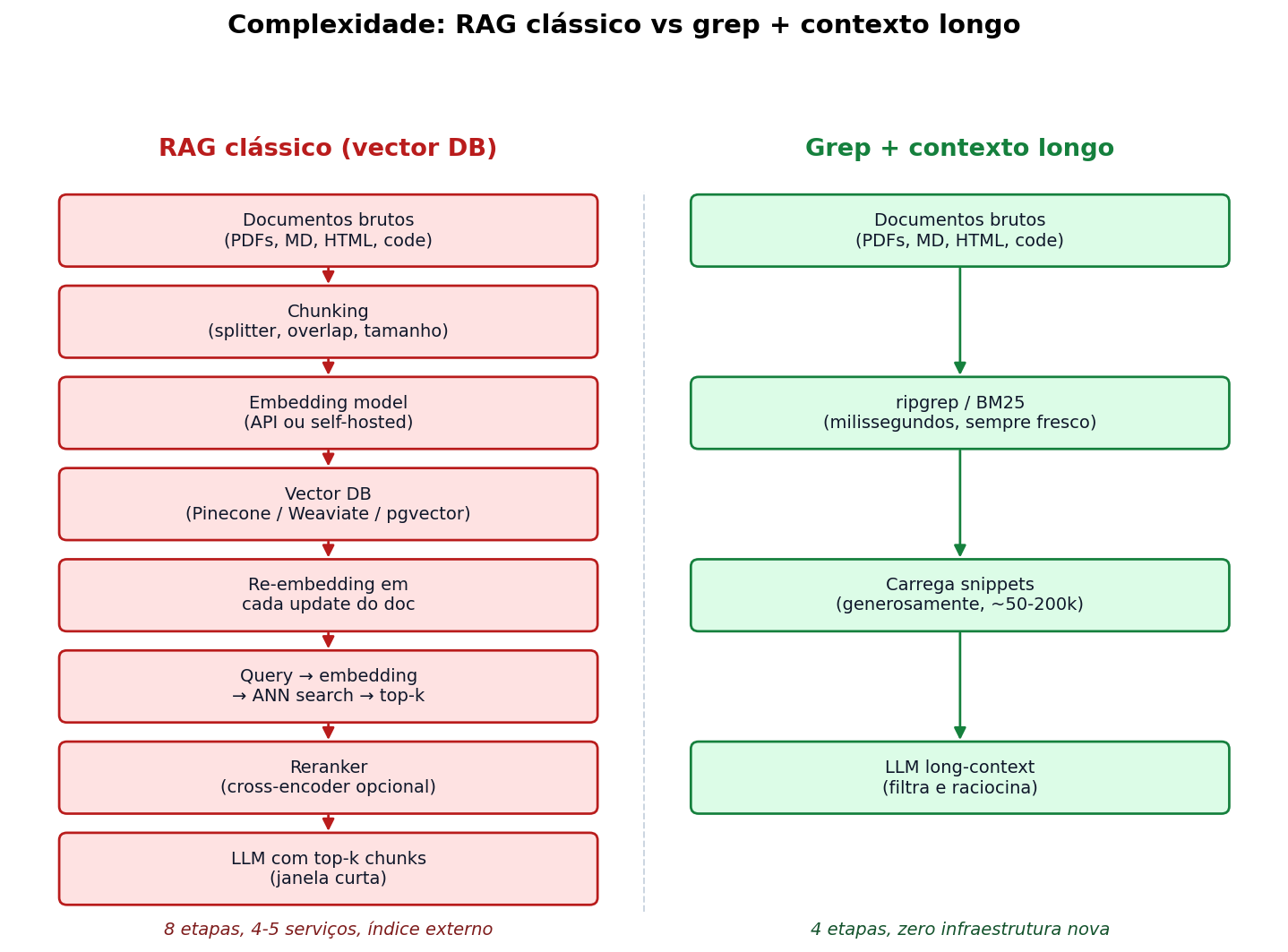
De um lado, oito etapas, quatro ou cinco serviços, índice externo que precisa ser mantido e atualizado. Do outro, quatro etapas, zero infraestrutura nova. Não é caricatura: é literalmente o que você precisa montar pra cada caso.
A pergunta honesta é: a coluna da esquerda compensa? Em 2023, sim, porque a coluna da direita não existia (não tinha LLM com janela de 200k). Em 2026, na maior parte dos casos, não.
Prós e contras de cada lado
RAG clássico (vector DB)
A favor:
- Funciona pra bases de documento gigantes, da ordem de centenas de GB, onde nem
rgresolve sem indexação prévia - Acerta consultas paráfrase pesada e cross-lingual (“como cancelo” vs “encerramento de assinatura”), onde o vocabulário do usuário não bate com o do documento
- Funciona pra modalidades não-textuais (imagem, áudio) onde grep não tem o que olhar
- Economiza tokens de input se você tá apertado de orçamento ou de latência absoluta
Contra:
- Stack complexa: embedding, vector DB, chunking, reranker, pipeline de re-indexação
- Falhas opacas, difíceis de debugar
- Chunking destrói contexto de tabelas, código, definições longas
- Overhead operacional (índice, fila, monitoramento, custo de re-embedding)
- A busca semântica vendida no marketing raramente funciona como o marketing promete
Grep + contexto longo
A favor:
- Praticamente zero infraestrutura nova: ripgrep, sqlite, ou um simples
LIKEem Postgres - Sempre fresco: o arquivo mudou, a próxima query já vê
- Falhas transparentes: a palavra está ou não está
- Carrega o documento em pedaços generosos, o modelo faz a filtragem fina com semântica de verdade
- Mais barato em dev e ops, mais barato pra pivotar de domínio
Contra:
- Não escala pra terabytes de texto bruto sem alguma indexação
- Sofre quando o usuário usa vocabulário muito diferente do documento
- Não funciona pra modalidade não-textual
- Latência por query é maior em termos absolutos (carregar 100k tokens sempre custa mais que carregar 5k)
- Custo de input por query é mais alto se você não tem prompt caching
Mas e o custo?
Esse é o argumento que mais me jogam na cara quando defendo a tese do “carrega tudo no contexto”. “Vai ficar caríssimo, 200k tokens de input por query é absurdo.” Vamos fazer a conta de verdade.
No meu artigo do benchmark de LLMs de ontem eu mapeei o preço por token de cada modelo. Pega o Claude Sonnet 4.6: $3 por milhão de tokens de input, $15 por milhão de output. Pega o GLM 5 (que provei que funciona): $0.60 input, $2.20 output. Pega o GPT 5.4 Pro lá em cima: $15 input, $180 output (esse aí machuca, eu sei).
Antes de fazer a conta de “200k tokens” em dólar, vale aterrissar isso em algo tangível, porque “100k tokens” não diz nada pra ninguém. Token, na média, é mais ou menos 0,75 palavra em inglês (em português é parecido, talvez um pouco mais por causa de palavras maiores). Então, traduzindo:
- 100k tokens ≈ 75 mil palavras ≈ um romance curto inteiro, tipo O Velho e o Mar do Hemingway com sobra, ou uns três artigos longos da Wikipedia juntos.
- 200k tokens ≈ 150 mil palavras ≈ um romance grande, tipo Crime e Castigo na íntegra, ou metade do primeiro livro de Game of Thrones (que tem ~298k palavras, daria uns 400k tokens).
- 400k tokens ≈ 300 mil palavras ≈ A Game of Thrones completo, livro 1 da série inteiro na janela.
- 1M tokens ≈ 750 mil palavras ≈ a trilogia inteira de O Senhor dos Anéis mais O Hobbit, ou a Bíblia inteira (King James ~783k palavras, daria por volta de 1M tokens), ou cerca de dois livros e meio de Game of Thrones empilhados.
Então quando eu falo “joga 200k tokens de input no modelo”, o que isso significa no mundo real é “joga Crime e Castigo inteiro como contexto da pergunta”. É muita coisa. E é exatamente isso que torna o argumento desse post viável: os modelos de hoje conseguem ler um romance inteiro de uma vez e ainda responder uma pergunta específica sobre ele. Em 2023, isso era ficção científica. Em 2026, virou o caso base.
Imagina então uma query que joga 200k tokens de input (lá vai Crime e Castigo de novo) e produz 2k tokens de output (umas três páginas de resposta):
| Modelo | Input ($) | Output ($) | Total por query |
|---|---|---|---|
| Claude Sonnet 4.6 | $0.60 | $0.03 | $0.63 |
| Claude Opus 4.6 | $3.00 | $0.15 | $3.15 |
| GLM 5 | $0.12 | $0.0044 | $0.12 |
| Gemini 3.1 Pro | $0.40 | $0.024 | $0.42 |
| GPT 5.4 Pro | $3.00 | $0.36 | $3.36 |
Agora bota prompt caching no meio. O Claude tem cache que faz o input cacheado custar uma fração do preço cheio (na ordem de 10%, dependendo do modelo). O Gemini tem mecanismo similar. Quando você faz uma sequência de queries em cima do mesmo dump de 200k tokens, o custo das queries seguintes despenca pra centavos. Com Sonnet cacheado, dá pra falar em uns $0.10 por query subsequente sem inventar muito.
Agora compara isso com o custo de manter um Pinecone, ou um Weaviate, ou um pgvector. Ignorando o preço da assinatura em si (que varia bastante), você precisa de engenheiro pra montar a pipeline, manter, monitorar, lidar com falha de embedding, refazer chunking quando o domínio muda. Conservadoramente, fala em algo entre 40 e 80 horas de engenharia pra deixar a coisa estável. A R$ 200/hora, isso é entre R$ 8.000 e R$ 16.000. Em USD, na faixa de $1.600 a $3.200 só pra colocar de pé.
Com $3.200, no Sonnet 4.6 com prompt caching, você roda algo na ordem de 30 mil queries de 200k tokens. Trinta mil queries, dependendo da escala do projeto, dão vários meses ou até um ano inteiro de uma ferramenta interna média. E você não pagou engenheiro pra montar pipeline. Não tem servidor de vector DB pra manter. Se o documento mudar, o sistema já vê na próxima query.
A conta do “RAG é mais barato em tokens” ignora que token é a coisa mais barata da equação inteira. Engenheiro custa caro, servidor custa caro, bug em produção custa muito caro. Token virou commodity, e tá ficando mais barato a cada release de modelo novo.
O argumento clássico do RAG era “modelo é caro, retrieval é barato”. Hoje é o oposto: modelo é a parte barata da pilha, retrieval inteligente é o que sai caro pra montar e manter.
Os pontos onde a tese não cola
Não quero parecer fanboy. Tem casos onde RAG clássico ainda ganha:
- Bases gigantescas. Se você tem 500 GB de texto bruto, nem
rgresolve em tempo aceitável. Aí precisa de algum tipo de indexação. Pode ser BM25 indexado (Tantivy, Elasticsearch), pode ser vector DB. Mas observa: a primeira opção ainda é lexical, não vetorial. - Vocabulário muito disperso. Suporte ao cliente, onde o usuário fala “tô sem net” e a documentação fala “perda de conectividade na camada física”. BM25 não pega isso. Embedding pega. Aí vector DB ganha o ponto.
- Modalidade não-textual. Busca de imagem por imagem, áudio por áudio. Embedding é obrigatório.
- Latência absoluta crítica. Se você precisa responder em 100ms e tem 5k de orçamento de input, dump generoso não cabe. Aí pré-filtragem é necessária.
- Compliance e auditoria. Se você precisa provar que tal documento foi consultado pra responder tal query, ter chunks indexados rastreáveis ajuda. Dump de 200k de contexto é mais opaco em auditoria.
Pra esses casos, RAG clássico continua fazendo sentido. Mas observa o tamanho da lista. São casos específicos. O caso geral, tipo “chat com nossos documentos internos” ou “pergunte ao manual do produto”, quase todo cai no balde do “grep + contexto longo resolve melhor”.
Lazy retrieval: a receita que eu defendo
Se eu fosse construir uma ferramenta de “chat com docs” hoje, do zero, seria mais ou menos assim:
- Mantém os documentos brutos. Markdown, PDF convertido, código, o que for. No disco mesmo, organizado em pastas que façam sentido pro domínio.
- Filtro lexical rápido.
ripgrepcom regex, ou BM25 com Tantivy/SQLite FTS5, ou umLIKEno Postgres se já tiver. Devolve uns 100-300 hits. - Carrega generosamente. Pega não só o trecho que bateu, mas o arquivo inteiro, ou uma janela grande em volta. Joga tudo no contexto.
- Deixa o LLM fazer a parte fina. Passa a pergunta original, manda o modelo encontrar o que importa, descartar o resto, e responder com citações.
- (Opcional) Adiciona embeddings só pra classes de query onde lexical falha, depois de você ter dados reais mostrando que falha.
Isso é o oposto do conselho antigo (“comece com vetores, fallback pra keyword”). É: comece com keyword, e adicione vetor só se sentir falta. Na maioria dos projetos, você nunca vai sentir.
Uma implementação de brinquedo em Ruby
Pra deixar concreto. Eis um script Ruby usando o gem ruby_llm (o mesmo do benchmark de ontem) que faz exatamente esse fluxo: grep nos arquivos, carrega os trechos com contexto, manda pro Claude, recebe a resposta. Sem vector DB, sem chunking, sem embedding, sem LangChain.
#!/usr/bin/env ruby
require "ruby_llm"
require "open3"
DOCS_DIR = ARGV[0] || "./docs"
QUERY = ARGV[1] or abort "uso: ./ask.rb <pasta> <pergunta>"
# 1. Filtro lexical rápido com ripgrep.
# -i case insensitive, -l só nomes de arquivo, --type-add cobre md/txt/pdf-extraído.
def lexical_search(dir, query)
terms = query.downcase.scan(/\w{4,}/).uniq.first(8) # palavras com 4+ letras
pattern = terms.join("|")
cmd = ["rg", "-l", "-i", "-e", pattern, dir]
files, _ = Open3.capture2(*cmd)
files.split("\n").reject(&:empty?)
end
# 2. Carrega os arquivos inteiros (até um teto razoável).
def load_context(files, max_chars: 600_000)
total = 0
files.map do |path|
body = File.read(path)
next if total + body.size > max_chars
total += body.size
"## #{path}\n\n#{body}\n"
end.compact.join("\n---\n")
end
# 3. Manda pro Claude com a pergunta e os documentos.
def ask(query, context)
chat = RubyLLM.chat(model: "anthropic/claude-sonnet-4-6")
prompt = <<~PROMPT
Você tem acesso aos documentos abaixo. Responda a pergunta do usuário
usando apenas o que está nos documentos. Cite o nome do arquivo nas
referências. Se a resposta não estiver nos documentos, diga isso.
--- DOCUMENTOS ---
#{context}
--- FIM DOS DOCUMENTOS ---
Pergunta: #{query}
PROMPT
chat.ask(prompt).content
end
files = lexical_search(DOCS_DIR, QUERY)
abort "nenhum arquivo bateu" if files.empty?
puts "Encontrei #{files.size} arquivos. Carregando contexto..."
context = load_context(files)
puts ask(QUERY, context)São umas 40 linhas. Sem dependência de Pinecone, sem schema de vector, sem pipeline de re-indexação. Você roda como ./ask.rb ./docs "como configurar o webhook do pagamento" e pronto.
Esse exemplo aí é one-shot. Você roda, ele responde, acabou. Pra chat de verdade, com várias perguntas em sequência em cima dos mesmos documentos, o desenho muda. Em vez de fazer o lexical_search lá no começo e empurrar tudo de uma vez pro contexto, você expõe a busca como tool pro modelo. Aí é o agente que decide quando precisa puxar mais doc, que termo vai procurar, qual arquivo vale a pena abrir inteiro. É assim que o Claude Code funciona, na real: Glob, Grep e Read são tools, e o modelo é quem escolhe a sequência. O ruby_llm suporta tool calling, então dá pra fazer a mesma coisa em Ruby. A cara fica mais ou menos assim:
require "ruby_llm"
require "open3"
DOCS_DIR = "./docs"
class SearchFiles < RubyLLM::Tool
description "Procura arquivos cujo conteúdo casa com o padrão dado (regex). Retorna lista de paths."
param :pattern, desc: "Padrão regex pra busca lexical (case-insensitive)"
def execute(pattern:)
out, _ = Open3.capture2("rg", "-l", "-i", "-e", pattern, DOCS_DIR)
out.split("\n").reject(&:empty?)
end
end
class ReadFile < RubyLLM::Tool
description "Lê o conteúdo completo de um arquivo do projeto."
param :path, desc: "Caminho relativo do arquivo"
def execute(path:)
File.read(path)
rescue => e
"erro: #{e.message}"
end
end
chat = RubyLLM.chat(model: "anthropic/claude-sonnet-4-6")
.with_tools(SearchFiles, ReadFile)
.with_instructions(<<~SYS)
Você responde perguntas sobre os documentos em #{DOCS_DIR}.
Use search_files pra encontrar arquivos relevantes e read_file
pra ler o conteúdo. Sempre cite o arquivo na resposta.
SYS
loop do
print "> "
msg = gets&.chomp
break if msg.nil? || msg.empty?
puts chat.ask(msg).content
endO modelo recebe a pergunta, decide se precisa procurar, chama search_files, vê o que voltou, decide se precisa abrir algum arquivo, chama read_file, e só depois responde. Em pergunta seguinte ele já tem o contexto anterior na sessão e pode pedir mais coisa se precisar. O contexto vai recebendo só o que o modelo pediu, não o despejo inteiro do grep que o exemplo anterior fazia.
A mesma ideia funciona pra banco de dados: troca o rg por uma query SQL com LIKE ou tsvector (full-text do Postgres), carrega as linhas relevantes, joga no contexto. Se você tiver 10k registros num banco interno, isso resolve. Se tiver 10 milhões, aí você começa a precisar de paginação inteligente ou de uma camada de pré-filtragem mais séria. Mas a estrutura mental é a mesma: filtro burro + leitor inteligente.
O ponto que importa
O mais interessante nisso tudo nem é a economia de Pinecone. É que a natureza do gargalo mudou. Em 2023, o gargalo era retrieval: o leitor era pequeno, lento, caro, e você precisava de um retriever esperto pra encher a janela com o mínimo possível. Em 2026, o gargalo é raciocínio sobre contexto bagunçado: o leitor é grande, relativamente rápido, e barato. Aí faz mais sentido um retriever burrão de alta cobertura e deixar o modelo fazer o trabalho pesado.
Quem ainda projeta sistema com a cabeça de 2023 tá pagando caro pra resolver um problema que mudou de forma. RAG não morreu, o “R” ficou mais burro e mais barato, e isso é uma melhoria. Quem vende vector DB não vai te contar, mas é o caminho que a galera mais experiente vem seguindo na surdina.
A próxima onda de aplicação LLM, na minha aposta, vai ser dominada por quem entendeu essa inversão. Stack menor, infraestrutura mais simples, contexto generoso, e muito menos LangChain.
O que a literatura recente diz
Antes de fechar, fui dar uma olhada no que a galera de pesquisa publicou sobre isso. Achismo de blog nessa área envelhece em três meses, então melhor olhar paper.
O Retrieval Augmented Generation or Long-Context LLMs?, do Google DeepMind, publicado na EMNLP 2024, é o mais citado no debate. A conclusão deles: quando o modelo tem recurso suficiente, long context bate RAG na média de qualidade, mas RAG continua sendo bem mais barato em tokens. Eles propõem o Self-Route, uma abordagem onde o próprio modelo decide se precisa do retrieval ou se manda direto pelo contexto. A economia de tokens é grande e a perda de qualidade é pequena.
Já o LaRA, apresentado na ICML 2025, é mais comedido. Os autores montaram 2326 casos de teste em quatro tipos de tarefa de QA e três tipos de contexto longo, rodaram em 11 LLMs diferentes, e a conclusão foi: não tem bala de prata. A escolha entre RAG e long context depende do modelo, do tamanho do contexto, do tipo de tarefa e da característica do retrieval. RAG ganha em diálogo e queries genéricas, long context ganha em QA estilo Wikipedia.
O Long Context vs. RAG for LLMs: An Evaluation and Revisits, de janeiro de 2025, é o que mais reforça a tese deste post. Long context costuma bater RAG nos benchmarks de QA, especialmente quando o documento base é estável. Retrieval baseado em sumarização chega perto, e retrieval baseado em chunk fica atrás. Ou seja: o jeito antigo, chunk mais embed mais top-k, é o que sai pior.
Tem que ter no radar também o original Lost in the Middle (Liu et al., 2023, publicado no TACL em 2024). Foi o paper que mostrou que mesmo modelos com janela grande têm performance dependente da posição da informação relevante. Coisa no começo ou no fim do contexto é encontrada fácil; coisa no meio degrada. Por muito tempo isso foi usado como argumento contra long context, mas o paper é de 2023, com modelos de 2023. Os modelos de hoje, tipo Claude 4.x e Gemini 3.x, lidam muito melhor com a parte do meio. Não é problema resolvido, mas é bem menor do que era.
Pelo lado de retrieval lexical, o BEIR continua sendo a referência canônica. O resultado clássico é que BM25, lá dos anos 90, segue competitivíssimo em cenário out-of-domain. Os modelos densos só ganham consistentemente quando você tem dados do próprio domínio pra fine-tunar os embeddings. Em cenário zero-shot, que é onde a maioria dos projetos vive, BM25 é difícil de bater sem trabalho pesado.
Pra fechar, o post da Anthropic sobre Contextual Retrieval, de setembro de 2024, é a peça mais prática da lista. Eles mostram que combinando embedding contextualizado com BM25 contextualizado, dá pra cair de 5.7% pra 2.9% de taxa de falha no top-20. Adicionando reranker, cai pra 1.9%. Detalhe importante: BM25 é peça central do resultado deles, não auxiliar. A leitura correta é “lexical mais vetor mais reranker é a combinação que funciona”. Quem só pode escolher um, escolhe BM25 e ainda chega longe.
Resumindo o que dá pra cravar: a literatura não diz que “RAG morreu”. Diz que long context, quando dá pra usar, costuma vencer em qualidade. Diz que o custo de RAG ainda é o argumento principal a favor dele. Diz que BM25 lexical é bem mais forte do que a propaganda de vector DB faz parecer. E diz que, quando você realmente precisa de retrieval pesado, a combinação robusta é hybrid (lexical mais vetor mais reranker), não vetor puro. Tudo isso bate com o que eu venho defendendo na prática.
Fontes
- Li, Z. et al. (2024). Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach. EMNLP 2024 Industry Track.
- Yuan, K. et al. (2025). LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs – No Silver Bullet for LC or RAG Routing. ICML 2025.
- Yu, T. et al. (2025). Long Context vs. RAG for LLMs: An Evaluation and Revisits. arXiv:2501.01880.
- Liu, N. F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. TACL 2024.
- Thakur, N. et al. (2021). BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. NeurIPS Datasets and Benchmarks 2021.
- Anthropic (2024). Introducing Contextual Retrieval. Blog técnico.
- Akita, F. (2026). O código fonte do Claude Code vazou. O que achamos dentro. — minha cobertura do leak, com mais detalhe sobre arquitetura de memória, KAIROS e
autoDream.