Meu primeiro fracasso com Vibe Code e como Consertei | Frank Yomik
Eu tenho uma coleção enorme de mangás comprados na Amazon.co.jp que leio pelo Kindle web. Mangás shounen normalmente têm furigana — aquele texto pequeno em hiragana ao lado dos kanjis — que me ajudam a ler, porque, apesar de ter estudado japonês, nunca fui treinado formalmente. Mas mangás para público adulto (seinen, não pornô) geralmente vêm sem furigana. São kanjis puros e minha leitura deles fica muito lenta.

Faz anos que quero uma ferramenta que resolva isso. A ideia é simples: detectar os balões de fala numa página de mangá, extrair o texto com OCR, e ou adicionar furigana nos kanjis, ou traduzir direto pro inglês e renderizar de volta no balão. Parece fácil, certo?
 *(kanji sem legenda/furigana)
*(kanji sem legenda/furigana)
 *(com furigana injetado em tempo real)
*(com furigana injetado em tempo real)
Pois é, parecia. E por saber que parecia fácil, mas que não seria, eu nunca tive paciência pra fazer. Eu sei fazer os 80% iniciais de qualquer projeto. O problema são os 20% finais — aquela fase de experimentação, tweaking, ajuste fino, tratar edge cases — que consomem mais tempo que todo o resto junto. E num projeto de visão computacional, esses 20% são especialmente traiçoeiros.
Mas aí chegou a era do vibe coding. E eu pensei: talvez agora os 20% sejam viáveis. Iniciei o projeto no dia 24 de fevereiro de 2026, às 23:10 da noite. E este se tornou um exemplo de como é muito fácil fazer grandes volumes de código inútil.
A Ideia Original: OpenCV e Heurísticas
Meu plano original - o conceito que imaginei por anos - era: usar OpenCV - que é uma biblioteca famosa e antiga de visão de computador - pra detectar os balões de fala. Balões de mangá são tipicamente áreas brancas com contorno preto dentro de painéis. Em teoria, basta fazer threshold da imagem pra pegar regiões brancas, encontrar contornos, filtrar por tamanho e formato, e pronto.
Em 24 horas eu já tinha uma prova de conceito funcional: detecção de balões, OCR com manga-ocr (modelo treinado especificamente em texto japonês de mangá), furigana com MeCab pra análise morfológica, tradução com Ollama rodando Qwen3:14b local, e renderização do texto de volta no balão. O commit inicial (9169d73) do dia 24/fev já fazia tudo isso.

No dia seguinte, 25 de fevereiro, eu já estava estendendo o pipeline com pipeline de tradução de webtoons coreanos. 27 commits nesse dia. Tudo parecia estar fluindo.

E aí começou o inferno.
O Inferno dos Falsos Positivos
O problema com detecção de balões via OpenCV é que o manga não é um documento padronizado. Cada artista tem traço próprio, a qualidade de scan varia enormemente entre eras de impressão, e páginas coloridas precisam de parâmetros completamente diferentes de páginas P&B. E a coisa que mais se parece com um balão de fala branco numa página de mangá é… um rosto.

Rostos de personagens são áreas claras, relativamente arredondadas, com contorno escuro. Exatamente como balões de fala. E não importa quantos filtros você empilhe, sempre aparece um caso onde o rosto de um personagem com cabelo azul passa por todos os seus filtros, ou onde um balão legítimo é rejeitado porque tem formato incomum.
Olha como ficou meu detector de balões no pico da complexidade — 551 linhas com 7 camadas de filtros de falso-positivo (versão resumida):
# --- False positive filters ---
# 1. Edge density
edge_pixels = cv2.countNonZero(cv2.bitwise_and(edges, edges, mask=mask))
edge_density = edge_pixels / area
if edge_density > max_edge_density:
continue
# 2. Bright pixel ratio
bright_pixels = cv2.countNonZero(cv2.bitwise_and(bright_thresh, mask))
bright_ratio = bright_pixels / area
if bright_ratio < min_bright_ratio:
continue
# 3. Mid-tone ratio
mid_mask = cv2.inRange(gray, 80, 220)
mid_pixels = cv2.countNonZero(cv2.bitwise_and(mid_mask, mask))
mid_ratio = mid_pixels / area
if mid_ratio > max_mid_ratio:
continue
# 4. Contour circularity
circularity = 4 * np.pi * area / (perimeter * perimeter)
if circularity < 0.10:
continue
# 5. Border darkness
border_mean = cv2.mean(gray, mask=border_only)[0]
if border_mean > 160:
continue
# 6. Background uniformity (white_std)
white_pixels = gray[(mask > 0) & (gray > 200)]
if float(np.std(white_pixels)) > 15:
continue
# 7. Dark content analysis (text strokes)
very_dark = np.sum((inner_mask > 0) & (gray < 60))
dark_ratio_60 = very_dark / inner_area
if dark_ratio_60 < min_dark_ratio:
continueCada um desses filtros foi adicionado em resposta a um falso-positivo específico. Edge density separava balões (que têm traços esparsos de texto) de rostos (que têm cabelo, olhos, nariz criando bordas densas). Bright pixel ratio verificava se a região era realmente branca. Circularity descartava formas muito irregulares. E por aí vai.
Mas o pior é que esses filtros interagiam entre si de formas imprevisíveis. Olha esse commit do dia 26/fev (70c814a):
“Revert rect_dark, mid_ratio, and early-split changes that caused face FPs”
Eu tinha tentado relaxar dois thresholds — rect_dark de 0.10 pra 0.11, mid_ratio de 0.15 pra 0.16 — pra recuperar balões que estavam sendo perdidos. Resultado: rostos e regiões de corpo começaram a passar como falsos positivos em mangá do Adachi. Tive que reverter tudo.
Esse é o padrão que se repetiu durante dias: recuperar um balão perdido significava abrir porta pra falsos-positivos. Corrigir um falso-positivo significava perder um balão legítimo. Era um whack-a-mole infinito.
Os Paliativos: CLAHE, Detecção por Borda, Watershed
Quando os 7 filtros básicos não foram suficientes, comecei a empilhar passes adicionais.
Commit 294e785 (26/fev): adicionei CLAHE (Contrast Limited Adaptive Histogram Equalization) como segundo passe de detecção. Balões com brilho médio, perto do threshold de 200, estavam sendo perdidos. O CLAHE equalizava o contraste e revelava esses balões borderline.
Mas o CLAHE também fazia rostos passarem pelos filtros porque inflava artificialmente o brilho de pele. Então precisei adicionar uma função inteira de validação contra a imagem original:
def _validate_on_original(candidate, gray_orig):
"""Check if a CLAHE-detected candidate looks bubble-like on original."""
roi = gray_orig[y1:y2, x1:x2]
mean_brightness = roi.mean()
# Already bright enough for pass 1 — rejected for good reason
if mean_brightness > 215:
return False
# Must have text strokes (dark pixels)
dark_ratio = np.sum(roi < 60) / roi.size
if dark_ratio < 0.07:
return False
# White pixel variance: text creates high std, face skin is uniform
white_pixels = roi[roi > 200]
if len(white_pixels) > 50:
if float(np.std(white_pixels)) < 9:
return False
return TrueCommit 5dddb31 (1/mar): adicionei um terceiro passe inteiro de detecção baseado em bordas (edge-based segmentation). Pra pegar balões onde o interior branco se fundia com o fundo branco da página. Dilatava as bordas Canny, invertia, fazia AND com regiões brilhantes, e procurava contornos no resultado.
Commit b695295 (26/fev): adicionei recuperação de balões pequenos via gradiente morfológico + validação por OCR. Se o OCR confirmava que tinha texto japonês válido na região, provavelmente era um balão real.
Cada paliativo adicionava 50-100 linhas de código e mais uma camada de complexidade. E cada um tinha seus próprios edge cases e falsos-positivos.
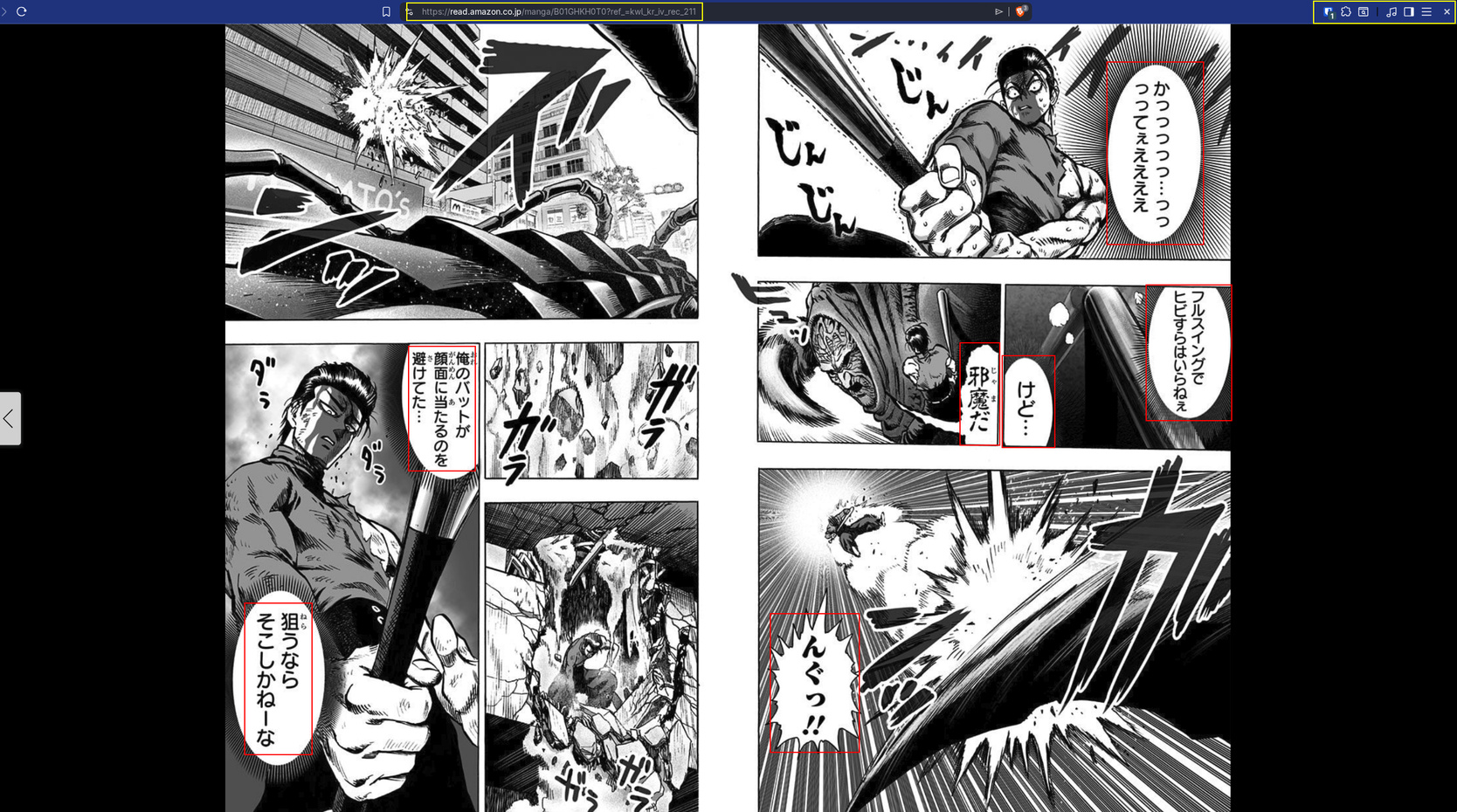
A Conta Final da v0.1
No dia 1 de março, marquei a tag v0.1. Nesse ponto eu tinha:
- 90 commits em 6 dias de desenvolvimento (24/fev a 1/mar)
- 551 linhas só no
bubble_detector.py - 7 camadas de filtro de falso-positivo, cada uma com thresholds empíricos
- Dois passes de detecção completos (original + CLAHE)
- Um terceiro passe baseado em bordas
- Validação cruzada contra imagem original
- Separação de watershed pra balões sobrepostos
- Perfis separados de threshold pra páginas coloridas vs preto-e-branco
- 20+ magic numbers ajustados empiricamente contra uma amostra limitada de páginas
- Testes de regressão travando cada falso-positivo específico (face de menina com cabelo azul, moldura de janela, tira fina horizontal, chão de concreto…)
E mesmo com tudo isso, ainda não era confiável. Cada novo mangá que eu testava revelava algum pequeno caso que quebrava o detector. Era um monolito extremamente frágil.
SINTOMA: você faz correção pra corrigir a correção que corrigia outra correção, e quando mexe num pedaço, quebra outro sem querer: significa que o código é brittle, frágil, uma casa de cartas que vai cair a qualquer momento. Esse é o ponto pra desistir e repensar!
A Decisão: Pesquisar Alternativas
Na v0.1 eu parei e fiz a pergunta que deveria ter feito no começo: será que já existe alguém que treinou um modelo de ML pra fazer exatamente isso?
Pedi pro Claude pesquisar modelos disponíveis de detecção de balões em quadrinhos. A pesquisa resultou no documento docs/yolo_bubble_detection_plan.md, onde analisamos as alternativas.
A primeira que apareceu foi um YOLOv8 Medium do ogkalu (comic-speech-bubble-detector-yolov8m), treinado em ~8.000 imagens de manga, webtoon, manhua e quadrinhos ocidentais. Detecta só uma classe (speech bubble). Mas pesquisando mais, achamos outro modelo do mesmo autor: ogkalu/comic-text-and-bubble-detector, um RT-DETR-v2 com backbone ResNet-50-vd (42.9M parâmetros), treinado em ~11.000 imagens, com três classes: bubble, text_bubble e text_free. Ambos Apache 2.0.
Também avaliamos o comic-text-detector (DBNet + YOLOv5, ~13.000 imagens do Manga109), mas esse detectava regiões de texto e não balões. E como dados de treinamento futuro, havia o Roboflow com 4.492 imagens já etiquetadas, e o Manga109 dataset com 147.918 anotações em 21.142 páginas.
O RT-DETR-v2 com 3 classes era o mais promissor porque distinguia balões de fala, texto dentro de balões e texto livre (narração, SFX). Poderia substituir tanto o bubble_detector.py quanto o text_detector.py em uma única passada de inferência.

A conclusão do documento de pesquisa era direta:
“Mesmo sem ajustes finos, esses modelos foram treinados com 8 a 11 mil imagens de diversos quadrinhos. Eles devem lidar com a diversidade de estilos artísticos que nossos filtros manuais têm dificuldade em processar. A cascata heurística de 7 filtros e seus números mágicos seriam completamente eliminados.”
E se não fosse suficiente, incluímos um plano de fine-tuning usando dados pareados (páginas originais em japonês vs fan translations em inglês) que geravam labels automaticamente por diff de imagem. Mas primeiro queríamos testar o baseline.

Trocando Tudo: RT-DETR-v2
No dia 4 de março, fiz o commit 0df63f2: “Replace OpenCV heuristic detection with RT-DETR-v2, add bubble shape masking”.
O diff fala por si:
16 files changed, 732 insertions(+), 1112 deletions(-)1.112 linhas deletadas. Mais linhas removidas do que adicionadas. O detector de balões de 551 linhas foi substituído por 262 linhas — e dessas, a maior parte é extração de máscara de formato (contour mask) a partir do bbox detectado, não detecção em si.
O núcleo da detecção virou isso:
MODEL_ID = "ogkalu/comic-text-and-bubble-detector"
DEFAULT_CONFIDENCE = 0.35
def detect_bubbles(img_cv, confidence=DEFAULT_CONFIDENCE):
model, processor, device = _get_model()
img_pil = Image.fromarray(img_cv[:, :, ::-1]) # BGR→RGB
inputs = processor(images=img_pil, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_object_detection(
outputs, target_sizes=target_sizes, threshold=confidence
)
# ... map classes, deduplicate, sortSem thresholds mágicos. Sem perfis separados pra cor vs P&B. Sem CLAHE. Sem detecção por borda. Sem watershed. Sem 7 camadas de filtro. Um modelo que foi treinado em 11.000 imagens diversas de quadrinhos já sabe distinguir balão de rosto melhor do que meus montes de “ifs”.
O que também sumiu junto:
- O
text_detector.pyinteiro (387 linhas) — substituído pela classetext_freedo RT-DETR - O sistema de feedback de falsos-positivos — RT-DETR detections são confiáveis o suficiente pra não precisar de marcação manual
- Centenas de linhas de testes de regressão testando false-positives específicos
No final, nem precisei tentar fazer fine tuning próprio. O modelo que já existe resolvia mais de 99% dos casos, o que pra mim já era excelente.
Quem não entende estatística tem dificuldade de entender isso. Com meu procedimento “manual” de opencv eu já conseguia pegar 80%, talvez mais. Mas isso é muito pouco. Se em toda página um rosto fica com um balão em cima, isso é péssimo.
Mesmo se com muito esforço (mais quinhentos “ifs” diferentes) conseguisse chegar em 95%, ainda assim não é suficiente. Chegar em 80% é fácil. os últimos 20% custam exponencialmente mais, e o último 1% pode ser impossível em muitos casos. É assim que as coisas funcionam. Todo mundo pára nos 80%.
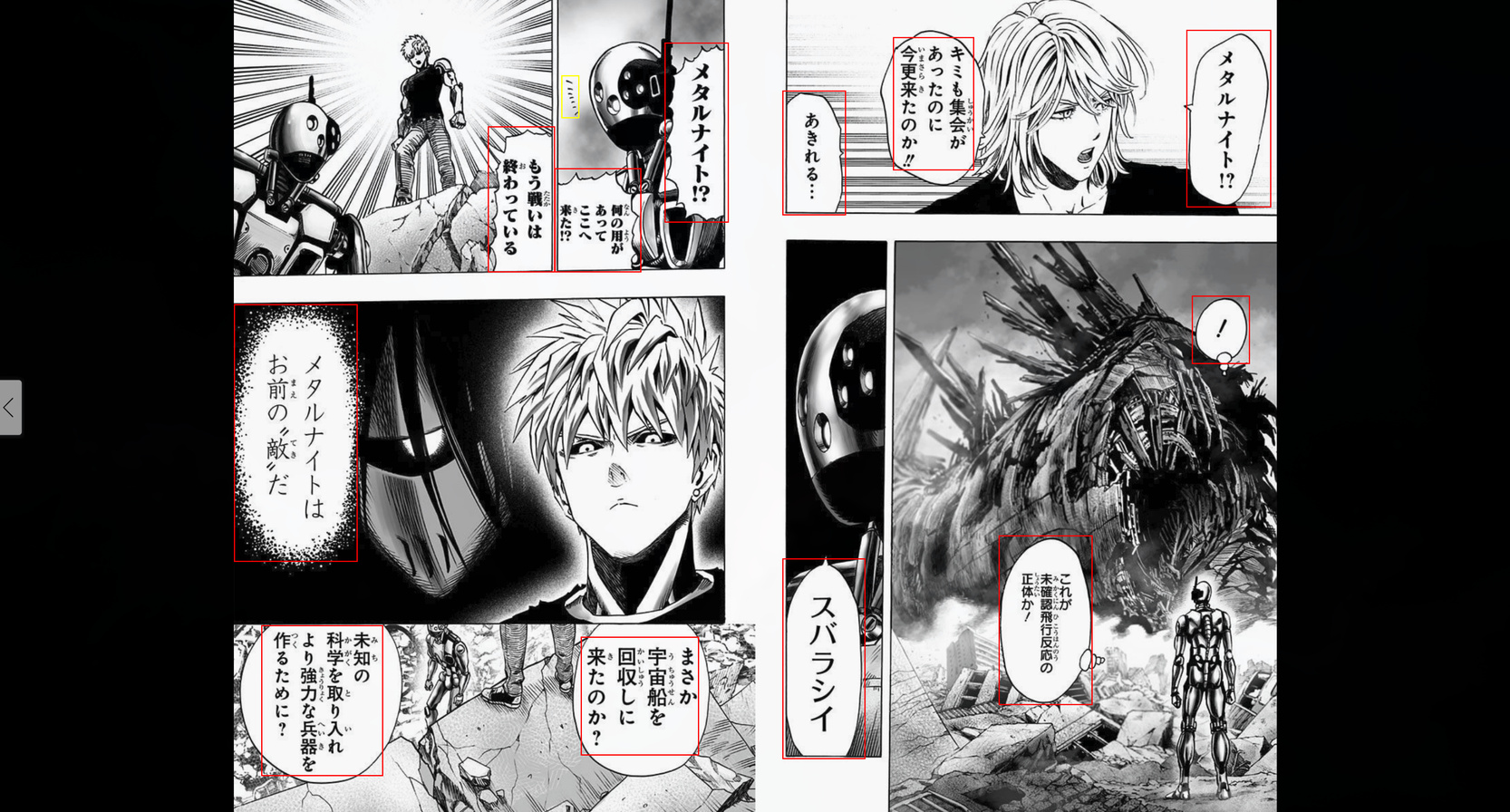
As Outras Dores: Flutter no Linux
Enquanto o backend em Python e Go foi relativamente estável, o cliente Flutter no Linux foi um capítulo à parte de sofrimento.
O Flutter usa WebKitGTK pro WebView no Linux, e esse componente tem particularidades dolorosas. Commit 8e5d168 (28/fev) conta a história: WebKitGTK não consegue resolver Promise return values de JavaScript assíncrono, gerando PlatformException. Tive que reescrever todos os overlays como IIFEs síncronas com decode().then() e um nudge de opacity: 0.999 pra forçar refresh da textura no compositor GPU.
No meu setup com NVIDIA + Wayland, o WebView era inutilizável em resolução full. Commit a36e1eb (27/fev) tentou resolver forçando CPU rendering com WEBKIT_SKIA_ENABLE_CPU_RENDERING=1 e desabilitando compositing acelerado. Depois tive que reverter isso (commit 8e5d168) e forçar o Mesa da iGPU AMD via __EGL_VENDOR_LIBRARY_FILENAMES pra impedir que o WebKitGTK pegasse a dGPU NVIDIA.
Cada uma dessas descobertas custou horas de debugging de coisas que simplesmente não tinham documentação. No final consegui deixar a versão Linux razoável, mas não é nada espetacular. Não sei se estou perdendo alguma coisa óbvia, mas Flutter no Linux eu achei uma droga, especialmente tendo acabado de fazer um app nativo com Rust/Tauri (muito melhor). Mas como eu queria um app que funcionasse em Linux e Android, não tinha tanta opção.

O Prefetch do Kindle que Morreu
Uma ideia que parecia genial e que deu errado: criar um segundo WebView escondido no Flutter que compartilhava cookies/sessão com o WebView principal e ficava navegando páginas à frente pra pré-processar.
Isso porque o website do Kindle só carrega uma página de cada vez. Ele não carrega tudo de uma vez ou partes, só uma página. Então não dá pra processar páginas pra frente ou pra trás. Quando o servidor ainda era lento pra processar páginas, eu queria deixar tudo já pré-cacheado, pra quem virar a página já tivesse a tradução.
Commit a36e1eb (27/fev) implementou o KindlePrefetchManager inteiro: 406 linhas de Dart, com batched prefetch (3 páginas à frente), eventos GDK confiáveis pra virar página (isTrusted=true), rate limiting com pacing humano, janela com sensitive=FALSE pra não roubar foco.
Nos dias seguintes, vieram os consertos:
cfe08eb: melhorar confiabilidade do prefetch e matching de overlay4461b5f: harden na seleção de overlay e recovery do Kindlef141b2e: parar de destruir o background webview a cada virada de página
E no final (commit 2b93e99, 4/mar), deletei tudo. 657 linhas removidas, substituídas por um spinner simples na toolbar.
Com a mudança pro modelo RT-DETR, e paralelizando a tradução dos balões, a tradução ficou “quase real-time”, em menos de 10 segundos já carregava a tradução, então não é mais um dor tão grande esperar vir a página, e dá pra pedir um de cada vez. O prefetch adicionava complexidade demais pra um ganho marginal, e o modo certo de resolver era simplesmente processar a página sob demanda com feedback visual adequado.

Os Números
No total, o projeto Frank Yomik tem hoje:
- 111 commits em 9 dias de desenvolvimento (com 2 dias de intervalo no meio)
- 29.428 linhas de código em 181 arquivos
- ~13K linhas de Python (pipeline de processamento + worker)
- ~6K linhas de Dart (cliente Flutter)
- ~3.4K linhas de Go (API server)
- 345 testes unitários + 34 testes de integração
- Suporte a manga japonês (Kindle) e webtoons coreanos (Naver/Webtoons)
O pipeline hoje funciona assim:
- O cliente Flutter (Android ou Linux desktop) abre o site do Kindle ou Webtoons num WebView
- Captura a imagem da página (captura do blob de imagem na página do Kindle, fetch do
<img>pra webtoons) - Envia pra API Go que enfileira no Redis Streams com dedup por SHA256
- Worker Python processa: RT-DETR-v2 detecta balões → manga-ocr ou EasyOCR extrai texto → Ollama qwen3:14b traduz → text_renderer renderiza de volta na imagem
- Resultado volta via WebSocket, overlay substitui a imagem original
Pra furigana: fugashi (wrapper do MeCab) faz análise morfológica e gera a leitura em hiragana de cada kanji. Troquei de pykakasi pro fugashi porque o pykakasi não considera contexto da frase (「人」 virava にん em vez de ひと).

Se eu soubesse o que sei agora — que o modelo RT-DETR-v2 já existia e resolvia o problema de detecção com um threshold de confiança — teria eliminado a fase inteira de OpenCV. A parte de OCR, tradução, rendering e Flutter já estava razoavelmente estabilizada. A detecção era o gargalo, e era exatamente a parte que eu poderia ter economizado, se tivesse desistido antes.
O que eu aprendi errando
Eu gastei 5 dias polindo um detector de balões em OpenCV que teve 20+ commits de ajuste fino, 7 camadas de filtro, 3 passes de detecção, e que no final foi substituído por um wrapper de 50 linhas ao redor de um modelo pré-treinado.
Foram 1.112 linhas deletadas num único commit. Mas não foi tempo perdido. Aqueles 5 dias me ensinaram exatamente porque heurísticas falham em visão computacional. Eu entendi o problema, a cascata onde mexer num threshold quebra outro, e foi esse entendimento que me fez reconhecer a hora de parar e pesquisar alternativas.
E aqui entra o papel real do vibe coding nessa história.
Prompting não substitui pensar.

Eu gerei código muito rápido com Claude, mas o problema não era velocidade de escrita, era a abordagem. Nenhum prompt do mundo transforma 7 camadas de filtro heurístico numa solução robusta. A solução certa era mudar de abordagem completamente.
Mas o vibe coding tornou o fracasso barato. Nos tempos pré-AI, aqueles 5 dias de OpenCV teriam talvez sido 2-3 semanas. O custo de errar seria alto o suficiente pra dificultar a decisão de jogar fora. Com vibe coding, 5 dias foram descartados sem dor porque eu sabia que podia reconstruir rápido. E de fato, a integração do RT-DETR-v2 e reestruturação do projeto inteiro foram feitos em um único dia (4/mar, 15 commits).
A pergunta que fica: se eu tivesse feito a pesquisa do yolo_bubble_detection_plan.md no dia 1 em vez do dia 5, provavelmente teria chegado no estado atual em 2 dias. A diferença entre semanas de trabalho e um fim de semana era uma busca no HuggingFace. Pesquisar antes de implementar parece óbvio quando você olha pra trás, mas no calor do momento a tentação de resolver na mão é forte.
O projeto agora é open source. Eu inicialmente não sabia se queria abrir o código, tinha muita gambiarra e aquele detector de 551 linhas que eu tinha vergonha. Mas depois da refatoração, o código ficou limpo o suficiente pra compartilhar. É a versão que eu gostaria de ter construído desde o início, mas que só consegui construir porque errei primeiro.
A dor de cabeça maior foi o modelo de detecção e substituição de balões, mas ainda tem vários outros pontos que não detalhei: notaram que Webtoons são coloridos e os próprios balões tem arte? Precisei usar um modelo de imagem pra fazer in-painting e mandar a IA redesenhar o balão antes de colocar o texto em cima.
Outra dor de cabeça que acho que não vou resolver: coerência da tradução. Hoje ele traduz cada balão isolado, sem contexto da história antes ou depois. Em japonês, não existe diferença de gênero em palavras. Então o capitão estava falando da Nami mas o balão fala “Ele” em vez de “Ela”. Não tem como saber se não ler o texto anterior. Pra isso funcionar melhor, assim como num chat de GPT, precisa adicionar parte do texto anterior, pra saber quando usar o gênero correto ou, pior, quando tem trocadilhos que apareceram volumes atrás e é referenciado no futuro (coisa que um Oda adora fazer). Essas sutilezas todas se perdem se traduzir só um balão de cada vez.
Imagino que é por isso que ainda ninguém fez algo parecido com o que eu fiz, de traduzir em tempo quase real, porque pra realmente ficar bom, o trabalho de tradução seria exponencial pra cada capítulo mais pra frente na história.
Enfim, o nome Frank Yomik vem de “yomi” (読み, leitura em japonês) e “ik-da” (읽다, ler em coreano). Frank é referência à tradução franca, direta. O app lê nas duas línguas.

Pra quem quiser experimentar: o repositório está no GitHub. O server precisa de uma GPU com pelo menos 8GB VRAM pro modelo de detecção + OCR + tradução. O cliente Flutter roda em Android e Linux desktop. E se você, como eu, tem uma pilha de mangás japoneses que gostaria de ler mais fluentemente — agora pode.