AI Agents: GLM 4.7 Flash é realmente tão bom assim?
Recentemente fiz um post comparando várias LLMs. A boa notícia é que as LLMs comerciais estão bem impressionantes mesmo. Mas a má notícia é que nenhuma LLM open source foi capaz de realizar meu desafio de programação (leia no post anterior pra entender o desafio).
Também recentemente, a ZAI lançou a versão 4.7 do seu famoso modelo “GLM” que é um modelo de 30 bilhões de parâmetros, encodado em BF16, que precisa na faixa de 60GB de VRAM pra caber inteiro numa GPU. Ou seja, é pesado.
Ainda mais recentemente, ela lançou a versão GLM 4.7 Flash que é o mesmo modelo de 30 bilhões de parâmetros, mas quantizado (a grosso modo: “comprimido” ou “truncado e re-normalizado”), que cabe numa GPU de pelo menos 32GB, que é o caso da minha RTX 5090.
Sim, a GPU caseira mais cara do mercado é o mínimo necessário pra rodar os melhores modelos open source. Isso porque o importante não é o poder de processamento e sim a quantidade de VRAM. Por isso um Mac Studio, com GPU tecnicamente mais “fraca”, tem vantagem em LLMs porque ela compartilha com a RAM, com máximo teórico de 512GB. Então cabem os maiores modelos sem problema nenhum.
Outras opções são Mini PCs com CPU AMD Ryzen AI Max+ com capacidade de compartilhar até 128GB de VRAM.
O desafio era ver se eu conseguia rodar o GLM 4.7 Flash localmente na minha máquina.
TL;DR: GLM 4.7 Flash é possivelmente o melhor LLM open source - com alguns poréns.
VLLM vs LM Studio vs Ollama
Na página oficial deles tem documentação de como rodar em VLLM e já aviso que não funciona. Ele exige funcionalidades que só tem na branch master dos projetos VLLM e transformers e vai dar uma dor de cabeça com conflitos de versões e resolução de dependências e mesmo assim, no final, eu não consegui fazer ele rodar direito.
LM Studio também não funciona. Ele tem a opção pra baixar o modelo, e eu tentei tunar todos os parâmetros possíveis. Quantização do KV Cache, layers na GPU, CPU threads, etc etc. Mas não importa, o modelo até carrega mas roda absurdamente lento. Tão lento que é inusável. Acho que é porque ele só consegue baixar o modelo BF16, então metade dos layers não cabe na GPU. Portanto, até a data deste post, não dá pra usar nem LM Studio e nem VLLM.
Mas aí eu vi um tweet dizendo que finalmente Ollama ia suportar GLM 4.7, mas novamente, até a data deste post, ainda não está na versão estável. A única forma de usar é compilando do código fonte as coisas que estão no branch master deles.
git clone https://github.com/ollama/ollama.git
cd ollama
cmake -B build
cmake --build build
go build -v .No último comando vai parecer que travou porque nada aparece na tela, mas é porque ele está compilando centenas de arquivos de C++. Só esperar que uma hora acaba. E finalmente dá pra rodar:
OLLAMA_FLASH_ATTENTION=1 \
GGML_VK_VISIBLE_DEVICES=-1 \
OLLAMA_KV_CACHE_TYPE=q4_0 \
OLLAMA_CONTEXT_LENGTH=45000 \
go run . serveEsses são os parâmetros pra conseguir caber tudo nos 32GB de VRAM e não ficar fazendo offload pra CPU. 45 mil tokens é o máximo, talvez até um pouco menos pra garantir que o KV Cache vai caber.
Além disso precisa quantizar em 4-bits com q4_0. O normal são floats 16-bits. Pra caber vamos ter que truncar (perder precisão).
No meu caso, eu tenho uma iGPU AMD. Pra evitar que o ollama fique tentando usar ela, tem essa opção GGML_VK_VISIBLE_DEVICES=-1. Isso deve garantir que só a nvidia vai ser usada.
Finalmente, habilitamos Flash Attention pra tentar reduzir crescimento de memória à medida que janela de contexto aumenta.
Trade off: velocidade vs contexto
O GLM 4.7 Flash é um modelo com 48 layers. Na configuração que mostrei acima, vai caber todos os 48 layers na GPU. Mas uma janela de contexto de 45k pode ser muito pequeno dependendo do seu uso. Você mesmo vai ter que testar.
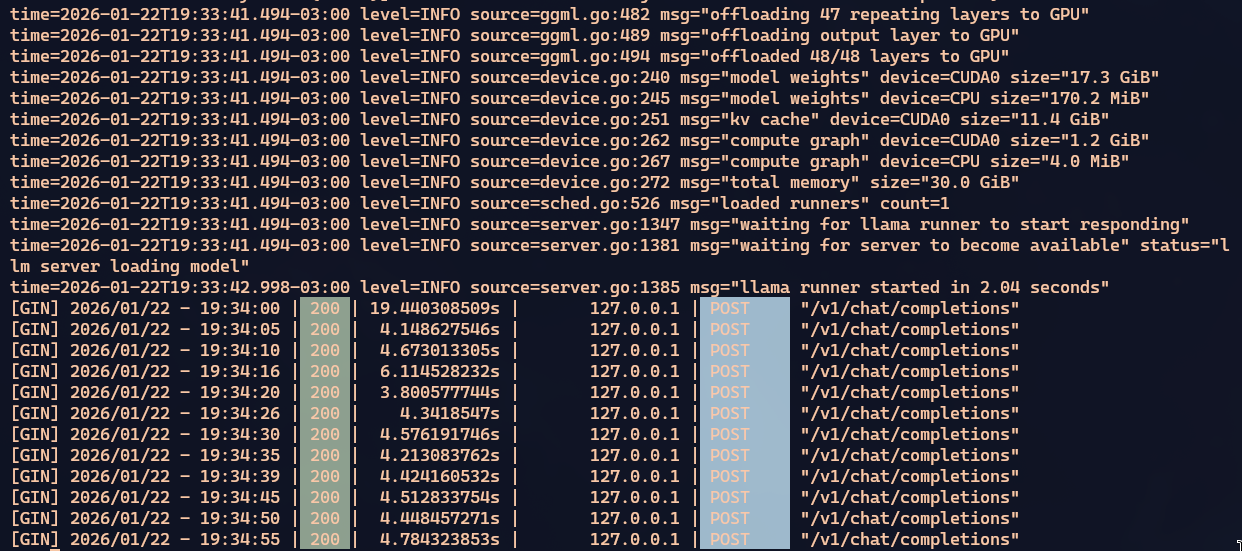
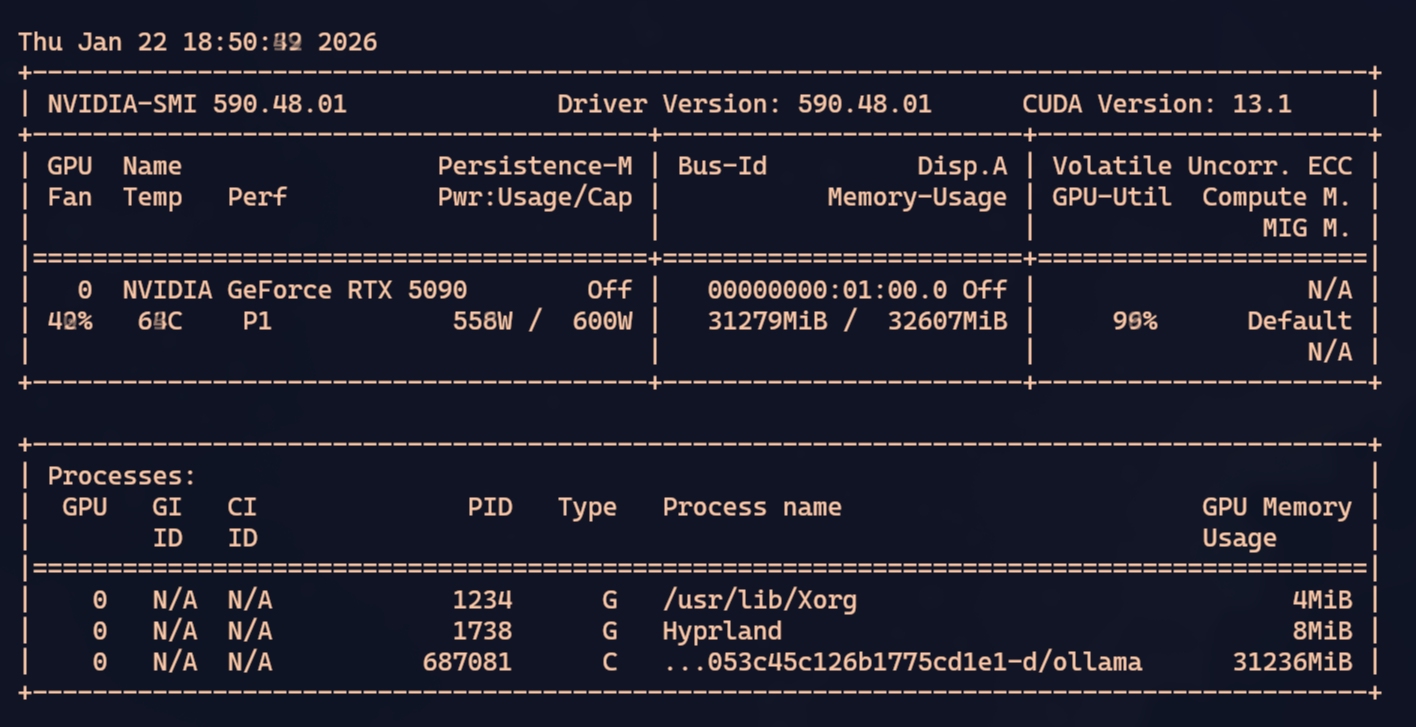
Quando cabe tudo na GPU, o processamento é razoavelmente rápido. Um pouco mais lento mas ainda comparável a um Qwen3 Coder ou GPT-OSS. Dá pra saber que está tudo na GPU porque olhando BTOP a CPU está sem processar nada e ao mesmo tempo nvidia-smi mostra que a GPU tá puxando na faixa de 500W dos 600W que ele consegue.
Nos meus testes, dependendo do que estiver fazendo, esses 45k enchem MUITO RÁPIDO. Usando ferramentas como OpenCode ou Crush, quando chega perto de encher, eles pedem pra LLM sumarizar o que foi conversado/pesquisado até agora, gravar e reiniciar com o resumo. Mas mesmo assim, os resumos também vão ficando grandes.
Em agentes, ele vai executar comandos no seu sistema (compilar, listar arquivos, pesquisar trechos de código, pesquisar na web) e tudo isso vai consumir contexto. Quanto mais contexto tiver sobrando, melhor.
Eu andei testando com OLLAMA_CONTEXT_LENGTH=65576, faixa dos 65k tokens. Isso vai impedir todos os layers de ficarem na GPU e o Ollama vai ter que ficar fazendo swap, usando CPU. Portanto, o processamento vai ficar bem mais lento. MAS, a janela de contexto vai ser maior. É um trade-off.
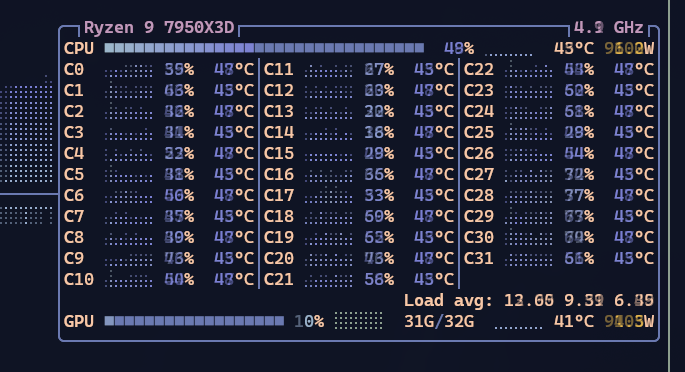
De cara, você vai ber que a CPU vai começar a puxar. Na minha 7850x3d fica puxando 50% constantemente. Veja os tempos das respostas do Ollama como ficou lento:
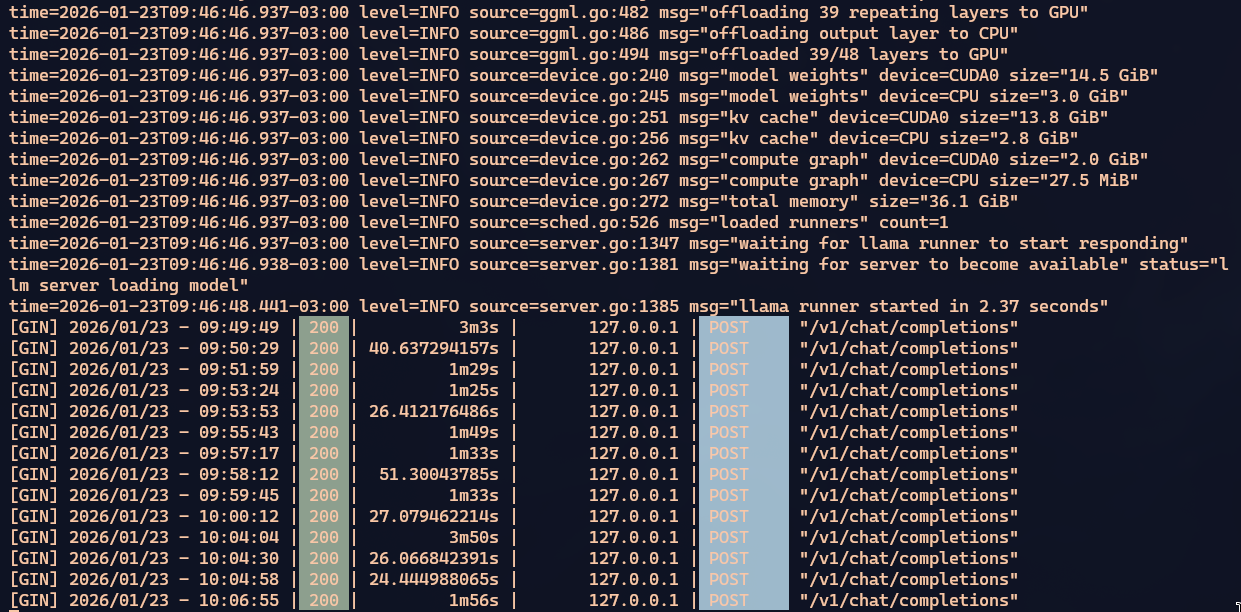
Vai da faixa de 4 segundos pra 90 segundos. 20x mais lento. E isso porque 39 dos 48 layers estão na GPU. Por isso eu acho que não dá pra aumentar mais que 65k. O ideal é manter em 45k mesmo, mas no caso do meu desafio, senti que precisava compensar.
Ou o Crush/OpenCode vai demorar porque a janela acaba rápido demais e toda hora precisa sumarizar o trabalho e perder detalhes do contexto - o que dá mais trabalho em pesquisar a mesma coisa mais de uma vez. Ou preserva mais detalhes do contexto por mais tempo, mas aí todas as respostas ficam mais lentas. É um trade-off bem difícil. E a culpa de tudo é a porcaria dessas placas de video terem tão pouca VRAM.
Se usar um Mac Studio que vai até 512GB ou algum Mini-PC com AMD Ryzen AI Max+ que vai até 128GB, não teríamos que lidar com esse limite. Mas são máquinas que custam acima de BRL 20 mil. Não dá pra justificar. Por esse preço é melhor só pagar créditos na OpenRouter e usar modelos comerciais maiores e mais rápidos como Claude Opus ou GPT 5.2, ou o próprio GLM 4.7 no cloud da ZAI.
Pull Request no Crush
Como side-quest, tive um pequeno problema que tava me incomodando. Um dos problemas de uma janela de contexto pequena, é que de tempos em tempos o Crush ficava parando, mesmo ainda tendo trabalho pra fazer. O motivo é porque o contexto encheu antes dele ter tempo de sumarizar daí quando vai fazer uma chamada de ferramenta (“tool calling”), que é um XML grande, ele trunca por falta de espaço.
XML truncado é inválido, ele não consegue chamar ferramenta e crasheia o processamento, assim:

E mesmo tentando controlar o limite de uso da memória, eventualmente esse teto vai quebrar e o processamento vai parar por falta de memória:

Seja por XML truncado, seja por OOM do ollama, eventualmente o processamento pára. E como é um processamento lento, é um saco ter que ficar esperando isso acontecer e reiniciar o processo manualmente.
Por isso resolvi ver se tinha como fazer o próprio Crush detectar que parou por causa desses motivos e auto-continuar de onde parou. Abri o próprio Crush em cima do projeto do Crush e pedi pro Claude Opus checar a possibilidade de uma correção.
Sim, eu fiz um pull request 100% vibe coded com o próprio Crush pra consertar o Crush 😂 Vamos ver se o povo do Crush vai aceitar. Eu tentei o máximo não fazer um AI Slop.
De qualquer forma, com isso eu consigo deixar o agente rodando horas sem parar até chegar onde eu quero.
Conclusão
Este NÃO é o jeito certo!
Deixando claro que largar um agente fazendo coisas sozinho sem ninguém ver é uma má-prática. No meu caso é um exercício isolado. Eu estou usando meu AI JAIL e eu já rodei esse prompt várias vezes como benchmark e sei bem o comportamento de todas as LLMs.
Como disse no meu post anterior, o prompt do meu desafio é cheio de más práticas que você não deve fazer: eu peço muitas coisas complexas ao mesmo tempo, com pouco contexto, de forma vaga e confusa, justamente pra ver como a LLM vai se virar pra resolver. No dia a dia você deve mandar prompts pequenos, tarefas unitárias objetivas e bem espefícas, com boa explicação e contexto, pra que as respostas sejam rápidas e curtas. Um passo de cada vez.
O objetivo do meu desafio é justamente puxar um pouco os limites do senso comum. Com a idéia de que se passar pelo meu desafio, deve conseguir passar por prompts mais simples do dia a dia.
E nesse desafio que só as LLMs comerciais conseguiram passar: Claude Opus, GPT 5.2, Gemini 3. Mas nenhum open source conseguiu, nem Qwen3 Coder, nem GPT-OSS, nem minha primeira tentativa com GLM 4.7 cloud e nem MiniMax v2.
Mas este novo GLM 4.7 Flash me deu esperanças. Ele não entrou em “agentic loop” como o Qwen3 - que sempre chega num ponto onde ele pára de tentar resolver e só repete “já terminei”, sem ter terminado.
Também não ficou crasheando a toa. Toda vez que parou o processamento, foi por falta de memória. E mesmo assim, mandando “continuar” via prompt no Crush, ele consegue pegar de onde parou e continuar.
Cada correção que ele faz tem sentido. Não vi fazendo tangentes fora do escopo como vi o Gemini fazendo muitas vezes. Quando tem dúvidas, consegue pedir um “agentic fetch” e ir pesquisar na web antes de continuar. Toda vez que faz correções ele sabe executar o comando de build pra ver se tem erros de compilação.
Gostei que tenta corrigir um pequeno erro de cada vez em vez de tentar ficar reescrevendo tudo ou resolvendo mais de um problema ao mesmo tempo.
No final, foi o único open source que fez o build funcionar e gerar um binário.
Não dava pra fazer ele testar o programa porque ele precisaria carregar outra LLM numa GPU que já estava com LLM, então eu parei o teste sem resolver bugs de runtime. E também não pedi pra ele refatorar porque já tinha levado tempo demais. Ele já tinha superado os outros OSS então parei por aqui. Eis o pull request com as correções de build que ele fez. Simples, sem mexer onde não precisa e faz o que foi pedido.
Ou seja, dos open source, foi o que vi o melhor comportamento, comparável ao que vi o Claude Opus ou GPT 5.2 fazendo. Considerando que esses modelos comerciais tem trilhões de parâmetros, rodando nos servidores mais parrudos com NVIDIA H200, eu considero que esse GLM, de só 30 bilhões de parâmetros, rodando numa mísera 5090 local, está se saindo impressionantemente bem.
Os trade-offs são claros: ele é ordens de grandeza mais lento que um Claude Opus. Mas é melhor um modelo lento que chega no mesmo resultado, do que um rápido que entra em loop infinito achando que já resolveu tudo sem ter feito nada, como o Qwen3.
Acho que pra desafios como o meu: prompt gigante, que exige muito contexto pra conseguir resolver, não é bom pra nenhum modelo open source. Mas se eu fosse começar um projetinho pequeno do zero, com tarefas simples e curtas, imagino que o GLM 4.7 resolveria sem nenhuma dor de cabeça, custando zero e preservando minha privacidade ao rodar 100% local e offline.
Recomendo: GLM 4.7 Flash é o melhor modelo OSS do começo de 2026.