AI Agents: Comparando as principais LLM de 2026 no Desafio de Zig
Neste começo de 2026 me empolguei em fuçar LLMs de novo. Duas razões pra isso: testar o Charm Crush (alternativa a OpenCode, Cursor, etc) e testar LLMs novas como Claude Opus e GPT Codex pra ver como estão hoje em dia.
Antes de entrar nos detalhes, vamos a alguns disclaimers: tudo que vou dizer agora é baseado num problema de código relativamente simples e curto - que vou explicar na próxima seção.
Não use isso pra generalizar pra qualquer projeto, de qualquer tamanho ou complexidade. Este é um artigo puramente opinativo e não analítico.
Como vai ser longo e vou tocar em muitos assuntos diferentes, vou começar com o TL;DR pra quem tiver preguiça de ir até o fim:
- As principais LLMs comerciais hoje em dia parecem ser Claude Opus 4.5, GPT 5.1 Codex, GPT 5.2 (não tive acesso ainda ao GPT 5.2 Codex, que dizem que é muito melhor), Gemini 3 Pro Preview.
- As principais LLMs open source hoje em dia continuam sendo Qwen3-Coder, GPT-OSS, Deepseek v2 e os novos GLM 4.7 e MiniMax v2
Sem mais delongas, de longe o melhor - no meu pequeno teste - foi o Claude Opus. Foi por causa dele que resolvi testar os demais pra ver como se comparam. Foi o único que resolveu o problema logo de primeira, sem eu precisar fazer prompts adicionais nem ficar insistindo, e foi o mais rápido também, por uma longa margem.
Mas os 3 comerciais que testei conseguiram resolver. Alguns deram mais trabalho, mas todos resolveram no final. Mais detalhes a seguir, mas meu ranking é nesta ordem:
- Claude Opus
- GPT 5.1 Codex
- GPT 5.2
- Gemini 3 Pro Preview
Já dos open source, nenhum conseguiu resolver meu problema. Então continua como 1 ano atrás. Eu tive esperanças com o GPT-OSS de 20 bilhões de parâmetros e Qwen3-Coder de 30 bilhões - que cabem nos 32GB de VRAM da minha RTX 5090 - tivessem melhorado, mas não. O GLM 4.7 e MiniMax v2.1 são grandes demais. Eu tive que rodar pelo OpenRouter.ai.
Não quer dizer que eles são inúteis, mas pro tipo de problema que tentei resolver, nenhum foi muito bem. Meu ranking ficou assim:
- MiniMax v2.1 (muito demorado, mas conseguiu fazer compilar mas não resolveu um erro de runtime)
- GPT-OSS:20b (não conseguiu fazer compilar, mas foi mais rápido)
- Qwen3-Coder:30b (não conseguiu fazer compilar)
- GLM 4.7 (muito demorado, não conseguiu fazer compilar e uma hora parou de funcionar completamente - possível bug no Crush)
Antes que comecem a comentar “Mas e o DeepSeek??” - já aviso que eu não consegui usar ele. Vou explicar depois.
Minha recomendação é, na dúvida, comece pelo Claude Opus ou GPT 5.1 Codex. Ambos são equiparados, cada um pode ser melhor em determinados tipos de problemas.
Agora vamos explicar o problema.
O Desafio de Zig
Um ano atrás experimentei tentar “vibe coding”. Mas não pra fazer um to-do list web básico. Resolvi que eu queria fazer um app de chat em linha de comando, que carregasse um modelo open source como Qwen, e eu pudesse conversar com ele. É o que um ollama ou VLLM já fazem, mas eu queria fazer do zero.
Pra ter alguma dificuldade, pensei o seguinte:
- uma linguagem de baixo nível que ninguém usa (então tem pouca documentação, foruns e exemplos na web). Por isso escolhi Zig
- integrar com uma lib em C ou C++ pra dificultar ainda mais e misturar linguagens de baixo nível. Por isso não é só um cliente pra conversar com um servidor de Ollama, tem que usar a lib Llama.cpp direto. Eu quero carregar o modelo diretamente.
Em resumo: foi um enorme parto!!!
A experiência foi tão ruim - não lembro se na época eu estava usando Gemini 2.5 ou Sonnet - que nunca cheguei num ponto onde o código sequer compilasse. E eu larguei esse projeto inacabado mesmo.
Eis o repositório com o código inacabado.
Passado um ano e com novas versões de LLMs, é um bom problema pra retornar, ainda mais porque temos as seguintes novas dificuldades:
- Zig lançou versão nova, a 0.15.x, que muda MUITA coisa. Sendo uma linguagem ainda em desenvolvimento e pré-1.0, significa que cada nova versão muda APIs de tudo e quebra tudo.
- Llama.cpp também evoluiu e lançou versões novas que também quebram compatibilidade.
Mas hoje temos orquestradores melhores que o Aider, que eu usava na época: OpenCode e Crush existem.
O desafio é simples: atualizar o código pra ser compatível com Zig 0.15 e o novo Llama.cpp. Consertar o build e corrigir cada um dos erros. Conseguir gerar um executável. Conseguir fazer ele rodar, carregar o modelo Qwen3 na minha GPU e abrir um chat interativo que eu consiga conversar com a LLM. E sem dar crash, nem memory leaks.
Deixa eu dar alguns exemplos do que precisa consertar. Pra começar, o comando zig build já nem roda porque mudou a API pra declarar módulos pra compilar. Veja este pequeno trecho:
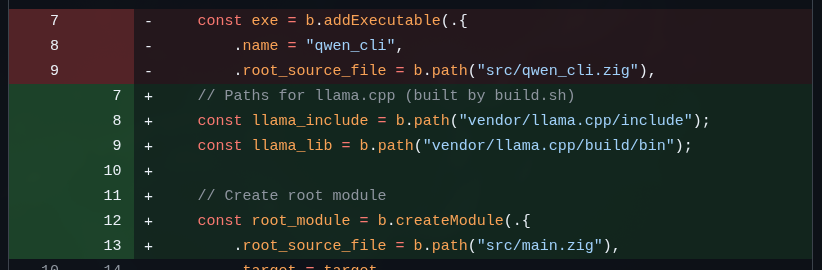
Praticamente todas as LLMs conseguiram passar este problema. Alguns demoraram mais, mas pelo menos todos conseguiram ter um build. Daí é corrigir os erros que aparecem no build. Eis um exemplo:
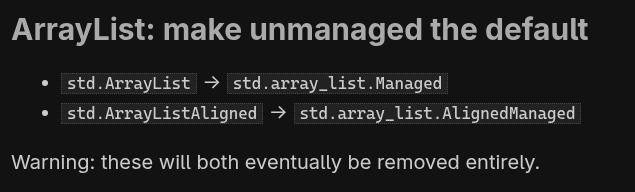
ArrayList mudou na versão 0.15. E esse problema foi um que metade das LLMs penou MUITO pra conseguir resolver. Isso envolve “Agentic Fetch”, ir pra web e consultar o documento de migração e exemplos de código. Não é tão difícil assim, mas alguns levaram mais de hora e quase não conseguiram.

Este é um trecho de como mapear funções de C (do llama.cpp) pra dentro do Zig. A maioria teve vários problemas pra resolver isso. Precisa consultar o llama.h que está no código fonte em ./vendor/llama.cpp. Alguns até conseguiam fazer compilar. Mas não garante que funciona. Quando eu carregava o binário, dava segmentation fault e outros crashes. Precisava saber quais funções podia usar, como lidar com NULLs e coisas assim. A maioria não conseguiu passar desta parte.
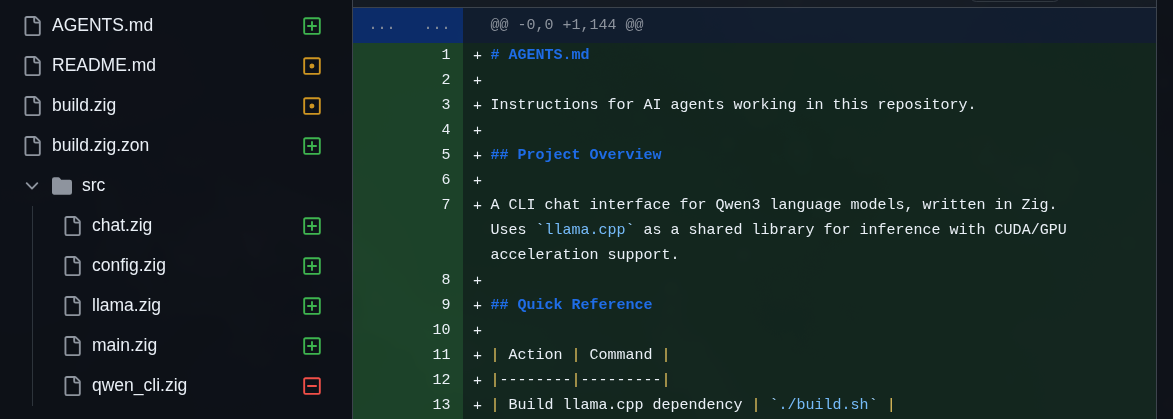
E só pra piorar, eu ainda pedi pra refatorar o código em arquivos menores. A versão inacabada original era um único qwen_cli.zig gigantesco. Refatorar não foi tão difícil e todos os comerciais conseguiram fazer. Os open source não chegaram até este ponto.
Finalmente, pra piorar mesmo, eu dei o pior prompt possível pra eles:
“my zig code is quite old and certainly incompatible with the newest zig 0.15.x (that I am currently using). I need you to think hard and research the web for documentation, migration guides and example snippets to update my code. You must run it against
zig buildand fix each new error until the build ends successfully. I don’t want you to litter my project with temporary files, mockups, do the changes in-place without breaking its behavior: avoid commenting my code out just to make it compile. more than compiling successfully, the program should keep doing what it was meant to do. The project also builds against llama.cpp, present at./vendor/llama.cpp. Be particularly careful about memory management and freeing resources. It’s best to also check header files to know if extern function mapping changed and fix those as well. the qwen_cli.zig is also massive, it would be good to at least refactor into more manageable files. can you do it?”
Nunca faça prompts assim:
- muitas tarefas diferentes num mesmo prompt - prefira tarefas pequenas e bem isoladas
- muitas mudanças que podem afetar o arquivo inteiro ou outros arquivos
- pedindo pra refatorar junto de corrigir bugs
- mal explicado, vago
Ano passado nenhum conseguiu. Vamos ver agora.
OpenCode e Crush
Esta seção é curta. Eu já postei sobre Crush alguns dias atrás. Alguns perguntaram sobre OpenCode. Na real, ambos parecem fazer praticamente a mesma coisa. Até a interface é parecida. Claro, internamente eles devem ter heurísticas diferentes. Testei muito pouco o OpenCode mas eu acho o Crush bem mais bonito. Só por isso uso mais ele. Vejam:
Visual é subjetivo, escolham qual acharem melhor. Uma única coisa que vi que o OpenCode faz automaticamente é carregar LSPs. No Crush eu acho que precisa editar o arquivo crush.json manualmente, mas posso não ter lido alguma coisa na documentação. Me corrijam se eu estiver errado.
Ambos são igualmente competentes em orquestrar o trabalho. O resultado é realmente muito melhor do que eu abrir uma aba de ChatGPT e ficar copiando e colando código manualmente. Ano passado não era tanto assim, mas agora no começo de 2026, tenho que dizer que sim: eles são competentes como assistentes de programação.
LLMs Open source
Deixa eu começar com as opções open source: infelizmente fiquei bastante desapontado. Não tenho como testar todas as opções que existem mas eu esperava mais. Mas não estou sendo justo: as LLMs comerciais rodam em infra própria e por isso tem capacidade pra carregar modelos muito maiores.
Claro que modelos menores vão ser qualitativamente inferiores também. GPT, Claude, Gemini, todos são da ordem de TRLHÕES de parâmetros. Já os maiores open source são na faixa de 300 BILHÕES de parâmetros. Não tem comparação mesmo. Pra tarefas simples funciona, mas pro meu desafio, não é suficiente.
Pra piorar, a GPU topo de linha hoje, como a minha RTX 5090 tem míseros 32GB de VRAM. Portanto é impossível carregar modelos maiores que uns 30 bilhões de parâmetros, e isso com muita quantização.
Pra rodar os de 300 bilhões precisa de um Mac Studio de 512GB de RAM compartilhada que não vai sair por menos que USD 4000 (nos EUA). Pra mim, que não vou usar todo dia extensivamente, não compensa.
Eu só consegui rodar localmente o Qwen3-Coder:30b ou o GPT-OSS:20b. E mesmo sendo tão pequenos, eles são muito impressionantes. Só não potentes o suficiente pra resolver o meu desafio de Zig.
Mesmo assim, eles já são bem velhos. O Qwen3 eu testei um ano atrás, depois saiu o GPT-OSS, mas em 2026 dizem que os melhores são o GLM 4.7 que pesa nada menos que 400 GB em disco. E tem o MiniMax v2.1, que parece que tem na faixa de 230 bilhões de parâmetros.
No site do ollama nem tem como baixar esses modelos. Eles rodam na opção “cloud” que, pelo que entendi, vai rodar na infra do ollama, e não na sua máquina.
Eu até consegui carregar alguns segmentos do GLM 4.6 Flash e MiniMax 2.1 na minha máquina. Mas como tem que ficar carregando e descarregando segmentos entre a GPU e a CPU (RAM e VRAM), é extremamente lento, na faixa de 1 token por segundo. Na prática, não dá pra usar. Só com um Mac Studio parrudo.
Ou então criando uma máquina virtual num cloud como RunPod. Mas aí vou pagar a mesma coisa, ou até mais caro, do que usar GPT ou Claude. Então não compensa.
Tentei usar tanto LM Studio quanto Ollama, mas fiquei no LM Studio só porque era mais fácil de configurar as coisas. Este é meu ~/.config/crush/crush.json:
{
"$schema": "https://charm.land/crush.json",
"default_provider": "openrouter",
"providers": {
"openrouter": {
"api_key": "sk-..."
},
"lmstudio": {
"name": "LM Studio",
"base_url": "http://localhost:1234/v1/",
"type": "openai",
"models": [
{
"name": "gpt-oss-120b",
"id": "gpt-oss:120b",
"context_window": 100000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"name": "gpt-oss-20b",
"id": "gpt-oss:20b",
"context_window": 130000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"name": "deepseek-coder-v2-lite-instruct",
"id": "deepseek-coder-v2-lite-instruct",
"context_window": 64000,
"default_max_tokens": -1,
"supports_tools": true
},
{
"id": "qwen/qwen3-coder-30b",
"name": "qwen3-coder-30b",
"context_window": 120000,
"default_max_tokens": -1,
"supports_tools": true
}
]
}
}
}E no LM Studio eu configurava coisas como janela de contexto (ia aumentando até ele não conseguir mais carregar por falta de memória). Meus parâmetros eram parecidos com estes:
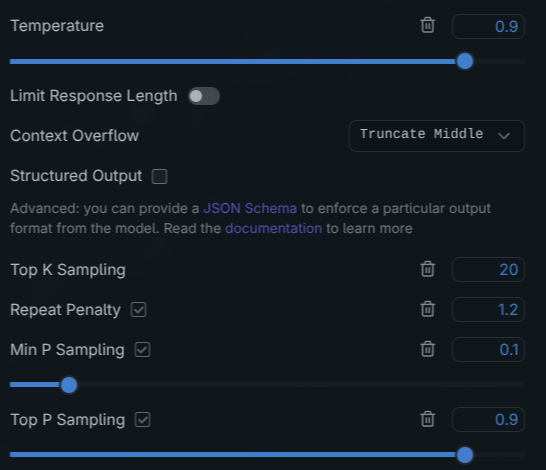
Eu realmente tentei dar todas as chances pros LLMs open source. Quando você baixa e carrega com defaults, ele vem bem conservador.
Por exemplo, no caso do Qwen3-Coder, que foi quem eu mais insisti em tunar. Ele vai tentando corrigir, tenta bastante mesmo, consegue começar o build, consegue passar pelo ArrayList, consegue remapear os externs do Llama.cpp mas o código continua com problemas de compilação.
Eventualmente ele pára de editar o código e começa só a dizer coisas como “Ah, já sei qual o erro, vou corrigir (… não faz nada nos arquivos …) … pronto, terminei a tarefa, já está compilando” e ele nem tenta mais executar zig build, só insiste que já terminou e não faz mais nada.
Isso pode ser o que chamam de Agentic Loop ou Repetitive Reasoning. Primeiro, muitas vezes o modelo é treinado pra te dar uma resposta positiva, e muitas vezes ignora que não consegue e fica repetindo que está tudo bem.
Nesses cenários, o modelo pode entrar numa recursão semântica: ele reconhece o problema, até gera um plano pra consertar, mas por causa do “sampling” ou da janela de contexto ter ficado muito confuso, ele repete o mesmo texto de thinking/reasoning que ele já falou antes (e está no contexto) e acha que está conseguindo.
Modelos comerciais parecem muito melhor treinados e tunados pra evitar isso, mas os open source, com poucos parâmetros e pouco pós-alinhamento, não tem isso bem tunado, então podemos tentar tunar na mão pra ver se ajuda.
Expliquei isso ano passado no artigo de Dissecando um Modelfile de Ollama. Mas relembre do processo: a cada nova rodada pra gerar o próximo token vai calcular e achar vários candidatos, cada um com uma determinada probabilidade.
Se a temperatura for zero, sempre vai responder a mesma coisa. Fica praticamente determinístico. Se a resposta estiver errada, vai devolver sempre o mesmo erro e nunca vai sair disso. Por isso nunca se usa temperatura perto do zero.
Quanto mais perto de 1.0, mais aleatório fica. É quando aumenta a tal da “criatividade”, ao mesmo tempo também aumenta as chances da tal “alucinação”. Existe uma linha muito tênue entre ser criativo e ser só louco mesmo. Não existe um número fixo, tem que ficar testando.
Além disso temos coisas como Top K, Top P, Min P, Repetitive Penalty, Presence Penalty. Expliquei sobre isso no artigo do Ollama mas em resumo:
Normalmente, Min-P costuma ser mais efetivo do que Top-P pra prevenir agentic loops no Qwen. Quando voltam os tais “candidatos de próximo token”, agora precisa ter um “sampling” (literalmente um sorteio). Em um loop os tokens “errados” costumam vir com altas probabilidades (ex. 0.9) e aí o Top-P vai sempre incluir eles. Pra balancear tem o Min-P entre 0.05 a 0.1. Isso corta fora tokens que são significativamente mais prováveis do que os “top” tokens, mas mais importante, dinamicamente ajusta a “criatividade” baseado na confiança do modelo. Isso “agita” o modelo fora da armadilha do repeat penalty.
Isso é complicado, eu me confundo também, mas veja assim. Min-P vai descartar tokens que são menores que 0.05 dentre os tokens de mais probabilidades. A armadilha: quando o Qwen começa a entrar em loop, ele normalmente está mais de 98% confiante numa resposta como “Consegui resolver o problema”. Resultado: em 0.05, Min-P vai jogar fora praticamente qualquer outra alternativa porque não são nem 5% prováveis quanto a resposta do loop.
Pra melhorar isso tem que aumentar o Min-P pra perto de 0.1 e aumentar o Repeat Penalt pra algo entre 1.1 e 1.2 (sim, é apertado assim). Mais que isso e ele vai começar a dar respostas absurdas e quebradas.
Enfim, tudo isso foi pra dizer como eu fiquei ajustando 0.1 pra cima, 0.1 pra baixo.
E isso é pra Qwen3. Já GPT-OSS é diferente. Parece que ele foi treinado pra gerenciar sozinho seu espaço de probabilidade, então os parâmetros que falei atuam diferente. Por exemplo, a OpenAI recomenda mandar a temperatura bem alta, perto de 1.0 mesmo e largar o Top-K pra zero e deixar o modelo lidar com isso. Como falei, não existem números fixos que você aplica em tudo.
Mas mesmo mexendo o máximo que pude, não consegui de jeito nenhum fazer nem Qwen3 nem GPT-OSS conseguirem resolver o desafio. Foram 2 dias inteiros tentando e nada.
GLM 4.7 e MiniMax M2.1 e DeepSeek R1
Ouvi falar nesses dois mas já sabia que não ia rodar na minha máquina. Então nada de tunar também. Fui obrigado a rodar via OpenRouter.
A maior diferença é que tanto GLM quanto MiniMax eu achei bem demorados. Nem tanto em termos de tokens por segundo, mas no processo de reasoning/thinking mesmo. Notei que eles enchem o contexto com sei lá o que, muito rápido e demoram muito pra chegar nuam resposta.
Como todos os outros, eles conseguiram fazer o build funcionar, resolveram o problema de ArrayList, começaram a tentar resolver os externs de Llama.cpp.
O GLM deu algum pau com o Crush. Chegou num determinado momento que ele não conseguia mais chamar a API e travou. E já estava demorando muito, então desisti dele. E quando eu digo demorar muito, estou realmente falando de mais de hora sem conseguir resolver.
O MiniMax também teve um processo de reasoning super prolixo, demorou mais de hora também, mas finalmente conseguiu compilar. Só que ao executar dava pau.
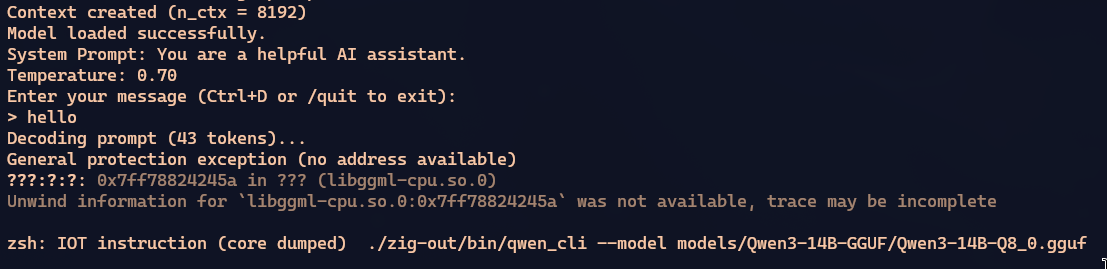
Insisti várias vezes pra ele corrigir esse erro, mas demorou muito e desisti de tentar.
DeepSeek tentei rodar o V2 Lite via LM Studio, mas não consegui integrar com o Crush. Muitas LLMs tem “capacidades” e uma que importa pra agentes é “tool”, que é a capacidade de fazer chamadas pra comandos e ferramentas como grep, bash, etc pro Crush rodar na máquina e ter feedback real.
Mas no caso do DeepSeek, seja rodando local ou seja conectando via OpenRouter, rapidamente eu vejo isso no Crush:
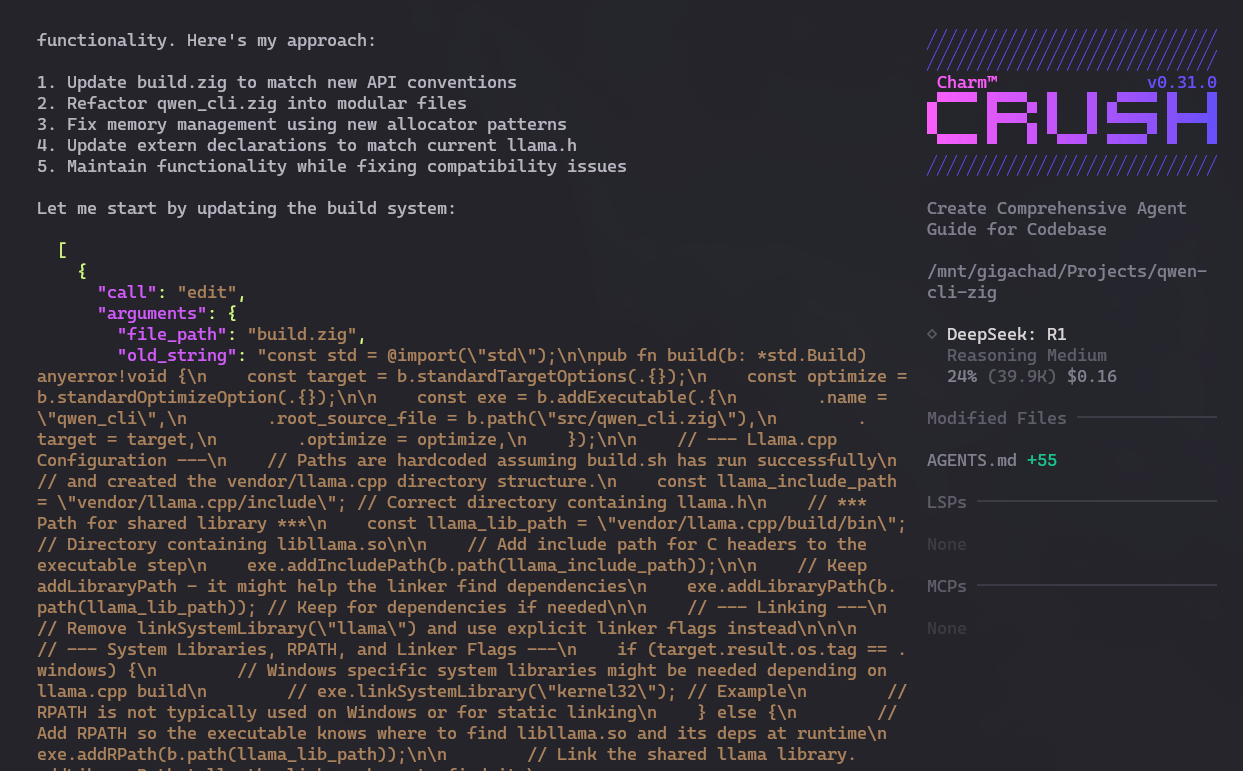
Aparece a tentativa de rodar comandos mas eu acho que esse não é o mesmo formato da OpenAI, que é o que todo mundo entende. Então o Crush não sabe o que fazer com isso e quebra o processo. Não tentei fuçar muito mais que isso.
LLMs comerciais
Nenhum modelo open source conseguiu fazer meu programa rodar. Mas pelo menos todas as comerciais conseguiram, e isso demonstra uma excelente evolução de um ano pra cá.
Como falei antes, o melhor no geral foi o Claude Opus. Todos os experimentos eu dava aquele prompt que mencionei no início do artigo. Mas nenhum conseguiu resolver até o fim. Sempre ou o build continuava com erro ou, mesmo buildando, tinha erro de runtime e dava crash.
O impressionante do Claude Opus é que foi o único que resolveu tudo em só DOIS PROMPTS!!!
Com aquele primeiro prompt porco que falei antes, resolveu os bugs de compatibilidade com o Zig 0.15, com o Llama.cpp, refatorou em múltiplos arquivos e o build gerava o binário. E isso em coisa de meia hora. Comparado com todos os outros que levaram mais de uma hora.
Daí eu tentei rodar o binário, mas dava crash logo no começo ao tentar carregar o modelo Qwen3. Eu fiz o segundo prompt e ele sozinho executou dentro do Crush, identificou o crash, e conseguiu consertar o bug. Daí eu já conseguia chegar até o chat e falar com o modelo. Foi muito rápido, eu nem acreditei!
Não estou dizendo que ele vai ser perfeito pra tudo, mas considerando tudo que falei até agora, foi praticamente instantâneo ter o resultado final.
Daí tentei o GPT 5 Codex - que chegou num próximo 2o lugar.
Foi pouca coisa mais lento que o Opus mas também chegou até um estado que quase compilava. Tive que insistir que ainda tinha erro no build, daí ele rodou de novo e corrigiu. E no caso, ele tinha um erro diferente. Depois de compilado eu executei e carregou o modelo e foi até o chat normalmente. Mas quando eu dava o comando “/quit” o programa crasheava na saída. Tinha problema de memory leak.
Precisei insistir com mais uns 2 ou 3 prompts, mas no final ele foi capaz de encontrar os leaks e corrigir. E agora o binário funciona igual ao do Opus.
Finalmente, tentei o Gemini 3 Pro Preview. Ano passado o melhor LLM comercial pra código era o Gemini 2.5, então eu tinha grandes expectativas. Mas ele me decepcionou um pouco. Foi de longe o mais demorado e o mais caro.
Eu nem falei de preços, mas o Opus resolveu tudo por uns USD 8. O GPT 5 Codex gastou por volta de USD 6, foi mais barato, mas demorou mais e precisou interagir mais. Já o Gemini 3 Pro gastou quase USD 14 e por pouco não conseguiu resolver!
O Gemini foi esquisito. Assim como MiniMax, o reasoning dele foi muito mais demorado que os demais. Eu estava começando a ficar preocupado porque parecia alguém com TDAH. Em vez de ir passo a passo, dava impressão que ele mexia mais do que precisava em várias partes nada a ver. Fez refactoring antes de corrigir bugs, ficou tentando reescrever coisas em vez de consertar. Por alguns momentos eu achei que ele fosse desistir.
Depois de demorar mais que o Opus ou o Codex, ele simplesmente desistiu!! Largou um “consegui consertar tudo”, mas eu tentei buildar e dava pau. Achei que fosse entrar no mesmo problema de agentic loop do Qwen3. Insisti dizendo que ainda estava quebrado e pelo menos rodou o build e começou a consertar o que faltava.
Assim como o Codex, conseguiu terminar o build, mas daí tinha crash em runtime também. Demorou um pouco pra corrigir mas no final consertou. Mas foi de longe o que me deu menos confiança no processo.
Pra comparar o que eles fizeram, eu deixei os Pull Requests abertos no projeto. Vejam vocês mesmos:
- PR do Opus - o melhor
- PR do GPT 5 Codex - chegou perto
- PR do GPT 5.2 - demorou mais mas resolveu bem
- PR do Gemini - deu medo, mas conseguiu
Ouvi falar que o GPT 5.2 Codex é o melhor, mas não tinha no OpenRouter pra testar, então eu testei o GPT 5.2. Ele não foi ajustado pra programação como o Codex, mas se saiu melhor que o Gemini 3, na minha opinião. Teve reasoning mais demorado que o 5.1 Codex, e também precisou de alguma insistência no final pra terminar, mas deu menos suspense que o Gemini.
Pelo menos nesse tipo de desafio, o Opus foi o vencedor disparado! Parece que ele é mais caro por token, mas faz menos reasoning e gasta menos contexto a toa, então no final os preços são comparáveis. Já o Gemini foi de longe o mais caro e menos confiável, dentre os comerciais.
Acabou a Carreira de Programador?
Sim, agente de IA - em particular conectado com Claude e GPT, melhoraram dramaticamente comparado com um ano atrás. Em conjunto com ferramentas de orquestração como Crush ou OpenCode, estão realmente muito bons de usar. Eu consigo me ver usando no dia-a-dia como um bom assistente de codificação.
Sim, eles “substituem júniors” como pessoal gosta de falar. Deixa eu explicar.
Desde que comecei meu canal no YouTube em 2018 eu vinha avisando que a Bolha de Programação ia estourar. Aquela demanda insana por programadores ruins não tinha futuro. Aquela coisa desenfreada de bootcamps e cursos online porcaria formando programadores medíocres não tinha como dar certo. Essa bolha estourou no fim de 2022.
E só pra pregar mesmo o caixão, ao mesmo tempo surgiu o primeiro GPT. Quatro anos depois, ainda não estamos nem perto do elusivo “AGI”. Mas o que temos hoje já é muito útil.
É muito simples: programador realmente tem que ser bom em 2026, pra ter uma boa carreira. Tudo que eu falei no meu canal - que acabou em 2023, antes de IAs -, continua valendo. Somente um bom programador consegue tirar vantagem dessas IAs.
Viram como a Tailwind perdeu 80% do seu faturamento por causa de IA? Tudo que tem a ver com formação “rápida” de “devs” implodiu. As promessas rasas não foram cumpridas, como eu avisei.
Pra mim é excelente: EU SEI EXATAMENTE O QUE EU QUERO e com isso consigo pedir pra IA e consigo checar se está correto. Alguém sem treinamento real em programação não consegue. As IAs continuam tendo o mesmo processo de sorteio de tokens com aleatoriedade embutida, É um processo estocástico e não-determinístico.
Portanto, um amador total ainda não vai conseguir fazer nada muito complicado. Você não sabe o que você não sabe.
Pra nós, seniors, várias tarefas trabalhosas e braçais - que antes pediríamos a estags ou júniors - realmente podem ser resolvidos via agentes de IA, seja com Cursor, Antigravity, OpenCode ou qualquer outro.
Se quiser ter uma carreira de verdade, as exigências mudaram, e aumentaram uma ordem de grandeza. Não é mais opcional fazer uma boa faculdade de verdade. Realmente aprender como as coisas funcionam por baixo. Pra conseguir saber o que pedir pras IAs e ter resultados decentes.
Como eu sempre disse, pra mim, essas ferramentas são super úteis e agora ficaram ainda melhores. Sua concorrência aumentou exponencialmente. Se prepare de verdade.
IAs como facilitadores
Pra não terminar negativo, tem vários usos pra essas ferramentas de IA. Em particular pra ajudar onboarding em novos projetos.
Deixa dar um exemplo bem bobo. Gosto muito de emuladores, sempre fico acompanhando. Em particular o projeto Xenia Canary que é a versão experimental em desenvolvimento do emulador de Xbox 360.
Eu não manjo nada de emuladores avançados como esse. E é bem difícil entrar nesse código sem saber nada. Mas com o Crush e o Opus, logo de cara ele já me dá um resumo do projeto. Veja este Gist que ele gerou em 5 minutos.
Depois de conseguir buildar e rodar testes - com a ajuda do Crush, fiz a seguinte pergunta:
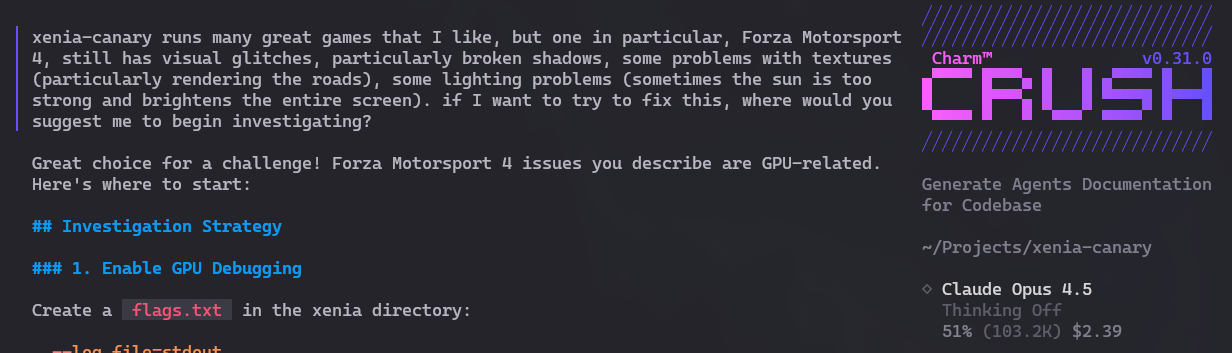
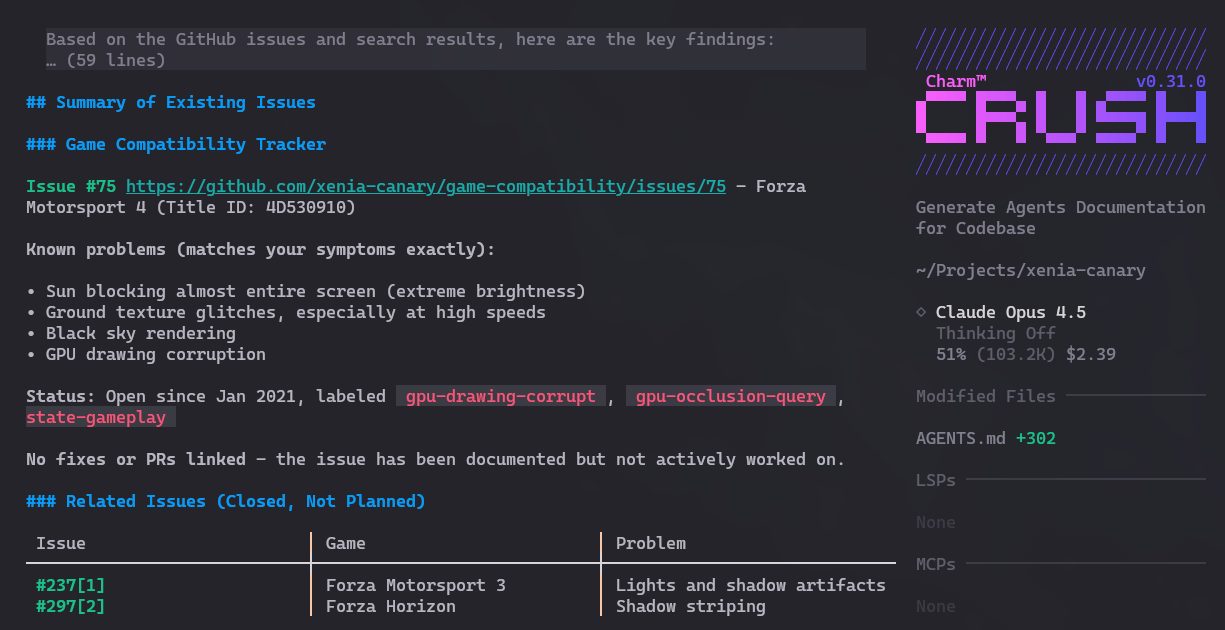
Eu gosto de Forza Motorsport 4 mas ele ainda tem vários glitches e bugs no emulador. Pedi pro Crush me dizer, se eu quiser explorar resolver esses bugs, onde eu poderia olhar primeiro. E ele analizou e deu várias boas sugestões:
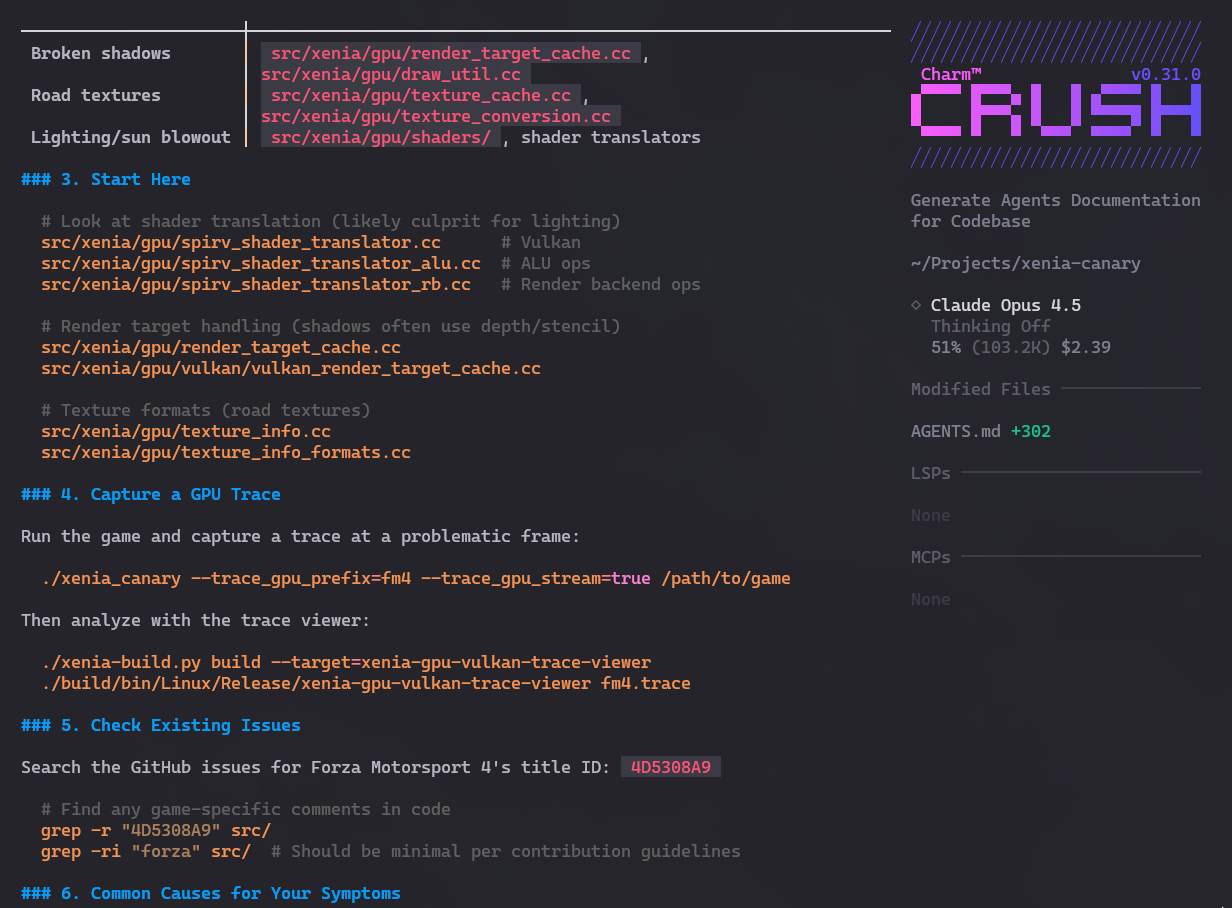
Depois pedi pra ele checar as Issues no GitHub e parece que não tem ninguém trabalhando nesses bugs em específico. Então são ótimos candidatos pra eu ou alguém tentar contribuir.
Honestamente, não sei ainda se vou entrar nesse buraco de coelho. Mas graças ao Crush, avaliar projetos que já existem e facilitar encontrar candidatos pra olhar primeiro, baixa muito a barreira de entrada! Não é pra ficar contribuindo “AI Slop”! Mas as possibilidades são muitas pra alguém como eu. Pensem nisso.