Ensinando a questionar notícias | Frank Investigator
Aviso: o Frank Investigator é um projeto experimental, em desenvolvimento ativo, e não pretende ser a palavra final sobre nenhuma matéria analisada. Ele não diz o que é verdade ou mentira. O que ele faz é perguntar o que o artigo se recusou a perguntar, identificar padrões retóricos conhecidos, e buscar fontes externas que o autor omitiu. Se você quiser ajudar, contribua no GitHub ou mande feedback. Se quiser acompanhar os resultados, a newsletter The Makita Chronicles vai ter uma seção nova chamada “Notícias Duvidosas” onde vou publicar o resumo do investigator e o link pro relatório completo.
Dito isso, deixa eu explicar por que eu fiz isso.
O problema com a mídia brasileira
Eu cansei.
Cansei de abrir o jornal e ter que fazer ginástica mental pra separar informação de narrativa. Cansei de publicações como Folha de São Paulo, UOL, Carta Capital, Brasil 247, O Globo e várias outras que usam manchetes enganosas, omitem contexto de propósito, transpõem evidências de outros países sem nenhuma ressalva, e criam uma aparência de consenso entre veículos que estão todos dizendo a mesma coisa porque seguem a mesma pauta coordenada.
Isso não é teoria da conspiração. É padrão editorial verificável. E o pior: a maioria dos leitores não tem tempo nem ferramentas pra perceber. Você lê o título, lê os dois primeiros parágrafos, e segue com a impressão que o artigo plantou na sua cabeça.
O que o Frank Investigator faz
Você dá uma URL de artigo de notícia. O sistema busca o artigo com Chromium headless (pra passar por paywalls e cookie walls), extrai o conteúdo filtrando propaganda e sidebar, e decompõe o texto em afirmações verificáveis. Aí começa a análise de verdade: divergência entre manchete e corpo, falácias retóricas (falsa causalidade, apelo a autoridade, espantalho, bait-and-pivot), distorção de fontes, manipulação temporal, citação seletiva, authority laundering. Expande os links citados no artigo pra verificar se as fontes dizem o que o autor afirma. Avalia cada claim com consenso de 3 modelos de IA (Claude Sonnet 4.6, GPT-5.4, Gemini 3.1 Pro) via OpenRouter. Detecta lacunas contextuais, campanha coordenada entre veículos, e mede a proporção entre paixão e evidência. São 15 etapas ao todo.
O princípio central é “Verdade Acima do Consenso”: uma fonte primária (dado oficial, documento de governo, estudo acadêmico original) veta qualquer quantidade de fontes secundárias repetindo a mesma informação. Dez jornais repetindo a mesma coisa sem fonte primária continuam valendo zero.
Deixa eu mostrar cinco exemplos reais.
Exemplo 1: O caso Noelia Castillo (BBC)

A BBC publicou uma matéria com o título “Morre Noelia Castillo: a luta de uma jovem de 25 anos na Justiça contra seu pai para receber a eutanásia na Espanha”. À primeira vista parece uma história sobre direito à eutanásia e uma disputa familiar. Uma jovem tetraplégica que lutou contra a oposição do pai religioso pra exercer seu direito de morrer.
Só que ao comparar com outros veículos, como a Veja, aparecem fatos que a BBC omitiu quase completamente. E esses fatos mudam tudo.
Noelia foi retirada da família pelo governo espanhol aos 13 anos e colocada sob custódia do estado. Enquanto estava sob essa custódia, sofreu múltiplos estupros coletivos. A violência sexual resultou em danos psiquiátricos graves e um histórico de saúde mental que já somava 67% de grau de invalidez antes dos eventos de 2022. Quando tentou suicídio em outubro de 2022, jogando-se do quinto andar de um prédio, ficou paraplégica. O grau de invalidez subiu pra 74%.
O pedido de eutanásia foi aprovado pela Comissão de Garantia e Avaliação da Catalunha. A data marcada pro procedimento foi 2 de agosto de 2024, mas ficou suspensa por mais de 600 dias por causa dos recursos judiciais do pai. Cinco instâncias judiciais se pronunciaram. O Tribunal Constitucional descartou violação de direitos fundamentais. O Supremo Tribunal da Espanha recusou o recurso. O Tribunal Europeu de Direitos Humanos rejeitou o pedido de suspensão. Na sexta-feira, 26 de março de 2026, Noelia foi submetida à eutanásia no Hospital Residencial Sant Camil, na comarca catalã de Garraf.
Mas tem um detalhe que a Veja menciona e que é perturbador: Noelia teria manifestado dúvidas antes do procedimento. E o hospital teria acelerado o processo porque os órgãos já estavam comprometidos pra doação.
O relatório do Frank Investigator comparou a cobertura de vários veículos.

A análise cruzada entre os artigos analisados mostrou que alguns veículos, como a BBC, omitiram fatos que alteram a interpretação do caso inteiro. Outros, como a Veja, trouxeram o contexto completo. O episódio de violência sexual coletiva de outubro de 2022, a investigação criminal, o histórico psiquiátrico desde os 13 anos, tudo isso aparece em algumas coberturas mas está completamente ausente em outras. E entre os veículos que omitiram, nenhum tocou na questão ética de que o fundamento físico pro pedido de eutanásia deriva de uma tentativa de suicídio.
O enquadramento convergente entre os veículos é de “batalha judicial”, “morte que pediu”, “deixar de sofrer”, “partir em paz”, suavizando o caráter definitivo do procedimento e posicionando Noelia como protagonista heroica e o pai como antagonista obstrutivo. O pai, Gerônimo Castillo, e seus Advogados Cristãos são qualificados como “ultracatólicos” ou “ultraconservadores” sem fonte independente que sustente essa classificação editorial.

A coordenação narrativa ficou em 55%. Não parece ser coordenação ativa entre redações, mas alinhamento editorial temático: todo mundo comprou a narrativa de autonomia individual sem questionar. O que eleva o score é a convergência de omissões. Nenhum veículo explica a distinção jurídica entre o TEDH “autorizar ativamente” a eutanásia e simplesmente recusar medidas cautelares provisórias pedidas pelo pai, que é o que de fato aconteceu. As implicações médicas e bioéticas de aprovar eutanásia em caso decorrente de tentativa de suicídio não aparecem em lugar nenhum. E qualquer voz crítica ao procedimento é automaticamente enquadrada como religiosa ou ideológica, nunca como médica ou jurídica.
É o tipo de caso onde a omissão é a manipulação. Os veículos que omitiram esses fatos não mentiram em nenhum momento. Mas ao enquadrar como “disputa familiar sobre direito à eutanásia” e omitir a cadeia causal (custódia do estado → estupros coletivos → dano psiquiátrico → tentativa de suicídio → paraplegia → eutanásia), o leitor fica com uma impressão radicalmente diferente da realidade. A comparação entre coberturas é exatamente o tipo de coisa que o investigator faz bem: expor o que cada veículo escolheu mostrar e o que escolheu esconder.
Exemplo 2: “Governo corta imposto de quase mil importados” (UOL)

O UOL publicou que o governo cortou impostos de importação de quase mil produtos, de remédios a lúpulo. Manchete positiva, tom de benefício ao consumidor. Vários outros veículos publicaram a mesma coisa com enquadramento parecido: o governo fez algo bom, preços vão cair.
Só que a Gazeta do Povo conta a outra metade da história. O governo não cortou impostos antigos. O que aconteceu foi: em algum momento anterior a fevereiro de 2025, o governo aumentou tarifas de importação de mais de 1.200 itens, uma medida que geraria R$ 14 bilhões em arrecadação estimada. Depois, sob pressão nas redes sociais e pressão popular público, recuou parcialmente. Zerou tarifas de uns 970 itens de capital, informática e telecomunicações. Reduziu impostos de 120 produtos de informática. E agora chama isso de “corte de impostos”.
Ou seja: aumentaram, tomaram pressão popular, voltaram atrás em parte, e reembalaram como se fosse uma concessão generosa. A maioria dos mais de 1.200 itens que tiveram tarifas elevadas continua com tarifas mais altas do que antes. Nenhum preço caiu pro consumidor final. Os preços voltaram ao que eram pra alguns produtos, e continuam mais altos pra maioria.
O relatório do Frank Investigator cruzou os artigos e expôs o que foi omitido.

O que a comparação entre artigos expõe: nenhum dos veículos com enquadramento positivo menciona que a maioria dos 1.200+ itens com tarifas elevadas continua com tarifas mais altas após as duas rodadas de “cortes”. O impacto fiscal sobre a meta de arrecadação de R$ 14 bilhões prevista com os aumentos originais, ninguém calcula. Vozes da indústria nacional que pode ser prejudicada pela redução tarifária de concorrentes importados, nenhuma. Critérios objetivos do Gecex pra definir “oferta insuficiente no mercado interno”, não aparecem.
Os dois artigos analisados constroem o mesmo enquadramento positivo pro governo. O paradoxo de que os “cortes” são reversão parcial de aumentos feitos pelo mesmo governo no ano anterior fica enterrado ou simplesmente ausente.
É o tipo clássico de manipulação por reenquadramento. Ninguém mentiu. Mas “governo corta imposto” e “governo recua de aumento após pressão popular” descrevem o mesmo evento com impressões opostas. A escolha editorial de qual versão publicar já é a manipulação.
Exemplo 3: “Globo se desculpa por PowerPoint” (Brasil 247)

Esse caso explodiu nos últimos dias. A GloboNews mostrou um diagrama no programa Estúdio I conectando o presidente Lula, seus ministros e Daniel Vorcaro, dono do Banco Master, que está no centro de fraudes documentadas. A Globo depois se retratou publicamente, chamou o material de “errôneo e incompleto”, e demitiu uma editora.
O Brasil 247 publicou uma matéria com o título “Globo se desculpa por PowerPoint que tentou jogar o caso Master no colo de Lula”.
O relatório do Frank Investigator expôs o que está acontecendo por baixo:

O fato central é real: a Globo pediu desculpas e demitiu alguém. Mas o enquadramento do Brasil 247 vai muito além do que os fatos sustentam. O título diz “tentou jogar no colo de Lula” atribuindo intenção deliberada onde os documentos apontam pra falha editorial. A retratação da Globo falou em material “errôneo e incompleto”, não em tentativa de incriminar ninguém.
O que chama atenção nesse caso é a campanha coordenada. O investigator deu 62% de coordenação narrativa.

Vários veículos editorialmente alinhados ao governo usaram a expressão “sem provas” de forma convergente pra descrever a associação entre Lula e o caso Master. Todos focaram no erro da Globo como ponto central da narrativa, em vez de investigar as conexões reais. Nenhum veículo mencionou quais outros nomes políticos foram excluídos do PowerPoint original. Nenhum investigou as conexões documentadas de Vorcaro com diferentes esferas do poder. O foco é meta-jornalístico: criticam a emissora em vez de cobrir o escândalo.
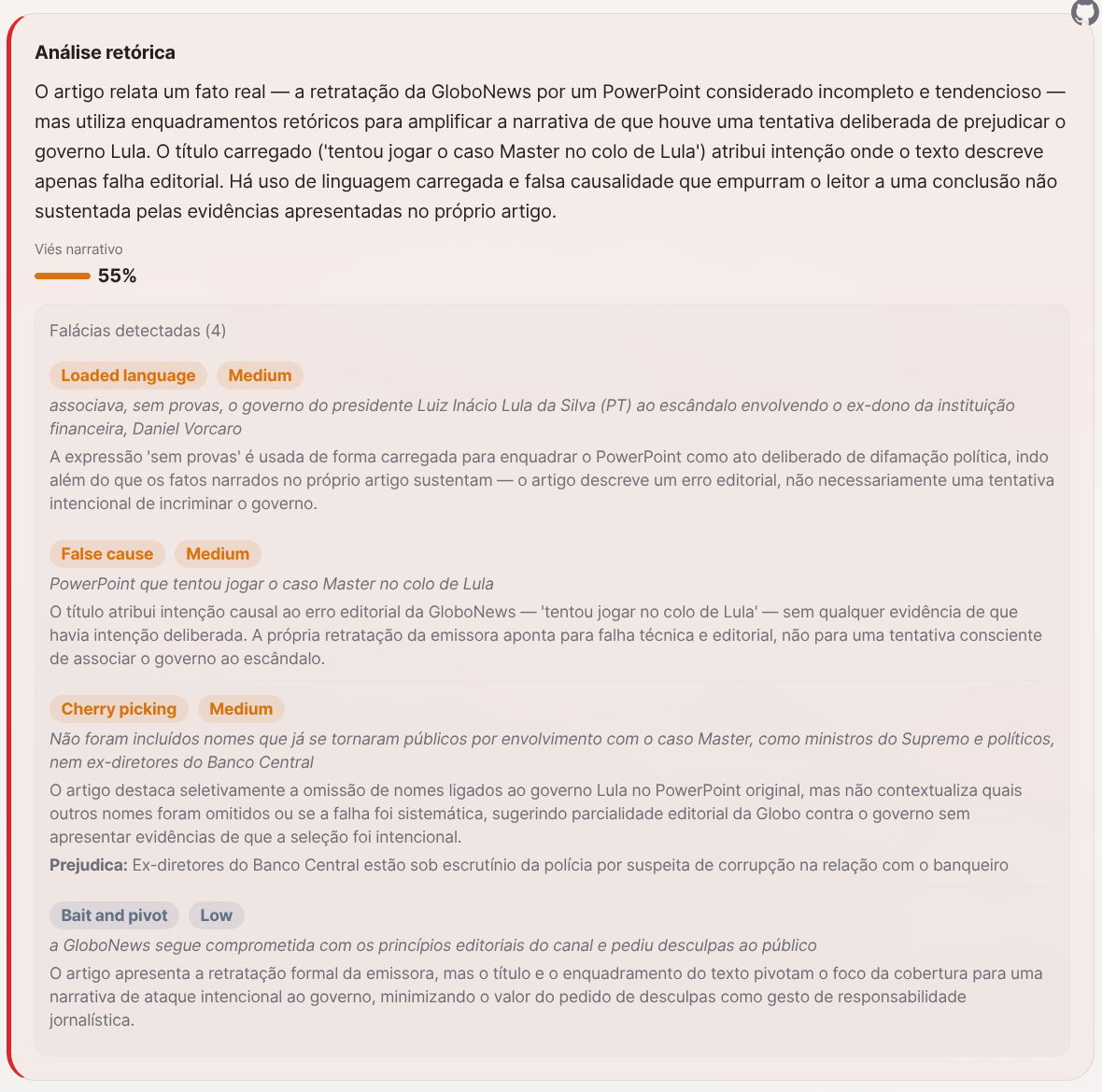
As falácias detectadas: linguagem carregada (“tentou jogar”, “sem provas” usados pra enquadrar erro editorial como ataque político deliberado), falsa causalidade (a retratação da Globo não prova que as conexões são falsas), cherry-picking (destaca a omissão de nomes ligados ao governo Lula sem contextualizar quais outros nomes foram omitidos), e bait-and-pivot (usa o pedido de desculpas da Globo como gancho pra minimizar o escândalo do Banco Master).
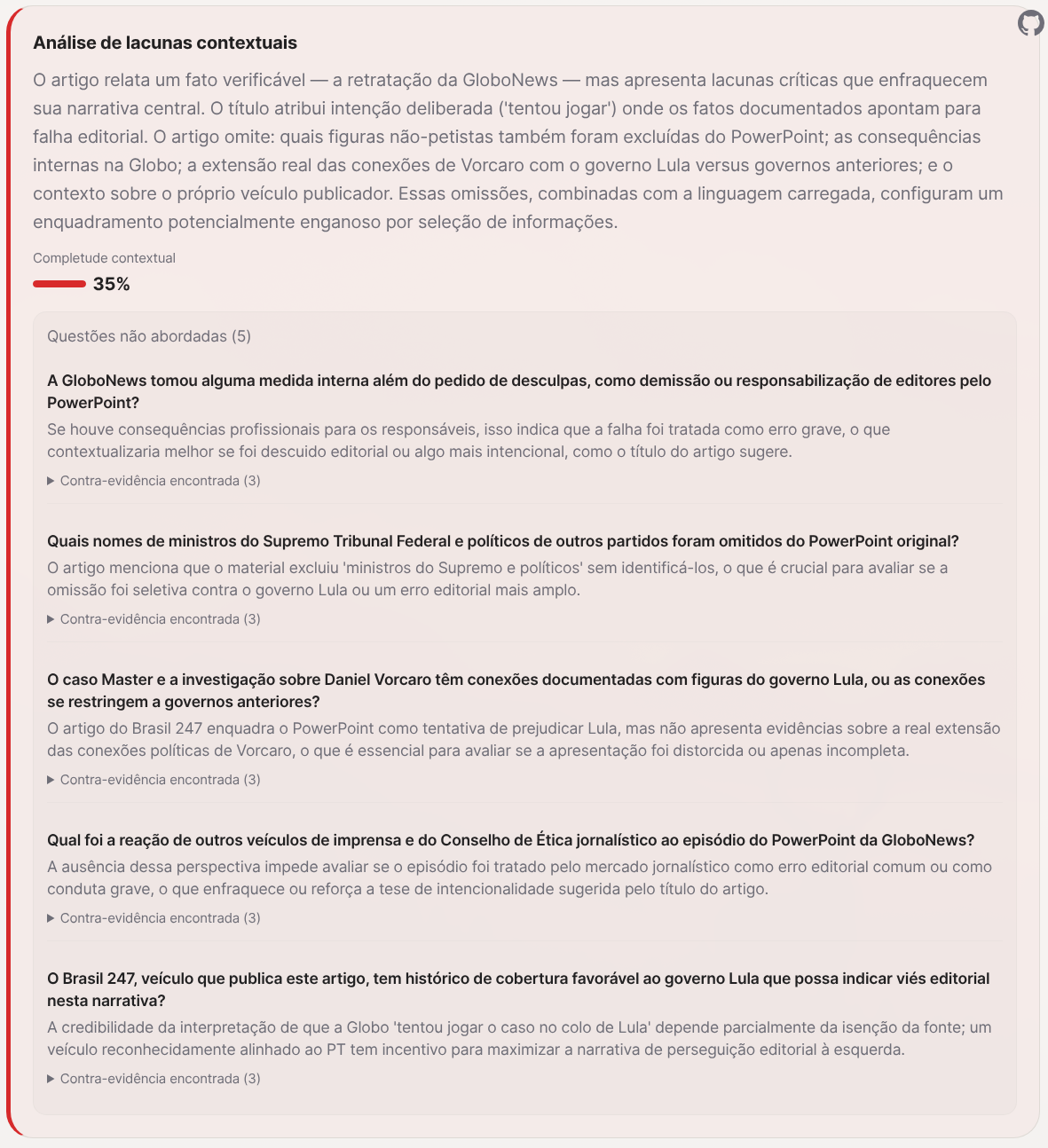
E as perguntas que nenhum desses veículos fez: quais nomes de ministros do Supremo e políticos de outros partidos também foram excluídos do PowerPoint? O caso Master tem conexões documentadas com figuras do governo Lula, ou se restringem a governos anteriores? O Brasil 247, que publica esse artigo, tem alinhamento editorial declarado com o governo Lula? Qual foi a reação do Conselho de Ética jornalístico?
Confiança geral: 13%. O artigo não fabrica fatos. Mas seleciona, enquadra e omite de forma a construir uma narrativa que os dados não sustentam.
Exemplo 4: “Por que combustível caro é bom” (Folha)

O economista Bernardo Guimarães publicou uma coluna na Folha defendendo que combustível caro é bom pra sociedade porque estimula inovação em energia limpa. Ele cita artigos acadêmicos reais (Popp 2002, NBER) e tem credenciais acadêmicas verificáveis (doutorado em Yale, professor na FGV EESP). Parece sólido.
O relatório completo do Frank Investigator mostra outro quadro.

O artigo acerta ao citar estudos reais. Mas omite quem paga a conta. A coluna ignora completamente o impacto distributivo: populações de baixa renda, moradores de áreas periféricas e rurais, que dependem mais de veículos próprios e têm menos acesso a alternativas limpas. Pra um economista, ignorar efeitos distributivos é ou incompetência ou escolha editorial.
Tem um problema pior. As evidências empíricas que ele cita (patentes nos EUA, dados de veículos elétricos na Califórnia entre 2014-2017) são transpostas pro Brasil sem ressalva nenhuma. O Brasil tem uma matriz de etanol e infraestrutura flex-fuel que altera completamente o mecanismo causal. O artigo trata como se o consumidor brasileiro estivesse na mesma situação que o californiano, o que é falso.
E tem o contexto que o artigo menciona de passagem mas não desenvolve: a Guerra no Irã está fazendo os preços de combustível subirem no mundo todo. O Brasil deveria estar numa posição privilegiada por causa do pré-sal e do etanol. Mas décadas de má gestão e corrupção na Petrobras fizeram com que a gente pague o mesmo preço que o resto do mundo. Em vez de questionar isso, a coluna vende a ideia de que “pelo menos vai estimular energia limpa”. É uma racionalização de um problema que não deveria existir.

O investigator identificou 5 questões que o artigo se recusou a abordar, com 35% de completude contextual. As falácias detectadas incluem falso dilema (apresenta combustível caro como a única opção viável de política climática), cherry-picking (reconhece inelasticidade de curto prazo mas enfatiza apenas efeitos de longo prazo), e linguagem carregada (descreve alternativas como “brincar de plantar uma mudinha”).
Confiança geral: 25%. Não é desinformação fabricada. É opinião com seleção de evidências a favor da tese e omissão de contrapontos relevantes.
Exemplo 5: “Não existe cinema forte sem regulamentação do streaming” (O Globo)
Renata Magalhães, presidente da Academia Brasileira de Cinema, deu uma entrevista na coluna da Miriam Leitão no O Globo defendendo que regulamentar o streaming é condição necessária pra fortalecer o cinema brasileiro.
O relatório do Frank Investigator encontrou problemas sérios.

Primeiro: a afirmação central de que “muitos filmes têm baixa audiência” aparece sem nenhum dado empírico. Nenhum número, nenhuma série histórica. É afirmação de autoridade pura, sem base analítica.
Segundo: tem uma contradição interna que o artigo não resolve. O texto abre dizendo que o cinema brasileiro está “em destaque internacional” (prêmios, festivais). E logo em seguida argumenta que a ausência de regulamentação impede o fortalecimento da indústria. Mas se o cinema brasileiro já está ganhando prêmios internacionais sem essa regulamentação, o argumento de que a regulamentação é condição necessária cai por terra. O artigo não endereça essa contradição.
E é aqui que entra o elefante na sala que nenhum desses artigos menciona: as pessoas simplesmente não querem assistir a maioria desses filmes. O cinema brasileiro premiado internacionalmente é feito pra competir em Cannes e no Oscar, não pra lotar sala de cinema no Brasil. Em vez de se perguntar por que o público brasileiro não se interessa, a indústria prefere pedir regulamentação do streaming pra forçar plataformas a financiar e exibir conteúdo que não tem audiência espontânea. É o modelo clássico: usa dinheiro público e regulação pra manter viva uma indústria que não se sustenta no mercado.
A entrevistada é presidente da Academia Brasileira de Cinema. Tem interesse institucional direto na regulamentação. O artigo não apresenta nenhuma voz contrária e não discute os custos pro consumidor: aumento de preço de assinatura, redução de catálogo. Uma fonte só, com conflito de interesse declarado, sem contraponto.

E aqui vem a campanha coordenada, com 55% de coordenação narrativa. Múltiplos veículos reproduzem o mesmo enquadramento emocional: cinema “em risco”, regulamentação como “essencial”. Nenhuma das fontes identificadas discute evidências empíricas internacionais comparáveis sobre a eficácia de cotas de conteúdo (a Europa tem experiências com resultados contraditórios). Nenhuma menciona os conflitos de interesse da Academia Brasileira de Cinema. O fato de que as produções brasileiras premiadas internacionalmente foram feitas sem a regulamentação proposta é omitido convergentemente em todos os veículos. Apenas um site isolado (targethd.net) mencionou impactos negativos pro consumidor.
Confiança geral: 9%. O artigo é advocacy editorial legítimo, mas com falhas analíticas que limitam seu valor informativo a quase zero.
O que o investigator analisa
Os 5 exemplos acima mostram padrões diferentes, mas os critérios de análise são os mesmos.
O sinal mais forte de manipulação é a omissão. Não é o que o artigo diz que engana, é o que ele deixa de dizer. A análise de lacunas contextuais identifica as perguntas que o artigo deveria ter respondido e não respondeu, e busca contra-evidência pra cada uma. Nos exemplos acima, artigos que omitem a maior parte do contexto relevante não estão informando ninguém. E quando a comparação cruzada entre veículos mostra que uns cobriram os fatos e outros não, como no caso Noelia ou no corte de impostos, fica difícil argumentar que a omissão foi acidental.
Depois vem a detecção de campanha coordenada. Vários jornais cobrirem o mesmo assunto é normal. Todos usarem a mesma linguagem carregada, focarem nos mesmos pontos e omitirem os mesmos contrapontos ao mesmo tempo não é. O sinal mais forte de coordenação não é o que os veículos dizem em comum, mas o que omitem em comum.
Tem também o reenquadramento, que é mais sutil. No caso dos impostos, o governo aumentou tarifas, recuou sob pressão, e os veículos chamaram de “corte”. Ninguém mentiu tecnicamente, mas a escolha de enquadramento muda completamente a interpretação. Esse tipo de manipulação é mais difícil de detectar porque cada afirmação individual é defensável.
As falácias retóricas pegam construções específicas: falso dilema (“ou regula ou o cinema morre”), bait-and-pivot (abre com fato positivo e pivota pra narrativa de crise), linguagem carregada (“sem provas” usado pra atribuir intencionalidade). Cada falácia detectada vem com a citação exata do trecho e a explicação de por que aquela construção é problemática.
E tem o princípio que costura tudo: se 10 veículos repetem a mesma afirmação citando uns aos outros, o consenso de LLMs tem que refletir que a cadeia de evidência é circular, não que a afirmação é bem suportada. Volume de cobertura não é proxy pra verdade.
Por que você não pode “só perguntar pro ChatGPT”
A primeira reação de muita gente vai ser: “por que eu preciso disso se eu posso colar o artigo no ChatGPT e pedir pra ele analisar?”
Tenta. Pega um artigo político e pede pro ChatGPT criticar. Ele vai criticar. Pega o mesmo artigo e pede pra confirmar. Ele vai encontrar argumentos pra confirmar. O LLM não está buscando a verdade. Ele está prevendo qual resposta você mais provavelmente espera ouvir dado o enquadramento da sua pergunta. Se você pede “analise os problemas desse artigo”, o modelo vai achar problemas. Se você pede “esse artigo está correto?”, ele vai encontrar méritos. É viés de confirmação automatizado.
Tem outro problema. Os LLMs generalistas foram treinados pra ser agradáveis. A tendência sycophantic (de concordar com o usuário) é documentada em todos os modelos grandes. Se o seu histórico de conversa indica que você é de esquerda, o modelo tende a enquadrar as respostas de uma forma que agrade esse perfil. Se você é de direita, mesma coisa pro outro lado. Ele não está mentindo de propósito. Ele está otimizando pra satisfação do usuário, que é literalmente a métrica pela qual foi treinado via RLHF.
E o pior: LLMs alucinam. Se não têm evidência suficiente pra sustentar a resposta que acham que você quer ouvir, inventam. Fabricam citações e dados plausíveis, atribuem declarações a pessoas que nunca as fizeram. Se você pede pra ele criticar um artigo sobre combustível, ele pode inventar um estudo fictício que “prova” o contrário do artigo. Parece convincente. Mas não existe.
O Frank Investigator foi construído pra evitar exatamente esses problemas. A primeira decisão de design é que nenhum humano faz pergunta ao LLM. Não existe prompt aberto tipo “analise esse artigo”. Cada etapa do pipeline tem prompts estruturados que pedem análises específicas: “liste as falácias retóricas neste trecho”, “identifique que informações contextuais estão ausentes”, “compare a manchete com o corpo do texto”. O modelo não sabe se o operador concorda ou discorda do artigo, porque o operador não opina em nenhum momento. Isso elimina o viés de confirmação na raiz.
Pra lidar com alucinação, todo analisador que usa LLM inclui a instrução “CRITICAL – NO HALLUCINATION: Only reference URLs, sources, claims, quotes, and data that are EXPLICITLY present in the input provided to you. Do not invent, guess, or fabricate any URL, source name, statistic, quote, or claim. If you cannot verify something from the provided text, mark it as unverifiable – never fill in details.” Não elimina alucinação completamente, mas reduz muito. E como são 3 modelos de empresas diferentes (Anthropic, OpenAI, Google) respondendo as mesmas perguntas, quando um alucina os outros dois geralmente discordam. O consenso é ponderado por confiança, não por maioria simples. Se dois modelos dão “supported” com 70% de confiança e um dá “mixed” com 95%, o “mixed” pesa mais. Quanto mais distante a discordância, maior a penalização na confiança final. Se um modelo começa a dar respostas inconsistentes, ele é colocado em quarentena e os outros dois continuam.
Mas a salvaguarda que eu considero mais importante é o primary source veto. Se uma fonte primária (dado do IBGE, decisão judicial, estudo original) contradiz uma claim, a confiança é capada em 60% e o veredicto é forçado pra “mixed”, mesmo que os 3 LLMs digam “supported”. Dez artigos de jornal repetindo uma afirmação não superam um dado oficial que a contradiz. Na mesma linha, se 5 matérias “confirmam” uma claim mas todas são do mesmo grupo editorial (Folha/UOL, Globo/G1/Valor), o sistema sabe que são a mesma voz e reduz o peso. Volume não substitui independência.
Nada disso torna o sistema perfeito. Mas é categoricamente diferente de colar texto no ChatGPT e perguntar “o que você acha?”.
Os números
| Métrica | Valor |
|---|---|
| Commits | 129 |
| Dias de trabalho ativo | ~9 |
| Linhas de Ruby (código) | 19.444 |
| Linhas de teste | 9.190 |
| Arquivos de teste | 108 |
| Total de linhas (código) | 24.301 |
| Services (analisadores + serviços) | 80 |
| Analisadores de desinformação | 15 |
| Modelos ActiveRecord | 14 |
| Background jobs | 19 |
| Migrações de banco | 31 |
| Etapas do pipeline | 15 |
| Modelos de LLM em consenso | 3 |
| Locales | 2 (en, pt-BR) |
Stack: Ruby 4.0.1, Rails 8.1.2, SQLite com WAL mode, Solid Queue (jobs dentro do Puma), Solid Cable (WebSockets), Tailwind CSS v4, Chromium headless via Ferrum CDP, deploy com Kamal pro GitHub Container Registry. AGPL-3.0.
O processo de desenvolvimento
O projeto tem 129 commits em 9 dias de trabalho ativo (11-16 e 25-27 de março). O primeiro dia foi o mais pesado: mais de 60 commits só em 11 de março, começando do zero e chegando num sistema funcional com extração de conteúdo, decomposição de claims, avaliação por LLM, e interface web com live updates via Turbo Streams.
Os commits contam a história. Começou com a fundação:
1e32d5a - Initial Frank Investigator foundation
564eb97 - Add recursive source crawling and RubyLLM scaffold
c8c5357 - Add Brazil source registry and authority connectors
3d30617 - Add U.S. authority profiles, source role modeling, and specialized connectorsDepois vieram os analisadores de desinformação, um por um:
a65fef7 - Add rhetorical fallacy analyzer for detecting narrative manipulation
5dcf99d - Add headline-body divergence detection and headline citation amplification
a113efd - Add smear campaign defense with circular citation and viral volume detection
56d501a - Add media ownership modeling, syndication detection, and independence analysisA fase de hardening contra ruído e falsos positivos foi a que mais consumiu tempo:
46e4bc5 - Add pre-fetch defenses: URL filtering, circuit breaker, fetch prioritization
168fea1 - Add post-fetch content gate, claim noise filter, and duplicate content skip
b2843d7 - Add paywall detection, pricing noise filter, and ofertas.* host rejection
b1b230d - Rewrite Chromium fetcher with Ferrum CDP for anti-bot evasionDepois veio a interface, deploy, e os analisadores mais avançados:
c5afcea - Replace custom CSS with Tailwind CSS v4 and rewrite all templates
95a8ec4 - Add Docker deployment with bin/deploy script
ccfacc9 - Add coordinated narrative detection across media outlets
ba3e2f4 - Add 6 new misinformation detection analyzers with cross-analysis
fda984b - Add LLM-generated investigation summary with quality assessment
a4ebe78 - Add contextual gap analysis to detect manipulation through omissionE nos últimos commits, o consenso de 3 modelos simultâneos e otimização de testes:
5cc9c05 - Enable 3-model LLM consensus: Sonnet 4.6, GPT-4.1 Mini, Gemini 2.5 Pro
cdf5fb5 - Batch 5 content analyzers into single LLM call, add anti-hallucination
28c305e - Add WebMock stubs for LLM and web search — tests run in 1.4s (was 540s)Os testes que rodavam em 9 minutos agora rodam em 1.4 segundo com WebMock stubbing de todas as chamadas de LLM e web search. Isso fez diferença enorme na velocidade de iteração.
Limitações
Fact-checking de notícias é um problema difícil. Um artigo sozinho não contém tudo que é necessário pra uma análise completa. O autor escolheu o que incluir e o que omitir, e essa escolha já é o primeiro nível de manipulação. As fontes citadas dentro do artigo foram selecionadas pelo autor pra sustentar a narrativa dele, não pra dar uma visão equilibrada.
O Frank Investigator não diz o que é verdade e o que é mentira. O resultado é um relatório com pontos fortes e fracos, não um selo de “verdadeiro” ou “falso”. Mesmo com todas as salvaguardas que descrevi acima, a contra-evidência buscada automaticamente pode não ser a mais relevante. As falácias detectadas podem ter falsos positivos. A análise de campanha coordenada depende do que o web search retorna no momento da busca.
Use os relatórios como ponto de partida pra formar sua própria opinião, não como veredicto final.
O projeto é open source, AGPL-3.0. Se quiser contribuir, testar, reportar bugs ou sugerir melhorias: GitHub. Se quiser acompanhar as análises, a newsletter The Makita Chronicles vai ter a seção “Notícias Duvidosas” com resumo e link pro relatório completo de cada investigação.