Testando LLMs Open Source e Comerciais - Quem Consegue Bater o Claude Opus?
TL;DR: Se você não quer ler a análise inteira: os únicos modelos que geraram código que funciona de verdade no nosso benchmark foram Claude Sonnet 4.6, Claude Opus 4.6, GLM 5 (da Z.AI, 89% mais barato que Opus), e GPT 5.4 (que falhou no benchmark por incompatibilidade com o runner, mas que testei extensivamente no Codex e funciona tão bem quanto Opus). O resto — Kimi, DeepSeek, MiniMax, Qwen, todos — inventou APIs que não existem. Se quer saber por que, continue lendo.
Se você acompanhou meus artigos anteriores sobre vibe coding, sabe que passei os últimos dois meses numa maratona de mais de 500 horas usando Claude Opus como coding agent principal. Os resultados foram bons, como reportei na conclusão sobre modelos de negócio. Mas ficou uma coceira: será que eu estou preso num único modelo? Tem alternativa real ao Claude Opus pra uso diário em projetos de verdade?
Tenho uma RTX 5090 com 32 GB de GDDR7. Sei que posso rodar os modelos open source mais recentes. Comprei um Minisforum MS-S1 com AMD Ryzen AI Max 395 e 128 GB de memória unificada, e montei um home server com Docker pra servir modelos locais. A infraestrutura estava pronta. Faltava testar de verdade.
Construí um benchmark automatizado pra comparar modelos open source e comerciais em condições idênticas. 22 modelos configurados, 16 executados, 11 completados. O código está no GitHub.
O gargalo que ninguém explica: VRAM e KV Cache
Antes de falar dos resultados, preciso explicar por que rodar modelos grandes localmente é muito mais difícil do que parece.
Pega o Qwen3 32B como exemplo. O modelo em FP16 (precisão total) ocupa ~64 GB. Quantizado em Q4 (4 bits), cai pra ~19 GB. Então cabe nos 32 GB da minha RTX 5090, certo? Errado. Esse é só o peso do modelo. Falta a parte que ninguém conta pra você: o KV Cache.
KV Cache é a memória que o modelo usa pra “lembrar” o que já leu. Cada vez que processa um token (uma palavra ou pedaço de palavra), ele calcula dois vetores — K (key) e V (value) — pra cada camada de atenção. Esses vetores ficam armazenados pra que não precise recalcular tudo quando gera o próximo token. Sem isso, a geração seria quadraticamente lenta.
O KV Cache escala linearmente com o tamanho do contexto. A fórmula:
Memória KV = 2 × Camadas × Cabeças_KV × Dimensão_Cabeça × Bytes_por_Elemento × Tokens_no_ContextoPra um modelo como o Llama 3.1 70B em BF16, isso dá ~0.31 MB por token. Parece pouco, até você perceber que um contexto de 128K tokens consome 40 GB só de KV Cache. O modelo em si + KV Cache = muito mais VRAM do que a maioria das GPUs tem.
E pra uso real com coding agents, 128K tokens não é luxo — é necessidade. O agent precisa ler arquivos, manter histórico de conversação, receber output de comandos. Em sessões longas de benchmark, nossos modelos consumiram entre 39K e 156K tokens. Menos de 100K de contexto não é prático pra projetos do dia a dia.
O Google publicou o TurboQuant (ICLR 2026), que comprime o KV Cache pra 3 bits sem perda de acurácia — redução de 6x na memória e até 8x de speedup. Usa rotação aleatória de vetores (PolarQuant) seguida de um algoritmo de 1 bit nos resíduos. Funciona online durante inferência, comprimindo na escrita e descomprimindo na leitura. Ainda não está implementado nos runtimes que usamos (llama.cpp, Ollama), mas quando chegar vai mudar bastante a equação.
Pra quem quer se aprofundar nessa matemática de VRAM, recomendo este link do Ahmad Osman pro artigo “GPU Memory Math for LLMs (2026 Edition)”.
O problema do hardware: memória não é toda igual
“Mas eu tenho 128 GB de RAM!” Legal, mas não é isso que importa. O que importa é largura de banda de memória, e a diferença entre tipos é absurda:
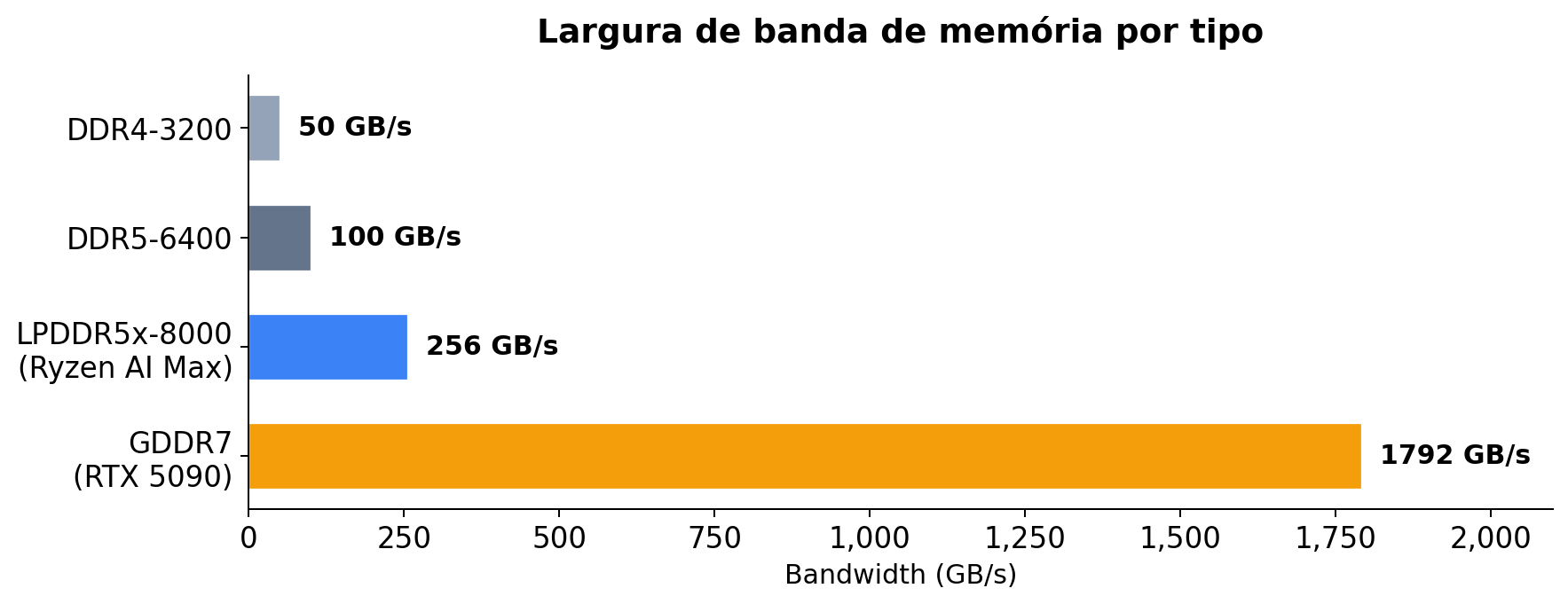
A RTX 5090 tem 7x mais bandwidth que a memória LPDDR5x do meu Minisforum. Isso significa que mesmo que o modelo caiba na RAM unificada do AMD, a inferência vai ser proporcionalmente mais lenta. No meu Minisforum com LPDDR5x a 256 GB/s, o Qwen3 32B roda a ~7 tok/s. Na RTX 5090 a 1.792 GB/s, seria muito mais rápido — se coubesse inteiro na VRAM junto com o KV Cache.
A maioria das pessoas rodando modelos locais ainda está em DDR4. A 50 GB/s, modelos de 32B ficam praticamente unusáveis. E tem outro fator que pouca gente lembra: storage. Quando a RAM não dá conta e o sistema faz swap, a velocidade do armazenamento vira o gargalo:
| Storage | Velocidade Sequencial |
|---|---|
| SATA SSD | ~550 MB/s |
| NVMe Gen3 | ~3.500 MB/s |
| NVMe Gen4 | ~7.000 MB/s |
| NVMe Gen5 | ~12.000 MB/s |
De SATA pra NVMe Gen5 são 22x de diferença. Se você está fazendo offloading parcial pro disco (comum quando o modelo não cabe inteiro na GPU), NVMe Gen4 ou Gen5 faz diferença real. SATA é inviável.
Resumindo: rodar modelos locais não é só “ter RAM suficiente”. Precisa do tipo certo de memória, com a bandwidth certa, e storage rápido como fallback. Pra muita gente, um Mac Studio com memória unificada de alta bandwidth (até 800 GB/s nos M4 Ultra com 512 GB) seria a opção mais prática, mas custa mais de US$ 10.000. O AMD Ryzen AI Max é a alternativa mais acessível com memória unificada, mas o LPDDR5 fica limitado a 256 GB/s.
Ollama vs llama.cpp: por que o Ollama falha pra benchmarks
O Ollama é a forma mais popular de rodar modelos locais. Instala, puxa o modelo, roda. Pra uso casual funciona. Mas quando tentei usar pra benchmarks automatizados, sessões longas sem intervenção humana, quebrou de 6 formas diferentes em 8 modelos:
- Descarrega o modelo no meio da sessão. Em runs longos, o Ollama decide que o modelo não está sendo usado e descarrega da GPU. O agent fica esperando resposta de um modelo que não existe mais.
- Ignora o contexto solicitado. Você pede
num_ctx=131072, o Ollama aceita, e no meio do run reverte pro padrão sem avisar. - Lifecycle instável. Pedir
keep_alive: 0pra descarregar nem sempre funciona. O modelo fica residente e bloqueia o próximo. - Formatos incompatíveis. Variantes bf16 nativas do Ollama falhavam, enquanto o mesmo modelo como GGUF Q8 do HuggingFace funcionava sem problemas.
A solução: migrar pro llama-swap, um wrapper Go que gerencia processos llama.cpp com hot-swap. Chega um request pra um modelo diferente do que está carregado, ele mata o processo atual e inicia o novo. Sem negociação de contexto, sem lifecycle instável.
O llama-swap resolveu o carregamento de 6 dos 8 modelos que falharam no Ollama:
| Modelo | Ollama | llama-swap |
|---|---|---|
| Gemma 4 27B | HTTP 500 | 47.6 tok/s |
| GLM 4.7 Flash | Sem output | 47.4 tok/s |
| Llama 4 Scout | Descarregou | 17.5 tok/s |
| Qwen 3.5 35B | Output off-spec | 49.7 tok/s |
| Qwen 3.5 122B | Context drift | 23.1 tok/s |
| GPT OSS 20B | Model not found | 78.3 tok/s |
Mas o llama-swap não é mágico.
Por que “só usar llama.cpp” não resolve tudo
O llama.cpp resolve os problemas de lifecycle do Ollama mas traz os próprios:
Cada modelo precisa de flags específicas. GLM e Qwen 3.5 emitem <think> tags que quebram clientes se você não passar --reasoning-format none. Gemma 4 precisa de build b8665+ pro parser de tool calls funcionar.
Nem todo modelo suporta tool calling. O llama.cpp precisa de um parser dedicado pro formato de tool call de cada modelo. O Llama 4 Scout usa um formato “pythonic” ([func(param="value")]) que o llama.cpp simplesmente não parseia, emite como texto puro. O vLLM tem parser pra isso, o llama.cpp não.
E tem os repetition loops. O Gemma 4, mesmo com o parser certo, entra em loop infinito depois de ~11 tool calls em sessões longas. É um bug conhecido que o PR #21418 não resolveu completamente.
Compatibilidade de tool calling por modelo:
| Modelo | Tool Calling | Flags Necessárias | Resultado no Benchmark |
|---|---|---|---|
| Gemma 4 27B | Parcial (b8665+) | --jinja --reasoning-format none | Loop infinito após ~11 steps |
| GLM 4.7 Flash | Sim | --jinja --reasoning-format none | 2029 arquivos, terminou mid-tool-call |
| Qwen 3.5 (35B, 122B) | Sim | --jinja --reasoning-format none | Completou com sucesso |
| Qwen 3 Coder Next | Sim | --jinja | Completou (melhor resultado local) |
| GPT OSS 20B | Sim | --jinja | Tool calls ok, mas app no diretório errado |
| Llama 4 Scout | Não | — | Sem parser no llama.cpp |
No fim das contas, llama.cpp é melhor que Ollama pra runs automatizados, mas “plug and play” não é. Cada modelo exige configuração específica, e alguns simplesmente não funcionam pra agentic coding ainda.
Reasoning: modelos que pensam vs modelos que chutam
Tem uma diferença entre modelos que vale explicar: reasoning. A ideia é que o modelo “pensa antes de responder” em vez de gerar tokens direto da esquerda pra direita. Modelos com reasoning fazem uma etapa interna de cadeia de pensamento (chain-of-thought) onde avaliam o problema, consideram alternativas, planejam, e só depois emitem a resposta.
Na prática, isso aparece como <think>...</think> tags no output, blocos de texto que o modelo gera pra si mesmo, que não devem ir pro usuário final. Claude Opus 4.6, GPT 5.4, DeepSeek V3.2 e a linha Qwen 3.5 suportam reasoning nativamente. Os menores (Gemma 4, GPT OSS 20B, modelos mais antigos) não têm essa capacidade.
Por que importa pra coding? Quando um coding agent recebe “construa um app Rails com 9 componentes”, ele precisa decompor a tarefa em passos, decidir a ordem, antecipar dependências, adaptar quando algo falha. Sem reasoning, o modelo gera código sequencialmente sem planejamento. Funciona pra tarefas simples, desmorona em projetos com partes interdependentes.
No benchmark, a diferença ficou clara:
- GPT OSS 20B (sem reasoning, 20B parâmetros) criou o app no diretório errado. Não conseguiu manter o contexto das instruções de workspace enquanto gerava código.
- Qwen 3 32B tem reasoning, mas a 7 tok/s era lento demais. Os tokens de “pensamento” aumentam o tempo de geração.
- Gemma 4 31B, sem reasoning treinado pra uso agentic, entrou em loops repetitivos de tool calling.
- GLM 5 (cloud, 745B MoE) com reasoning e 44B parâmetros ativos, completou limpo e usou a API correta.
Tem um trade-off: reasoning consome tokens extras (os <think> blocks), que ocupam VRAM no KV Cache e desaceleram a geração. Por isso flags como --reasoning-format none são necessárias no llama.cpp. Alguns clientes não sabem o que fazer com reasoning tokens e quebram. Modelos que emitem reasoning sem que o runtime espere podem gerar lixo no output.
E reasoning não é algo que você “liga” num modelo qualquer. É uma capacidade treinada com reinforcement learning em cima do modelo base, usando dados de problemas que exigem raciocínio multi-step. Os modelos open source menores (20B-35B) tipicamente não passaram por esse treinamento, ou passaram em escala menor. Eles sabem gerar código, mas não sabem planejar código. Em tarefas que exigem 50+ tool calls coordenadas, essa diferença mata.
O benchmark: metodologia
Pra comparar modelos de forma justa, construí um harness automatizado em Python. Cada modelo recebe exatamente o mesmo prompt: construir uma aplicação Ruby on Rails completa, um chat SPA tipo ChatGPT usando o gem RubyLLM, com Hotwire/Stimulus/Turbo Streams, Tailwind CSS, testes Minitest, ferramentas de CI (Brakeman, RuboCop, SimpleCov, bundle-audit), Dockerfile, docker-compose e README.
O runner é o opencode, que na época do benchmark era a CLI de coding open source mais popular, competindo com Claude Code e Codex. Desde então, o projeto foi arquivado e o desenvolvimento continuou como Crush, mantido pelo autor original junto com a equipe da Charm (o pessoal por trás do Bubble Tea, Lip Gloss e várias outras ferramentas de terminal em Go). Se você leu meu artigo sobre o Crush, já conhece. O Crush herda tudo do opencode — suporte a 75+ provedores, LSP, MCP, sessões persistentes — e adiciona a estética caprichada que é marca da Charm. Roda em tudo: macOS, Linux, Windows, Android, FreeBSD.
Na verdade, tentei usar o Crush primeiro pro benchmark. O problema: ele anunciava uma flag --yolo no help pra auto-aprovar todas as ações (essencial pra runs automatizados sem intervenção humana), mas na hora de rodar, rejeitava a flag. Sem auto-approve, não dá pra fazer benchmark desacompanhado. O opencode, por outro lado, tinha o modo opencode run --agent build --format json que emite eventos JSON com session IDs e contagem de tokens, perfeito pra automação. Então ficamos com o opencode.
Escolhi o opencode (e não Claude Code ou Codex) por dois motivos:
- Neutralidade. Claude Code é otimizado pra modelos Anthropic. Codex é otimizado pra modelos OpenAI. O opencode é agnóstico, mesma interface pra todos.
- Automação. O opencode expõe um formato JSON legível por máquina. Claude Code e Codex não têm interface equivalente pra benchmarking externo.
Modelos cloud rodaram em duas fases: fase 1 (construir o app) e fase 2 (validar boot local, docker build, docker compose). Modelos locais rodaram só fase 1.
Detalhe que vale mencionar: o benchmark inteiro custou menos de $10 em tokens no OpenRouter. Tirando o GPT 5.4 Pro que torrou $7.20 pra falhar, os outros 10 modelos cloud somaram uns $2 no total. Modelos locais custam só eletricidade. O ponto é: rodar seu próprio benchmark é barato. Se você quer saber se um modelo funciona pro seu caso de uso, gaste os $2 e teste. O código do harness está no GitHub, é só trocar o prompt pelo seu projeto.
Por que o GPT 5.4 falhou no benchmark (mas não na vida real)
O GPT 5.4 Pro é o único modelo cloud que falhou consistentemente no nosso benchmark. Duas runs separadas, mesmo resultado: o modelo gerou arquivos mas nunca chegou a finish_reason: stop. Sempre terminava com finish_reason: tool-calls — queria continuar chamando tools mas o loop se quebrava.
Pra quem não sabe: tool calling é quando um LLM precisa executar uma ação (ler um arquivo, rodar um comando, editar código) e emite uma “chamada de ferramenta” num formato estruturado. O client (opencode, Claude Code, Codex) interpreta, executa, e devolve o resultado pro modelo. Cada provedor tem seu formato: a Anthropic usa tool_use blocks, a OpenAI usa function_calling com JSON schemas, o Google usa FunctionCall.
O GPT 5.4 é fortemente treinado pro formato nativo de function calling da OpenAI — tool_choice, tools com JSON schemas proprietários. Quando o benchmark rota por opencode → OpenRouter → GPT 5.4, os schemas de tools são traduzidos em cada hop. Se o GPT emite tool calls num formato que o OpenRouter ou opencode não parseia corretamente, o loop do agent quebra.
A evidência: todos os outros modelos cloud (Claude Opus, Claude Sonnet, Kimi K2.5, DeepSeek V3.2, MiniMax M2.7, GLM 5, Qwen 3.6 Plus, Step 3.5 Flash) terminaram com finish_reason: stop. Só o GPT termina com finish_reason: tool-calls.
Comparação justa do GPT 5.4 exigiria rodar no ambiente nativo — Codex ou ChatGPT Pro ($200/mês). No opencode pelo OpenRouter, não é um teste justo da capacidade de coding do GPT. Dito isso, eu usei bastante o Codex na minha maratona de vibe coding e posso atestar que o GPT 5.4 é tão bom quanto o Opus pra projetos reais. Aliás, em alguns aspectos prefiro o Codex: ele tende a pensar mais “fora da caixa” e chegar em soluções mais criativas que o Opus. Por outro lado, ele é menos disciplinado — tende a esquecer instruções anteriores em sessões longas e às vezes sai do escopo do que foi pedido. O Opus é mais previsível e metódico. Pra mim, essa previsibilidade vale mais no dia a dia.
O Sonnet e o Opus via opencode/OpenRouter também provavelmente não foram usados ao máximo da capacidade. O Claude Code oferece suporte nativo de tools que o opencode não replica — o que significa que os resultados do benchmark representam um piso, não um teto, pra esses modelos.
Modelos open source: a realidade vs a narrativa
Tem muita gente dizendo que modelos open source já alcançaram os comerciais e que dá pra rodar seu próprio “Claude” em casa. Na prática, não é bem assim.
A escala não é comparável. Modelos frontier como Claude Opus 4.6 e GPT 5.4 são closed-source, mas estimativas indicam que estão na faixa de centenas de bilhões a trilhões de parâmetros, treinados com compute e dados que nenhuma empresa open source replica. Os melhores modelos que cabem num hardware razoável são:
| Modelo | Parâmetros Totais | Parâmetros Ativos | Arquitetura |
|---|---|---|---|
| Qwen 3.5 35B | 35B | 35B | Dense |
| Qwen 3 32B | 32B | 32B | Dense |
| Qwen 3.5 122B | 122B | 122B | Dense |
| GPT OSS 20B | 20B | 20B | Dense |
| Gemma 4 31B | 31B | 31B | Dense |
Mesmo os maiores modelos open source MoE (Mixture of Experts) que as empresas disponibilizam publicamente ativam poucos parâmetros por token:
| Modelo | Parâmetros Totais | Parâmetros Ativos | Notas |
|---|---|---|---|
| Kimi K2.5 | 1T | 32B | 384 experts, top-8 + shared |
| GLM 5 | 745B | 44B | 256 experts, 8 ativados |
| DeepSeek V3.2 | 671B | 37B | Sparse Attention |
| Qwen 3.5 397B | 397B | 17B | MoE, cloud-only |
Esses modelos grandes não são self-hostáveis. O Kimi K2.5 com 1T parâmetros precisa de clusters de GPUs com centenas de GBs de VRAM. O GLM 5 com 745B idem. Mesmo que a Alibaba ou a Z.AI liberem os pesos (e algumas liberam), ninguém tem hardware doméstico pra rodar eles.
O que cabe na sua GPU doméstica são os modelos de 20B-35B — e esses têm limitações reais.
O que cada modelo local fez no benchmark
Qwen 3 Coder Next (30B) — Melhor resultado local. Completou em 17 minutos, gerou 1675 arquivos, app Rails com todos os artefatos. Mas só 3 testes. E o mais importante: inventou RubyLLM::Client.new, uma classe que não existe no gem. O app não roda.
Qwen 3.5 35B — Completou em 28 minutos, 1478 arquivos, 11 testes. Usou RubyLLM.chat sem parâmetro de modelo — funciona só se o default estiver configurado. Sem mocking de LLM nos testes.
Qwen 3.5 122B — Completou em 43 minutos, 1503 arquivos, 16 testes. Mas ignorou o gem RubyLLM completamente e construiu um cliente HTTP customizado pro OpenRouter. O prompt pedia explicitamente pra usar ruby_llm.
GLM 4.7 Flash (local) — Produziu 2029 arquivos com todos os artefatos, mas a sessão terminou mid-tool-call. O modelo cloud (GLM 5) funciona perfeitamente.
Gemma 4 31B — Loop infinito de tool calls depois de ~11 steps produtivos. Bug conhecido do llama.cpp.
GPT OSS 20B — Criou o app Rails no diretório errado (project/app/ em vez de project/). Um modelo de 20B não segue instruções de workspace de forma confiável.
Qwen 3 32B — Lento demais (7.3 tok/s). Hardware não dá conta.
Modelos cloud: o que funciona de verdade
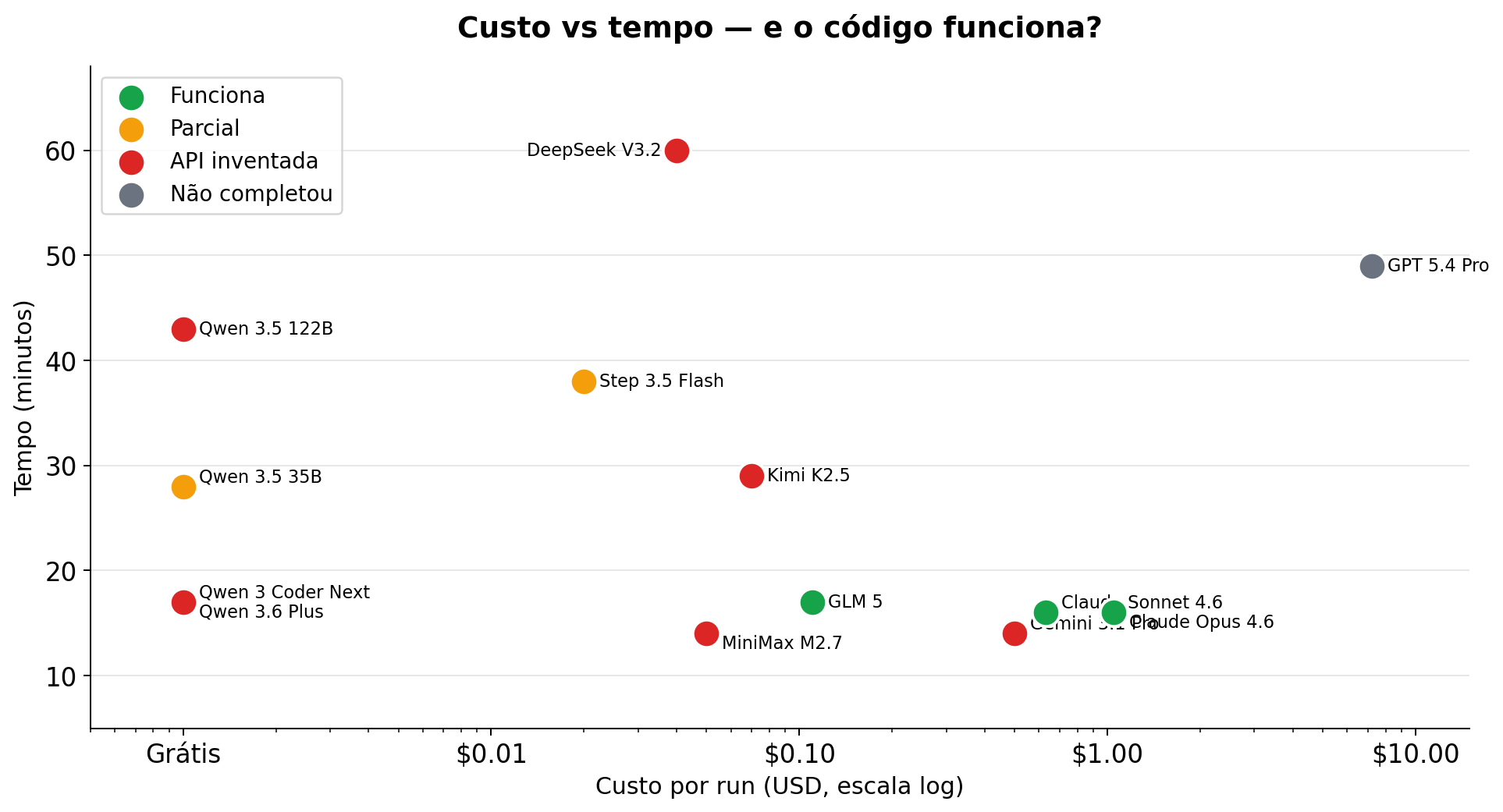
Dos 11 modelos que completaram o benchmark, todos geraram um projeto Rails reconhecível com todos os artefatos pedidos (Gemfile, routes, views, JS, testes, README, Dockerfile, docker-compose). 9 de 9 no checklist de completude.
Mas aí vem a pergunta que importa: o código roda?
A API correta do RubyLLM é simples:
chat = RubyLLM.chat(model: "anthropic/claude-sonnet-4")
response = chat.ask("Hello")
response.content # => "Hi there!"7 dos 11 modelos inventaram APIs que não existem. O padrão mais comum: alucinação de uma interface estilo SDK do Python da OpenAI:
| Modelo | O que Inventou |
|---|---|
| DeepSeek V3.2 | RubyLLM::Client.new — classe inexistente |
| Qwen 3 Coder Next | RubyLLM::Client.new — mesmo erro |
| Qwen 3.5 122B | Openrouter::Client — gem inexistente |
| Kimi K2.5 | add_message() e complete() — métodos inexistentes |
| MiniMax M2.7 | RubyLLM.chat(messages: [...]) — assinatura inexistente |
| Qwen 3.6 Plus | chat.add_message() — método inexistente |
Os modelos que acertaram — os dois Claudes e o GLM 5 — usaram o padrão simples de duas etapas (chat = RubyLLM.chat(model:) depois chat.ask(message)). Os que erraram tentaram fazer o RubyLLM parecer com o SDK Python da OpenAI, que é outra coisa.
E os testes? Só Opus, Sonnet e GLM 5 fizeram mocking correto das chamadas LLM. Todos os outros ou batiam na API real (que falha sem chave) ou mockavam a API inventada (testes passam mas não provam nada). Contagem de testes é uma métrica enganosa: o Kimi K2.5 escreveu 37 testes, mais que qualquer outro, mas nenhum testa a funcionalidade real porque a API que ele usa não existe.
Tabela de viabilidade real
| Modelo | API Correta? | Roda? | Mocking nos Testes? | Problema |
|---|---|---|---|---|
| Claude Sonnet 4.6 | Sim | Sim | Sim (mocha) | Implementação limpa |
| Claude Opus 4.6 | Sim | Sim | Sim (mocha) | Implementação limpa |
| GLM 5 | Sim | Sim | Sim (mocha) | API correta, funciona |
| Step 3.5 Flash | N/A | Sim* | Não | Bypassa RubyLLM, usa HTTP direto |
| Qwen 3.6 Plus | Parcial | Só 1ª msg | Não | add_message() não existe |
| Qwen 3.5 35B | Parcial | Talvez | Não | Sem parâmetro de modelo |
| Kimi K2.5 | Não | Não | Não | add_message()/complete() inventados |
| MiniMax M2.7 | Não | Não | Não | Assinatura de RubyLLM.chat errada |
| DeepSeek V3.2 | Não | Não | Não | RubyLLM::Client inexistente |
| Qwen 3 Coder Next | Não | Não | Não | RubyLLM::Client inexistente |
| Qwen 3.5 122B | Não | Não | Não | Openrouter::Client gem inexistente |
*Step 3.5 Flash funciona chamando a API REST do OpenRouter direto com Net::HTTP, contornando completamente o gem que o prompt pedia.
Agora, isso não quer dizer que esses modelos são inúteis. Se você pegar o Kimi K2.5 ou o DeepSeek V3.2 e mandar “a classe RubyLLM::Client não existe, corrija pra usar a API real do gem”, provavelmente vai corrigir. Um ou dois follow-ups e o projeto fica funcional. A maioria dos modelos que falharam aqui conseguiria entregar um projeto rodando com mais algumas rodadas de conversa.
Só que aí está o trade-off. Com Opus ou GPT 5.4, o primeiro output já funciona. Pede, entrega, testa, roda. Com os modelos mais baratos, você vai gastar tempo corrigindo alucinações de API, debugando código que “parece certo” mas crasha, guiando o modelo na direção certa. Cada rodada dessas são 10-30 minutos. Três rodadas extras e você gastou uma hora do seu tempo pra economizar $0.90 de tokens.
Economiza dólar, gasta tempo. E tempo é dinheiro. Pra quem está aprendendo ou explorando sem pressa, essa troca pode fazer sentido. Pra quem precisa entregar, os modelos frontier se pagam rápido.
Comparação dos modelos que funcionam
| Modelo | Provedor | Tempo | Testes | Custo/Run | vs Opus |
|---|---|---|---|---|---|
| Claude Sonnet 4.6 | OpenRouter | 16m | 30 | ~$0.63 | 40% mais barato, mais testes |
| Claude Opus 4.6 | OpenRouter | 16m | 16 | ~$1.05 | Baseline |
| GLM 5 | OpenRouter | 17m | 7 | ~$0.11 | 89% mais barato |
Ranking completo por tempo e tokens
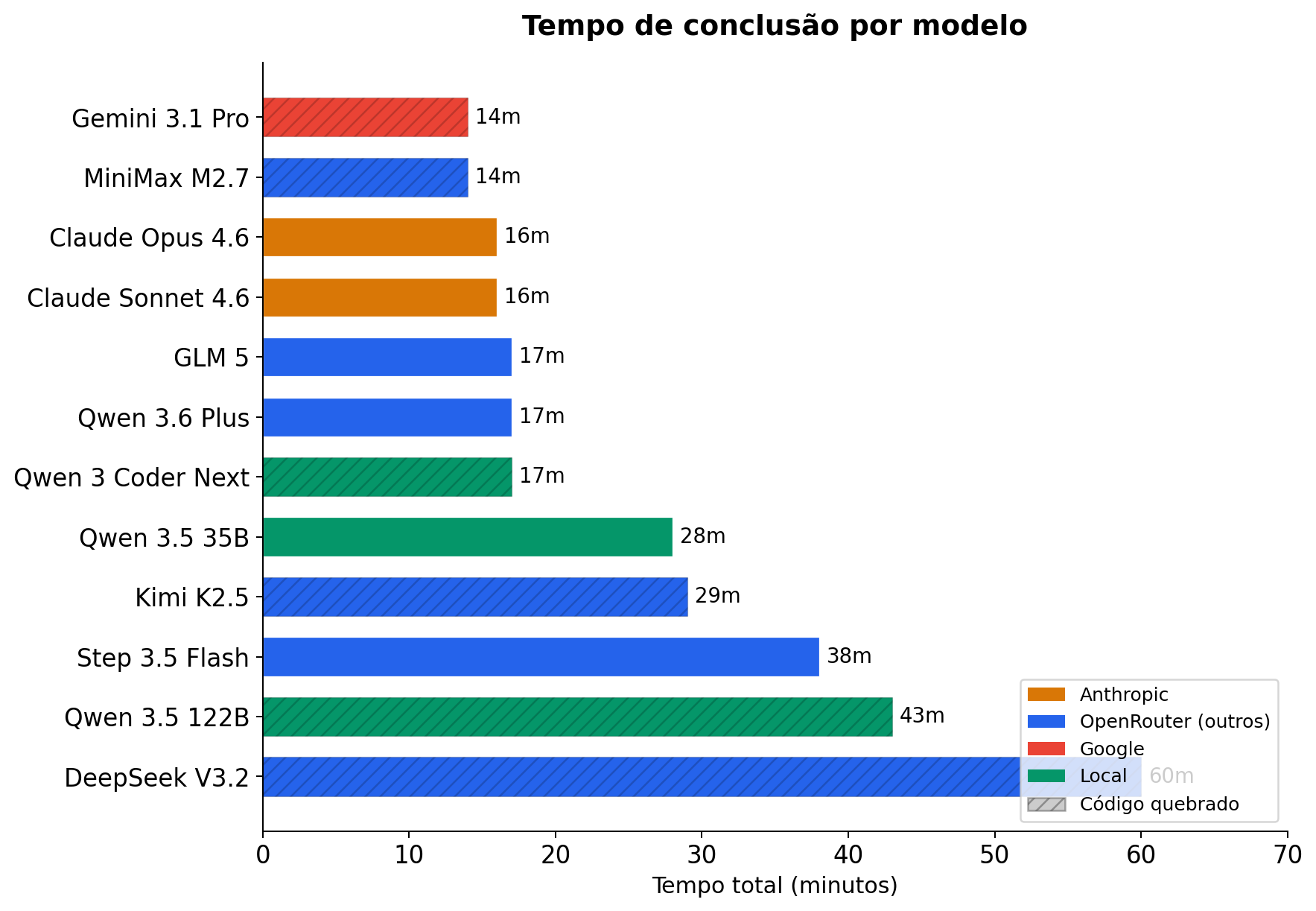
| Modelo | Provedor | Tempo | Tokens Totais | Tok/s | Custo/Run |
|---|---|---|---|---|---|
| MiniMax M2.7 | OpenRouter | 14m | 79.743 | 574.52 | ~$0.05 |
| Claude Opus 4.6 | OpenRouter | 16m | 136.806 | 347.18 | ~$1.05 |
| Claude Sonnet 4.6 | OpenRouter | 16m | 127.067 | 532.26 | ~$0.63 |
| GLM 5 | OpenRouter | 17m | 59.378 | 400.01 | ~$0.11 |
| Qwen 3.6 Plus | OpenRouter | 17m | 88.940 | 182.91 | Grátis |
| Qwen 3 Coder Next | Local | 17m | 39.054 | 37.49 | Eletricidade |
| Qwen 3.5 35B | Local | 28m | 76.919 | 46.03 | Eletricidade |
| Kimi K2.5 | OpenRouter | 29m | 63.638 | 160.14 | ~$0.07 |
| Step 3.5 Flash | OpenRouter | 38m | 156.267 | 242.11 | ~$0.02 |
| Qwen 3.5 122B | Local | 43m | 57.472 | 22.41 | Eletricidade |
| DeepSeek V3.2 | OpenRouter | 60m | 115.278 | 53.37 | ~$0.04 |
O DeepSeek V3.2 é o mais lento apesar de ser cloud — não tem prompt caching, então reenvia o contexto completo a cada turno.
Eficiência de tokens e cache
Modelos com prompt caching pagam muito menos tokens efetivos:
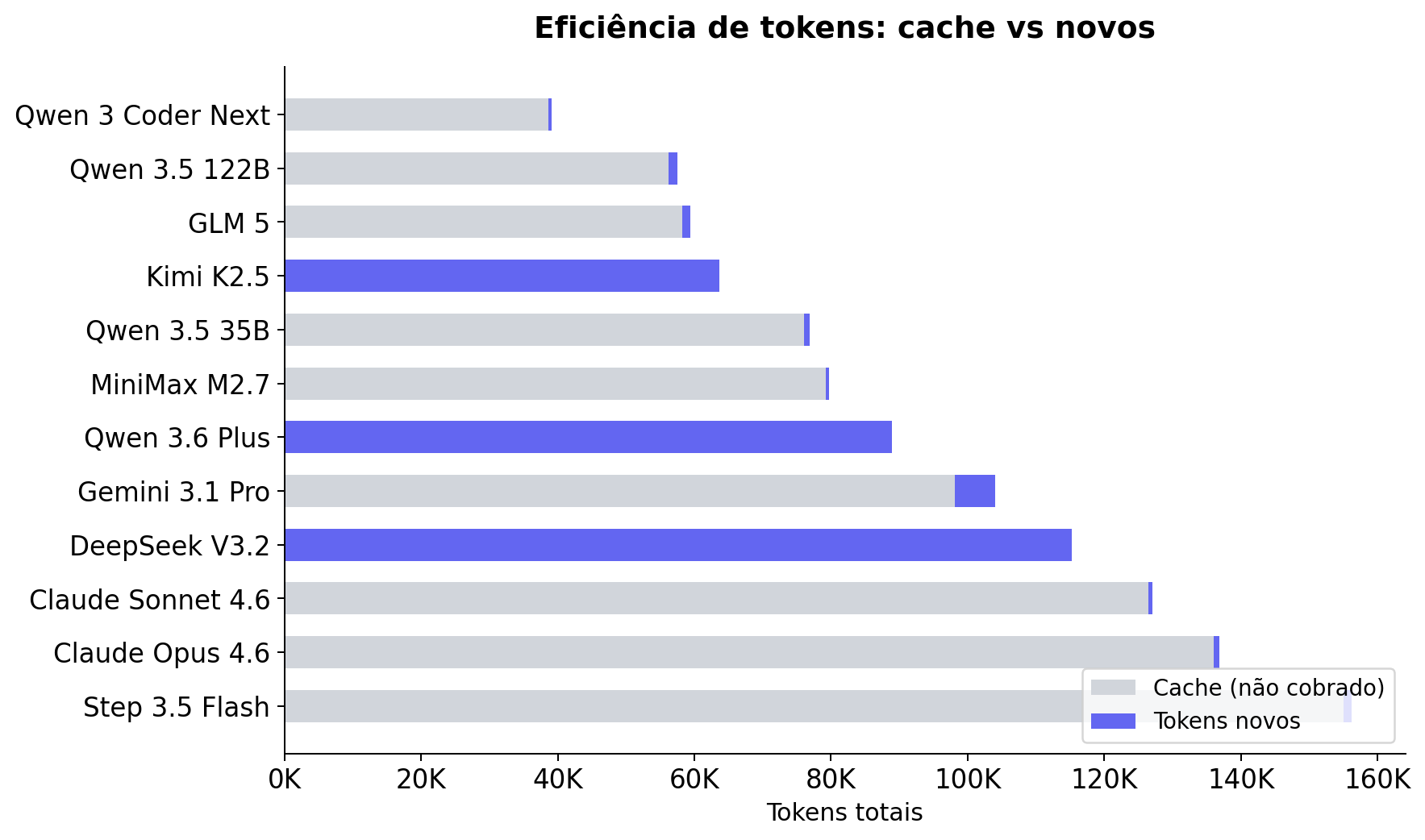
| Modelo | Tokens Totais | Cache Lido | Tokens Novos Efetivos |
|---|---|---|---|
| Claude Sonnet 4.6 | 127.067 | 126.429 | 638 |
| Claude Opus 4.6 | 136.806 | 135.976 | 830 |
| GLM 5 | 59.378 | 58.240 | 1.138 |
| DeepSeek V3.2 | 115.278 | 0 | 115.278 |
| Kimi K2.5 | 63.638 | 0 | 63.638 |
Velocidade: o abismo entre cloud e local
Tem um aspecto que as tabelas de custo escondem: velocidade de inferência. E a diferença é brutal.
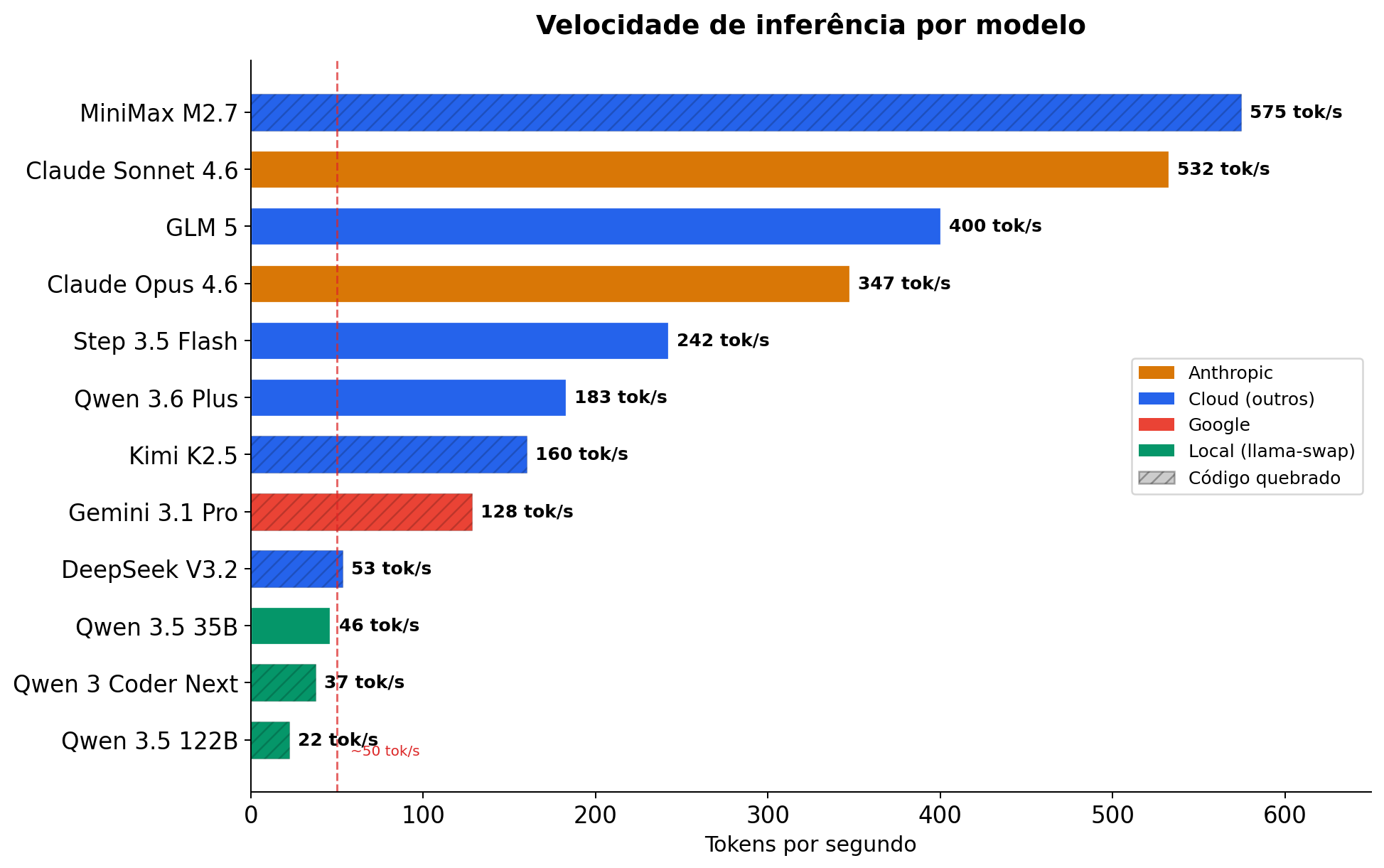
O Claude Sonnet gera 532 tok/s. O Qwen 3.5 122B rodando local no meu Minisforum gera 22 tok/s. São 24x de diferença. Na prática, o que o Sonnet faz em 16 minutos, o Qwen 3.5 122B leva 43 minutos. O Qwen 3 Coder Next a 37 tok/s é o mais rápido dos locais e mesmo assim é 14x mais lento que o Sonnet.
E não é só tempo de relógio. Quando você está num loop de coding interativo — pede uma mudança, espera o output, testa, pede outra — a velocidade do modelo define seu ritmo. A 37 tok/s, cada resposta longa te faz esperar 30-60 segundos. A 530 tok/s, aparece quase instantaneamente. Ao longo de um dia, você sente.
O DeepSeek V3.2 é um caso curioso: é cloud mas roda a 53 tok/s, mais lento que o Qwen 3.5 35B local (46 tok/s). O motivo é que o DeepSeek não tem prompt caching — reenvia o contexto completo a cada turno, estrangulando o throughput. Pagar por um modelo cloud mais lento que rodar local não faz sentido nenhum.
Modelos locais são grátis em tokens, mas pagam em tempo. Se sua hora vale mais que uns centavos, a conta é óbvia.
O Deep Code Review: Sonnet vs GLM 5 vs Kimi vs MiniMax
As tabelas acima medem completude estrutural. Mas o projeto funciona? Fiz code review detalhado dos modelos que completaram o benchmark.
Claude Sonnet 4.6 — funciona e é o mais completo. Respostas síncronas via Turbo Stream. Histórico de chat persistido em session cookie com replay completo das mensagens anteriores a cada request. Mocking correto do LLM nos testes com mocha (30 testes em 328 linhas). Lógica de LLM extraída pra um LlmChatService separado. Views decompostas em 9 partials. Problemas menores: constante de modelo duplicada, leak no event listener do auto-resize. Nenhum é blocker. Dos projetos gerados, é o que mais se aproxima de algo que você colocaria em produção.
GLM 5 — funciona, mas é o mínimo viável. Usa a API correta (RubyLLM.chat(model:) depois .ask()), faz mocking com mocha nos testes. Só que o projeto é bem mais enxuto que o do Sonnet: controller de 21 linhas (vs 52 do Sonnet), sem service layer (lógica LLM inline no controller), sem persistência de histórico de chat, cada mensagem tratada isoladamente. A primeira mensagem funciona, mas o app não mantém contexto de conversação, então não dá pra ter um diálogo multi-turn. Os testes existem (7 métodos) mas são esqueléticos: o ruby_llm_test.rb só checa se o módulo está carregado, o chat_flow_test.rb é cópia do controller test. O Dockerfile, por outro lado, é o melhor dos quatro: multi-stage, non-root, jemalloc. Mas como app de chat? É mais uma prova de conceito do que algo funcional. Detalhe engraçado: o README diz “Powered by Claude Sonnet 4” em vez do modelo que realmente gerou o projeto.
Kimi K2.5 — ambicioso mas quebrado. Tentou a arquitetura mais sofisticada: ActionCable streaming, modelos configuráveis, dual Dockerfiles, 37 testes em 374 linhas. Problema: o streaming depende do ActionCable, que está comentado no config/application.rb. O guard return unless defined?(ActionCable) faz o método não fazer nada. O assistente nunca responde. O Stimulus controller tem bug de escopo: o submitTarget referencia um botão fora da subtree do controller. Storage thread-unsafe com hash em variável de classe. O Kimi escreveu mais testes que qualquer outro modelo (37), mas nenhum mocka as chamadas LLM — então os testes passam sem provar que a funcionalidade funciona de verdade.
MiniMax M2.7 — parece certo, crasha. Chama RubyLLM.chat(model: '...', messages: [...]) — essa assinatura não existe. Sem persistência de mensagens. HTML duplicado (DOCTYPE dentro do layout). master.key commitada. E os testes? Mockam a API errada, então passam mas não provam nada.
Resumo do code review:
| Aspecto | Sonnet 4.6 | GLM 5 | Kimi K2.5 | MiniMax M2.7 |
|---|---|---|---|---|
| API correta | Sim | Sim | Não | Não |
| Histórico de chat | Session cookie | Nenhum | Broken (ActionCable off) | Nenhum |
| Service layer | LlmChatService | Inline no controller | LlmService | ChatService (API errada) |
| Testes (métodos) | 30 | 7 | 37 | 12 |
| Mocking LLM | Sim (mocha) | Sim (mocha) | Não | Mock da API errada |
| Dockerfile | Multi-stage | Multi-stage + jemalloc | Dual (dev/prod) | Single-stage |
| Roda de verdade? | Sim | Sim (sem histórico) | Não | Não |
Custos: API vs Assinatura
Primeiro, o preço por token de cada modelo no OpenRouter:
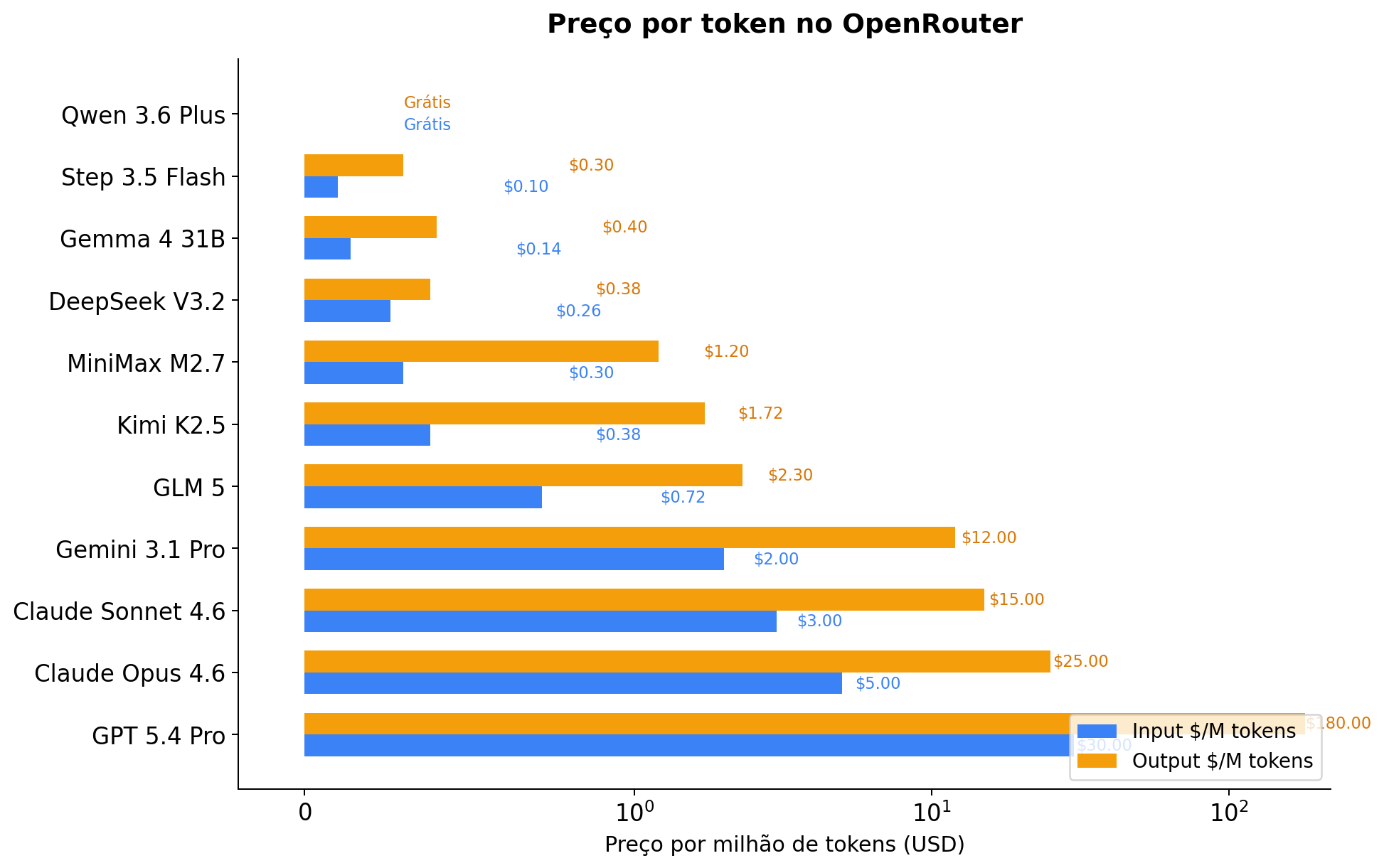
O GPT 5.4 Pro cobra $180 por milhão de tokens de output. O Claude Opus cobra $25. O GLM 5 cobra $2.30. E o Qwen 3.6 Plus é grátis (com rate limit). A escala logarítmica no gráfico esconde um pouco a brutalidade da diferença: de Qwen grátis pra GPT 5.4 Pro são ordens de magnitude.
Mas preço por token não é a história completa. Se você usa Claude ou GPT diariamente pra coding, a assinatura mensal pode sair muito mais barata que pagar por token via API:
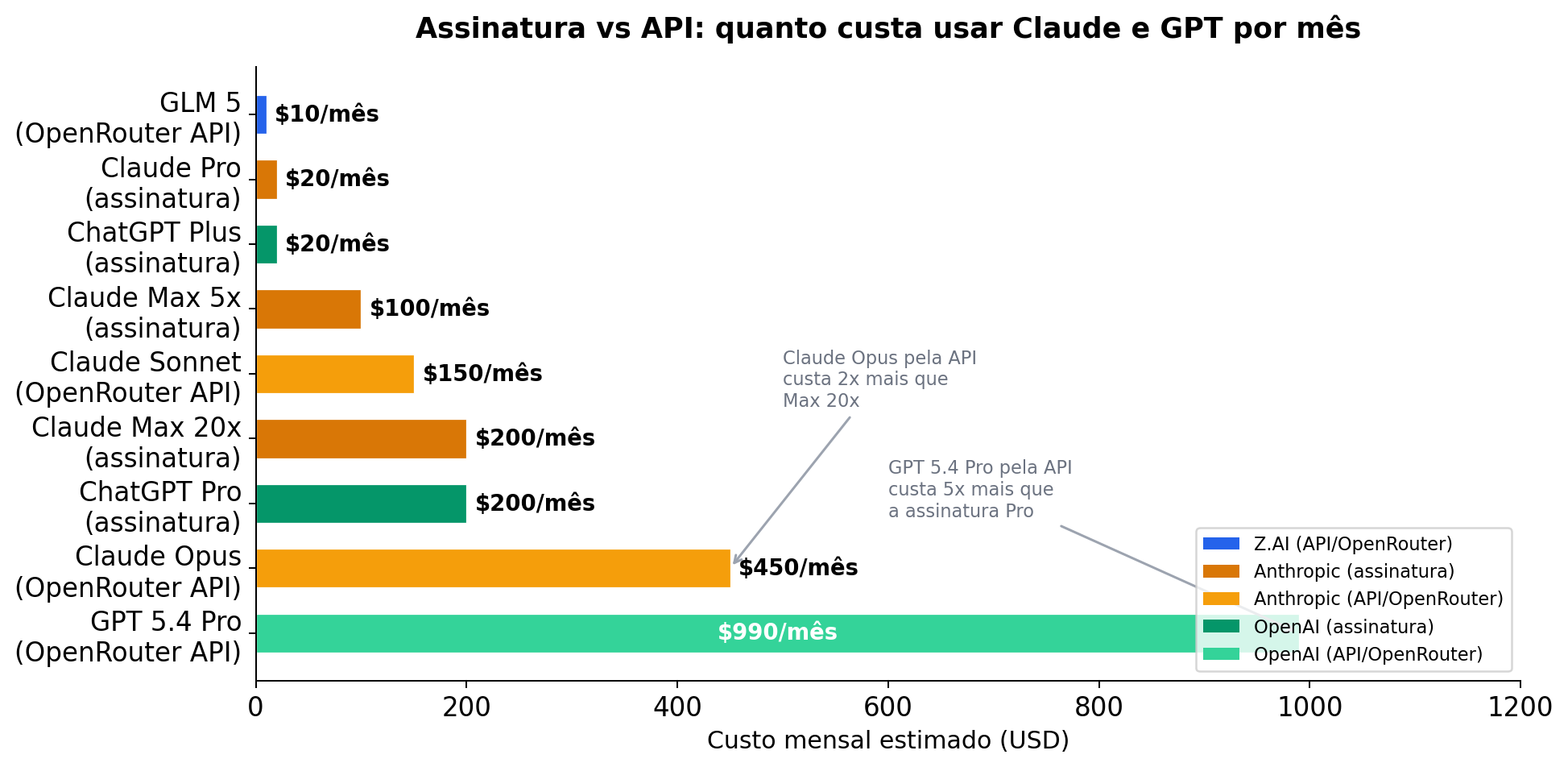
| Abordagem | Est. $/mês* | Notas |
|---|---|---|
| Qwen 3.6 Plus (OpenRouter) | $0 | Grátis mas rate-limited |
| Modelos locais | Eletricidade | Precisa de hardware |
| Claude Pro | $20 | ~44K tokens/5hr |
| ChatGPT Plus | $20 | Inclui Codex |
| Claude Max 5x | $100 | ~88K tokens/5hr |
| Claude Sonnet (OpenRouter API) | ~$150 | Sem cap, pay-as-you-go |
| Claude Max 20x | $200 | ~220K tokens/5hr |
| ChatGPT Pro | $200 | GPT 5.4 Pro ilimitado |
| Claude Opus (OpenRouter API) | ~$450 | Sem cap, pay-as-you-go |
| GPT 5.4 Pro (OpenRouter API) | ~$990 | Absurdamente caro |
*Estimativa pra uso moderado de coding (~15M input + ~3M output tokens/mês).
O ponto principal: se você usa GPT 5.4 Pro, a assinatura ChatGPT Pro a $200/mês com uso ilimitado é 5x mais barata que pagar por token na API. Pra Claude, o Pro a $20/mês cobre uso leve, mas pra quem usa pesado (maratona de coding como a minha), o Max 20x a $200/mês sai mais barato que pagar Opus por token no OpenRouter (~$450/mês). Os modelos open source no OpenRouter ficam todos abaixo de $2.50/M output tokens, mas como vimos, a maioria gera código que não roda.
O que funciona pra uso real
Depois de testar 22 modelos e olhar o código gerado em detalhe:
Tier 1 (funciona plug and play):
| Modelo | Qualidade | Custo/Run | Trade-off |
|---|---|---|---|
| Claude Sonnet 4.6 | Melhor que Opus no opencode (30 vs 16 testes) | ~$0.63 | Mais barato, mas no Claude Code o Opus pode se sair melhor |
| Claude Opus 4.6 | Gold standard | ~$1.05 | Baseline |
| GPT 5.4 Pro | Equivalente ao Opus na prática | ~$7.20* | Falhou no benchmark por incompatibilidade com opencode, mas testei extensivamente no Codex e funciona tão bem quanto Opus |
| GLM 5 | Bom (7 testes, API correta) | ~$0.11 | 89% mais barato, única alternativa non-Anthropic/OpenAI que funciona |
*O GPT 5.4 Pro falhou no benchmark automatizado porque o opencode não suporta o formato nativo de tool calling da OpenAI. Pelo Codex ou ChatGPT Pro ($200/mês com uso ilimitado), funciona sem problemas.
Tier 2 (funciona com ressalvas):
| Modelo | Custo/Run | Ressalva |
|---|---|---|
| Step 3.5 Flash | ~$0.02 | Bypassa o gem pedido, lento (38m) |
| Qwen 3.5 35B (local) | Grátis | Pode funcionar se default configurado, sem mocking |
Tier 3 (código quebrado):
Kimi K2.5, MiniMax M2.7, DeepSeek V3.2, Qwen 3 Coder Next, Qwen 3.5 122B, Qwen 3.6 Plus — todos inventam APIs que não existem.
Tier 4 (não completaram):
Gemma 4 (loop infinito), Llama 4 Scout (sem parser), GPT OSS 20B (diretório errado), Qwen 3 32B (lento demais).
O veredito
Se custo importa e você quer sair da Anthropic: GLM 5 é a única alternativa plug-and-play que funciona. API correta, mocking nos testes, 17 minutos, $0.11 por run. 89% mais barato que Opus.
Se quer o melhor resultado independente de custo: Claude Sonnet 4.6 ganhou do Opus nesse benchmark — mais barato, mesma velocidade, mais testes, código que funciona. Mas vale o caveat: esse resultado é no opencode, não no Claude Code. No ambiente nativo (Claude Code), onde Opus e Sonnet têm acesso ao suporte completo de tools da Anthropic, o Opus pode se sair melhor. Na minha maratona de 500 horas com Claude Code, usei Opus e a experiência foi consistentemente boa. Não dá pra concluir que Sonnet é melhor que Opus em geral só por esse benchmark.
Se quer evitar vendor lock-in total: Qwen 3 Coder Next ou Qwen 3.5 35B rodando localmente via llama-swap. Grátis, mas precisa de GPU server e configuração. O código que geram não roda out-of-the-box — provavelmente precisa de intervenção manual pra corrigir as chamadas de API.
Sim, talvez com dias de tweaking no llama.cpp, calibrando flags, ajustando prompts, testando builds diferentes, dê pra fazer o Gemma 4 ou outros modelos funcionarem melhor. Pra maioria das pessoas, isso não é realista. A distância entre modelos frontier (Claude, GPT) e modelos open source self-hosted é real. Não é marketing. O gap está diminuindo, mas ainda existe.
No fim, o que importa é se o código roda. Um modelo pode gerar 3.405 arquivos, escrever 37 testes, produzir um README de 181 linhas, e ainda assim o app não funcionar porque a API que ele usa não existe. Métricas de completude e contagem de testes são necessárias mas não suficientes. O único sinal confiável é se o modelo usa APIs reais corretamente.
O benchmark completo, com código, configuração, prompts e resultados por modelo, está no GitHub.