Meu Novo Blog - Como Eu Fiz
Este artigo está alguns meses atrasado, mas resolvi documentar agora porque senão vou esquecer como fiz. Como breve introdução, já digo o maior erro que todo programador que quer tentar começar a escrever comete: perde MUITO tempo tentando criar o blog perfeito. Just f…ng write!!
(e sim, tem tema dark, link no rodapé do site)
O BLOG PERFEITO NÃO EXISTE!
Eu acho importante que todo programador tente escrever. Não pra virar influencer nem nada disso. O primeiro objetivo é escrever pra você mesmo. Eu uso meu blog primariamente como um “backup” do meu cérebro (assim como foi meu canal do YouTube).
Notem como os últimos posts de Linux não sou eu tentando te vender nada, mas sim coisas que fiz de verdade no meu PC ou home server, e anoto passo a passo. Caso daqui 3 anos eu queira refazer, tenho tudo anotado.
Segundo: programadores são péssimos comunicadores. Nós falamos somente pra nós mesmos e não pensamos se a pessoa ouvindo está nos entendendo. E quando vemos que não entende a reação é “ah, porque ela é burra e eu sou inteligente.”
Falei sobre isso no artigo [Programadores são Péssimos Comunicadores](https://akitaonrails.com/2013/11/02/off-topic-programadores-sao-pessimos-comunicadores-udp-vs-tcp/. Mesmo se só uma pessoa ler seu post, mas te der um comentário, esse feedback é importante. É como um teste rodando que falha: agora você sabe onde tem que corrigir. E vai corrigindo, um passo de cada vez.
Portanto, escrever blog post, não importa se tem zero visitantes, é um exercício de prática pra se tornar um comunicador melhor, por isso recomendo.
Blog Engines
Eu comecei postando no Google Blogspot em 2006. Depois fiz meu próprio blog num projeto que já existia em Ruby on Rails 2.0, passei por vários, como o Typo3 na época. Até que em 2012 eu fiz o meu próprio engine do zero usando ActiveAdmin e é esse projeto que eu vim atualizando de Rails 3 até Rails 6 ou 7 recentemente. Meu primeiro post continua no blog:
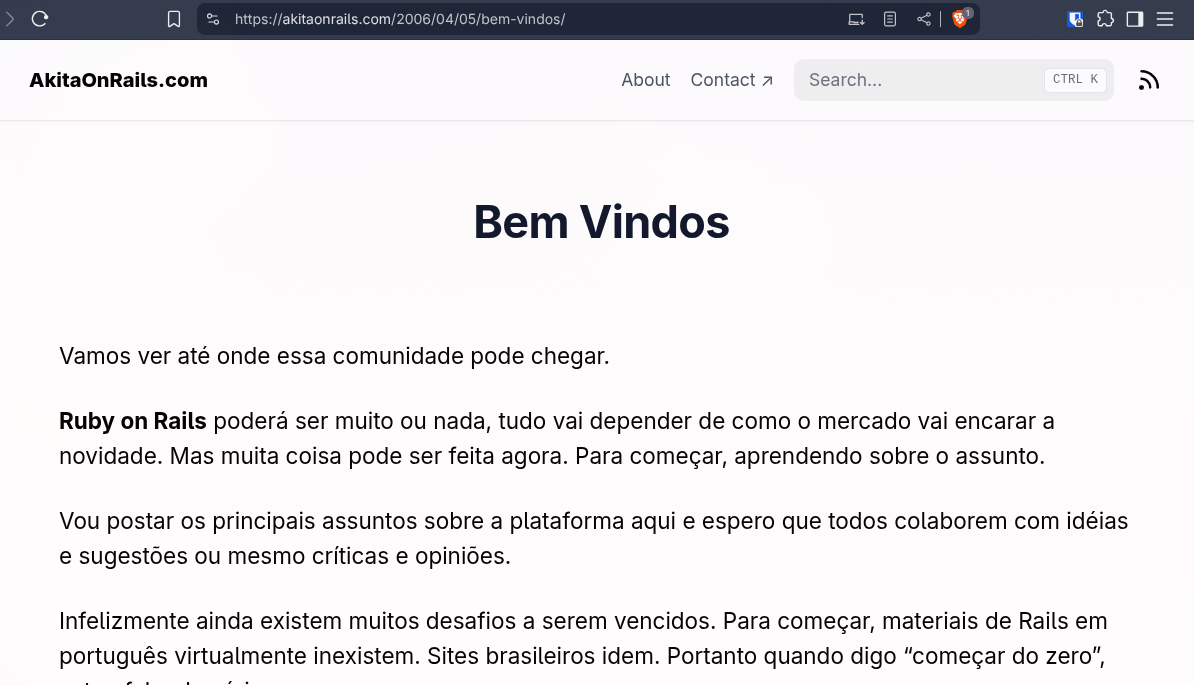
Muita coisa mudou nesse período, Less foi substituído por Sass. Textile e Liquid foram substituídos por Markdown, surgiu Twitter Bootstrap, etc. Por isso dezenas de artigos que escrevi estavam em Textile. E como sempre tive preguiça de converter em Markdown, demorei pra sair dessa minha engine velha.
Pra um blog pessoal, não precisa de nada complicado, como banco de dados ou coisas assim, mas acabou vindo como legado da época. Eu já conhecia jekyll pra fazer blogs com páginas estáticas, mas ainda tinha os posts velhos em Textile que tava com preguiça de lidar.
Ao longo do tempo também vim apagando vários posts. Coisas que ficaram obsoletas mesmo como “dicas pra Ruby 2.0” ou “novidades no Rails 3.0”. Ler isso hoje não faria sentido. Fui mantendo somente os posts que se ler hoje, ainda faz sentido. Isso veio a me ajudar quando resolvi converter os posts velhos.
Outro motivo de continuar no meu engine era que meu ActiveAdmin tinha o suporte pra fazer upload de imagens no meu bucket da AWS S3, então era uma conveniência extra que não tava com vontade de ter que resolver de outra forma.
Finalmente, em 2025, resolvi que estava de saco cheio de ficar atualizando versões de Rails, fazendo deploy no Heroku, lidar com backup de banco de dados, além do front-end estar feio e quebrado.
Hextra/Hugo
Depois de Jekyll, surgiram geradores de sites estáticos em dezenas de linguagens. De fato, é o jeito mais prático pra um programador escrever um blog: só criar um arquivo texto localmente, escrever tudo em markdown, rodar um script e subir um site estático que não precisa de nenhuma configuração, banco de dados ou qualquer outro componente mais complicado. Dá pra subir até como GitHub Pages e hospedar lá grátis.
Por isso eu sabia que, se fosse fazer um novo engine, teria que ser site estático. Já tinha ouvido falar do tal projeto Hugo, que é feito em Go e tem tudo que eu precisava: markdown, suporte a tags, etc. Mas tinha um problema: eu odeio fazer front-end e eu nunca fui um bom web designer, ou designer no geral.
Foi quando esbarrei no Hextra, que é basicamente o Hugo mas com vários temas pré-prontos. E diferente de vários outros projetos com temas gratuitos que costumam ser muito feios e muito mal feitos, os do Hextra me pareceram minimamente bem feitos. Fucei um pouco, achei um tema padrão minimalista que é legível pra textos com código e decidi que seria agora.
Desta vez não vou dar passo a passo de tudo que eu fiz porque seria maçante, mas é só ler a documentação do Hugo pra saber o que fazer. Na prática:
# novo projeto
hugo new
# reconstruir o site
hugo build
# subir o servidor local (porta 1313)
hugo server --buildDrafts --disableFastRenderNo meu caso, eu comecei com o Hextra Starter Template do que começar do Hugo zerado. Acho que vale a pena checar. Ele também explica como fazer deploy pra GitHub Pages e Netlify.
Código Aberto
A vantagem de usar um gerador de site estático é que posso me livrar do banco de dados Postgres que usei por anos e converter todos os artigos em arquivos texto individuais. Feito isso, basta subir tudo num repositório no GitHub. E como são textos publicamente disponíveis de qualquer forma, não tem porque não deixar aberto. Dessa forma, qualquer um pode contribuir (e muitos já contribuíram - obrigado pela ajuda!)
Se quiser contribuir ou só fuçar acesse o repositório no GitHub e faça um fork. Note como o nome do projeto é akitaonrails.github.io porque, originalmente, eu pretendia fazer deploy no GitHub Pages, mas mudei de idéia e já falo disso.
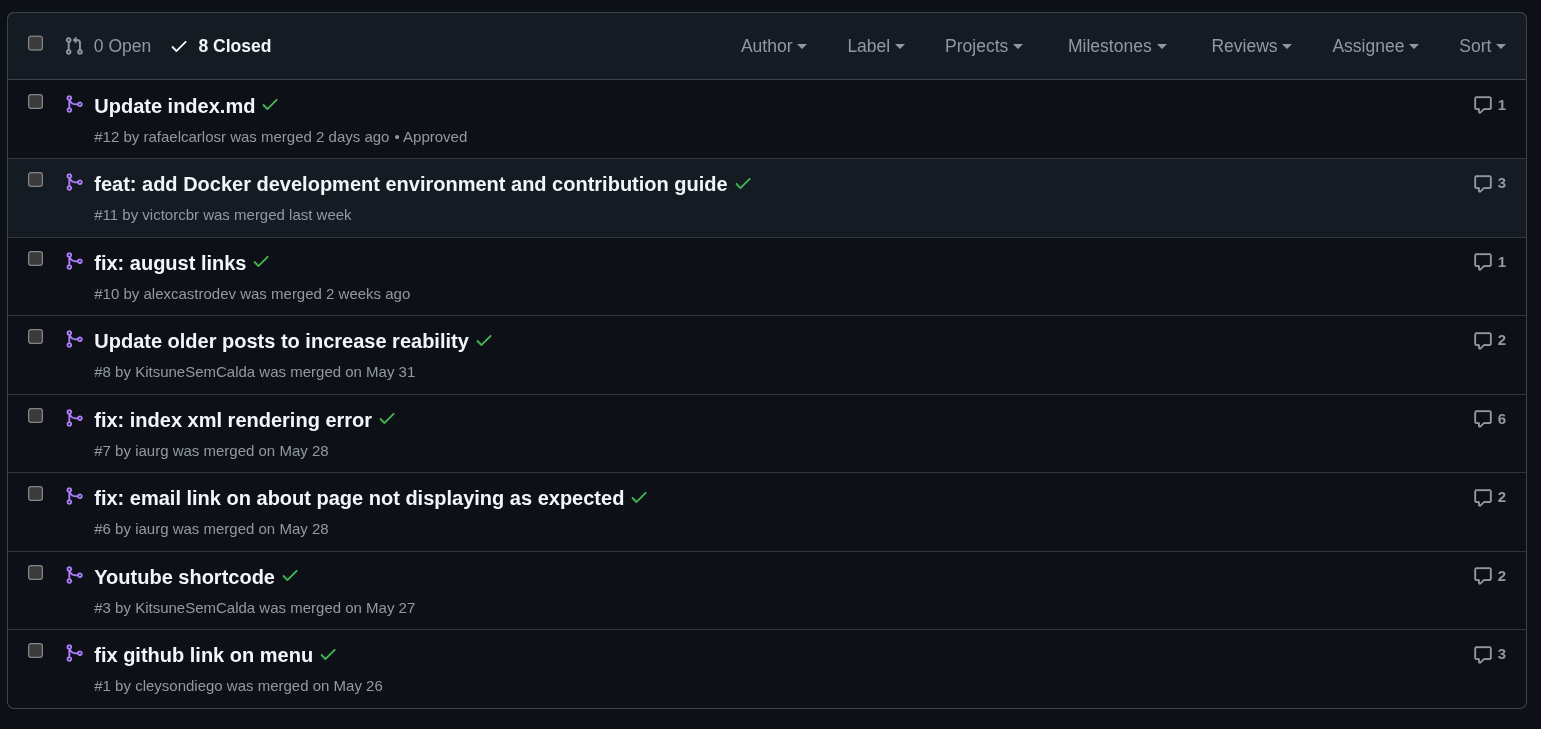
Até agora já tive 8 Pull Requests mergeadas. Alguns realmente se deram ao trabalho de caçar erros, typos, bugs e mandaram correções muito boas. O blog está melhor graças a eles. Às vezes eu posso demorar um pouco pra checar os PRs, mas eventualmente eu chego e costumo mergear tudo.
Um dos PRs inclusive foi pra adicionar suporte a Docker Compose pra facilitar pra quem quiser contribuir. Outro PR foi pra melhorar a documentação na página de README. Então tá bem fácil de entender o que fazer.
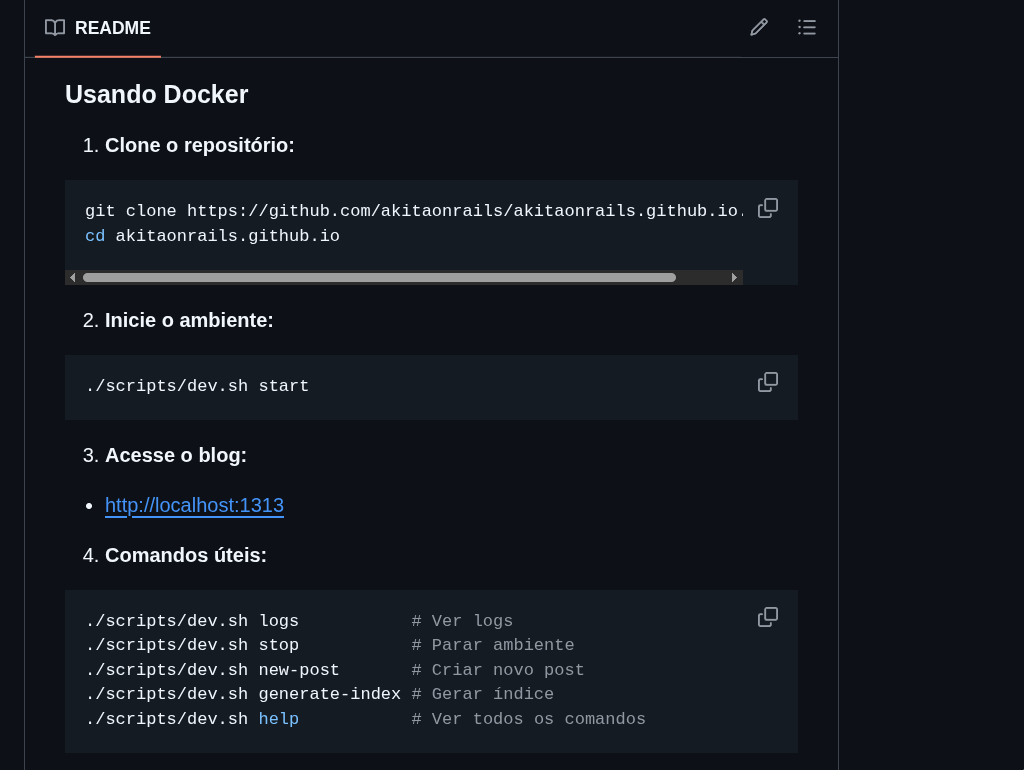
Eu particularmente não uso o workflow de Docker, logo abaixo tem o workflow pra instalação local. São tão poucos componentes que não acho que valha a pena lidar com Docker pra isso.
Digamos que eu queira escrever este artigo. Ele está salvo em content/09/10/meu-novo-blog-como-eu-fiz/index.md que significa mês 09 (setembro), dia 10, seguido do slug como sub-diretório e dentro só um index.md que é markdown. As primeiras linhas do artigo tem este cabeçalho:
---
title: Meu Novo Blog - Como Eu Fiz
date: "2025-09-10T15:00:00-03:00"
slug: meu-novo-blog-como-eu-fiz
tags:
- blog
- hugo
- hextra
- ruby
draft: false
---
....E segue o artigo escrito em Markdown. Feito isso, do diretório do projeto tenho que fazer:
cd content
ruby generate_index.rb
cd ..Isso atualiza a página principal com o link pro novo artigo no topo. Pra garantir que está tudo certo, posso checar subindo o servidor local:
❯ hugo server --buildDrafts --disableFastRender
Watching for changes in /home/akitaonrails/Projects/akitaonrails-hugo/{content,i18n,layouts}
Watching for config changes in /home/akitaonrails/Projects/akitaonrails-hugo/hugo.yaml, /home/akitaonrails/Projects/akitaonrails-hugo/go.mod
Start building sites …
hugo v0.149.1+extended+withdeploy linux/amd64 BuildDate=unknown
│ EN
──────────────────┼──────
Pages │ 3374
Paginator pages │ 0
Non-page files │ 131
Static files │ 11
Processed images │ 0
Aliases │ 0
Cleaned │ 0
Built in 8799 ms
Environment: "development"
Serving pages from disk
Web Server is available at http://localhost:1313/ (bind address 127.0.0.1)
Press Ctrl+C to stopAgora posso acessar no navegador em http://localhost:1313:

Finalmente, basta deployar:
git add .
git commit -m "adding new blog article"
git push origin masterE é só isso!
Deploy
Falei que pretendia fazer deploy no GitHub Pages, mas na última hora resolvi que queria fazer deploy na [Netlify]
Por que? Porque eu nunca tinha usado, então resolvi que queria ver como era. Basicamente isso. Eu achei barato, tem as funcionalidades que precisava, então, por que não?
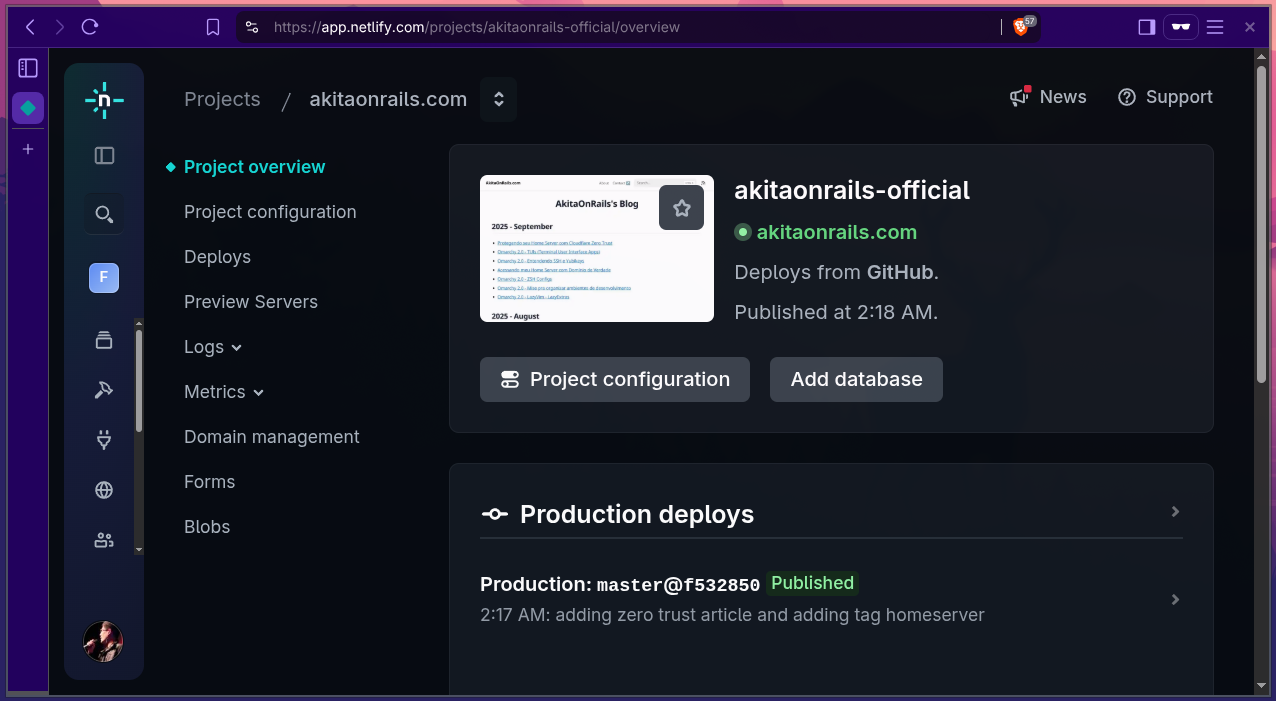
A única coisa que precisei fazer de diferente, foi configurar o deploy linkando com meu repositório do Github:
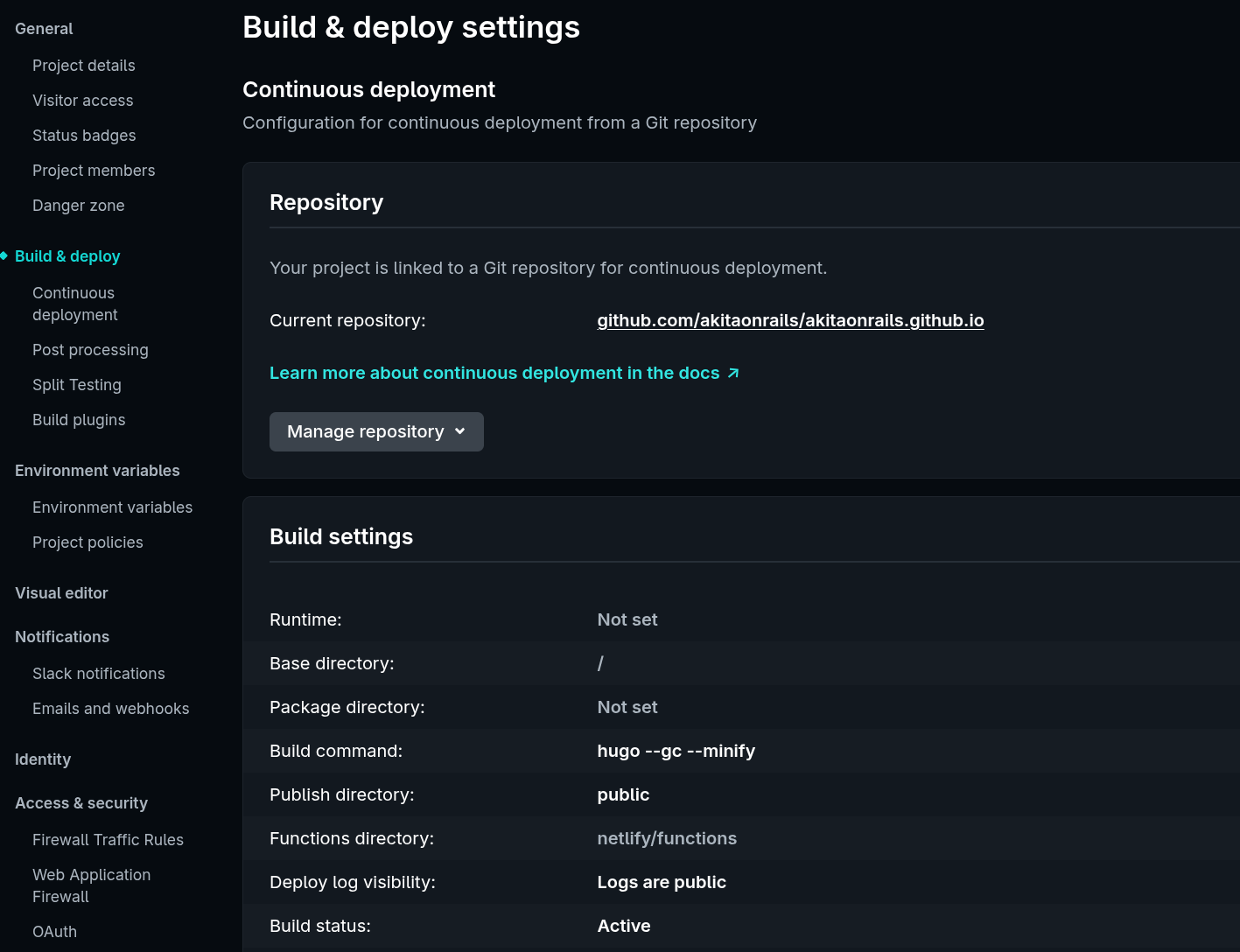
E, no GitHub, criar uma Action assim:
# Sample workflow for building and deploying a Hugo site to GitHub Pages
name: Deploy Hugo site to Pages
on:
# Runs on pushes targeting the default branch
push:
branches: ["master"]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# Sets permissions of the GITHUB_TOKEN to allow deployment to GitHub Pages
permissions:
contents: read
pages: write
id-token: write
# Allow only one concurrent deployment, skipping runs queued between the run in-progress and latest queued.
# However, do NOT cancel in-progress runs as we want to allow these production deployments to complete.
concurrency:
group: "pages"
cancel-in-progress: false
# Default to bash
defaults:
run:
shell: bash
jobs:
# Build job
build:
runs-on: ubuntu-latest
env:
HUGO_VERSION: 0.145.0
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0 # fetch all history for .GitInfo and .Lastmod
submodules: recursive
- name: Setup Go
uses: actions/setup-go@v5
with:
go-version: '1.24'
- name: Setup Pages
id: pages
uses: actions/configure-pages@v4
- name: Setup Hugo
run: |
wget -O ${{ runner.temp }}/hugo.deb https://github.com/gohugoio/hugo/releases/download/v${HUGO_VERSION}/hugo_extended_${HUGO_VERSION}_linux-amd64.deb \
&& sudo dpkg -i ${{ runner.temp }}/hugo.deb
- name: Build with Hugo
env:
# For maximum backward compatibility with Hugo modules
HUGO_ENVIRONMENT: production
HUGO_ENV: production
run: |
hugo \
--gc --minify \
--baseURL "https://${{ github.repository_owner }}.github.io/"
- name: Upload artifact
uses: actions/upload-pages-artifact@v3
with:
path: ./public
# Deployment job
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
needs: build
steps:
- name: Deploy to GitHub Pages
id: deployment
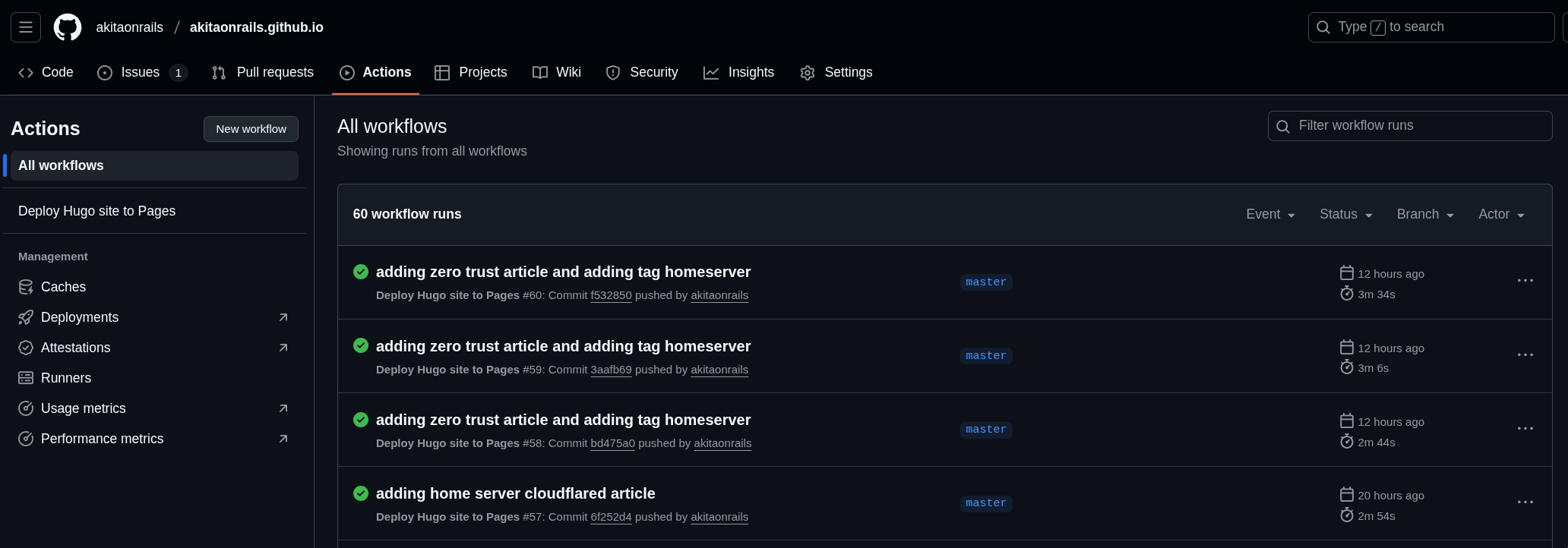
uses: actions/deploy-pages@v4Com isso, toda vez que faço git push, vai rodar esse job, gerar o site e mandar pro Netlify direto. Tudo automatizado, como Deus sempre quis 🤣:
Aliás, eu falei que o Netlify era “barato”, na verdade eu quis dizer que é gratuito. Pra sites pequenos como o meu, não custa literalmente nada:
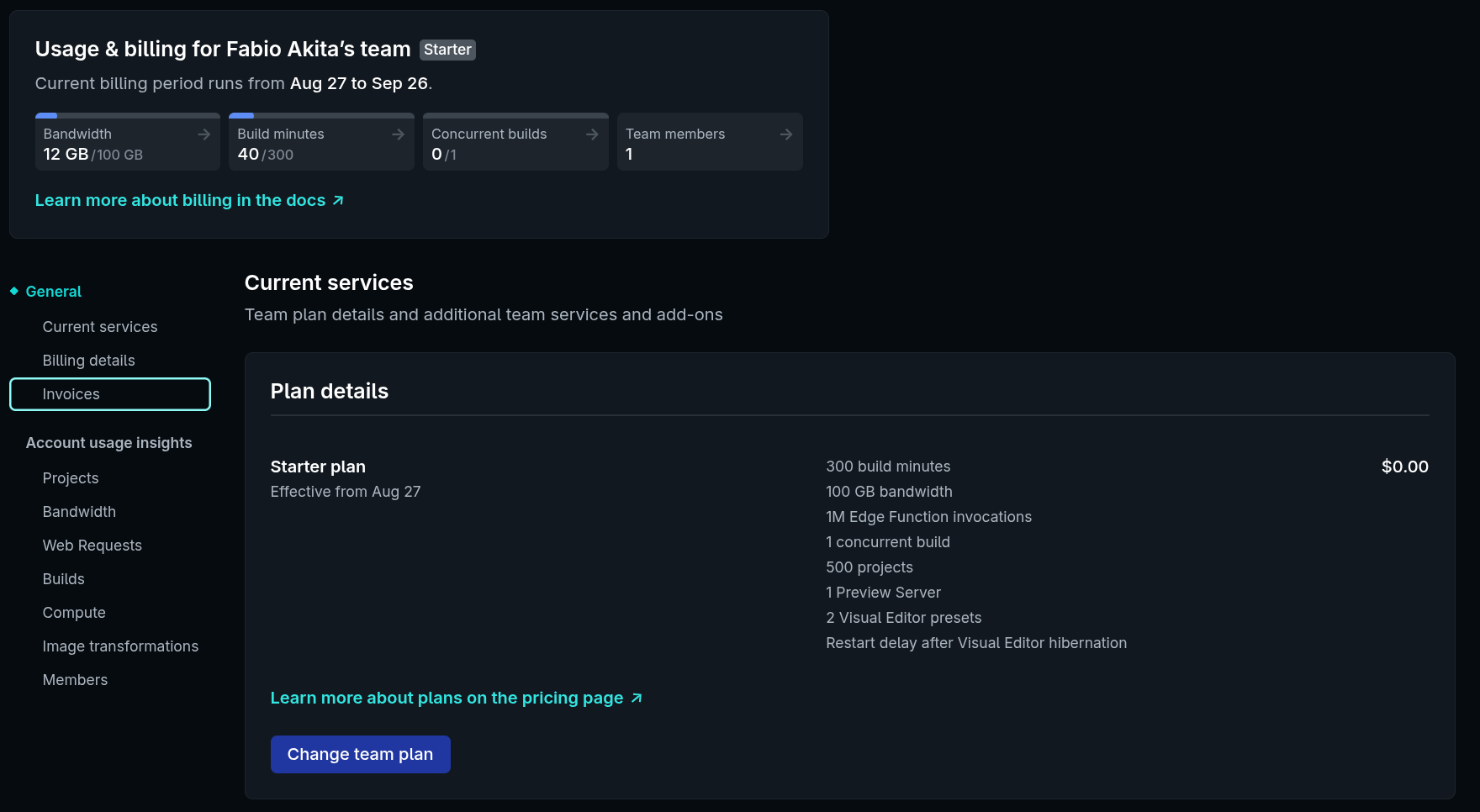
Pago zero dólares e ainda aprendi algo novo. Por isso essas coisas são divertidas.
Scripts
Pra converter os artigos do meu blog antigo pro Hugo, acabei fazendo alguns scripts de correção. Eles ainda estão no repositório como content/fix_*.rb. Não precisa saber pra que eles servem, mas estão lá caso queiram fuçar. O mais importante era manter as URIs iguais eram no blog anterior pro Google continuar achando corretamente.
O único que reamente interessa é o generate_index.rb:
require 'yaml'
require 'find'
require 'date'
def escape_markdown(text)
text.to_s.gsub('[', '\\[').gsub(']', '\\]')
end
entries = []
Find.find('.') do |path|
next unless path.end_with?('index.md')
next if path == './index.md' || path == './_index.md'
begin
lines = File.readlines(path)
if lines.first&.strip == '---'
fm_lines = []
i = 1
while i < lines.size && lines[i].strip != '---'
fm_lines << lines[i]
i += 1
end
if lines[i]&.strip == '---'
front = YAML.safe_load(fm_lines.join)
if front && front['title'] && front['date']
date = Date.parse(front['date'].to_s) rescue nil
if date
url = path.sub('./', '').sub('/index.md', '/')
entries << { 'title' => front['title'], 'url' => url, 'date' => date }
end
end
end
end
rescue => e
warn "YAML error in #{path}: #{e.message}"
end
end
# Sort newest first
entries.sort_by! { |e| e['date'] }.reverse!
# Group by year and month
grouped = entries.group_by { |e| [e['date'].year, e['date'].month] }
# Sort year-month pairs descending
sorted_keys = grouped.keys.sort.reverse
File.open('_index.md', 'w') do |f|
f.puts "---"
f.puts "title: AkitaOnRails's Blog"
f.puts "---"
f.puts
sorted_keys.each do |(year, month)|
month_name = Date::MONTHNAMES[month] # "May", "June", etc
f.puts "## #{year} - #{month_name}\n\n"
grouped[[year, month]].each do |post|
f.puts "- [#{escape_markdown(post['title'])}](#{post['url']})"
end
f.puts
end
end
puts "Generated _index.md with posts grouped by year & month."Esse script tem um pequeno bug: ele ordena os artigos a partir do diretório de mês e dia, mas significa que se eu postar várias vezes durante o dia, vai sair fora de ordem, ordenado pelo título do artigo. Veja: sorted_keys.each do |(year, month)|
O certo seria abrir o artigo e pegar o metadado de timestamp, mas fiquei com preguiça. Se alguém quiser corrigir e mandar um PR, será bem vindo.
Por que fiz em Ruby e não em Python ou Bash?? Porque foi como eu quis 🤣, não perturba.
Imagens no S3
Como contei antes, uma das conveniências do meu antigo engine feito em Rails, é que eu tinha feito o ActiveAdmin com suporte a fazer uploads pro meu bucket de S3. E era um setup complicado porque ainda adicionava AWS CloudFront na frente pra fazer cache dessas imagens em CDN e tudo mais.
Mas meu site é ultra-pequeno, não precisa da complexidade de CloudFront, então tirei e agora faço links direto pro bucket, por exemplo: https://new-uploads-akitaonrails.s3.us-east-2.amazonaws.com/screenshot-2025-09-10_00-35-57.png
Significa que meu workflow consiste em tirar screenshots, depois abrir o site de console do meu AWS, e manualmente fazer upload no bucket, via interface web, copiar o link gerado e colar no Markdown do artigo. Não é complicado, mas é um BEM chatinho.
Cheguei a fazer um script besta usando aws-cli mas isso exigia manter um terminal aberto no diretório de screenshots e, manualmente fazer algo como upload-s3 screenshot-2025-09-10_00-35-57.png, o que não é exatamente conveniente também. Aliás, se não sabia disso, você pode automatizar muita coisa da AWS só usando essa ferramenta.
Enquanto estava pensando em escrever este artigo, resolvi consertar esse problema de uma vez. Como sabem, estou usando Omarchy, e o File Explorer padrão dele é o bom e velho Nautilus do GNOME. Gosto dele, parece muito com o Finder de MacOS. Gosto mais dele do que um Dolphin ou Thunar, que parecem mais com o Windows Explorer. E eu nunca gostei de Windows Explorer.
“E se eu pudesse só clicar com o botão direito do mouse em cima do arquivo de screenshot e selecionar ’enviar pro s3’ no menu de contexto e já ganhar a URL copiada no meu clipboard? 🤔”
Que tal assim?
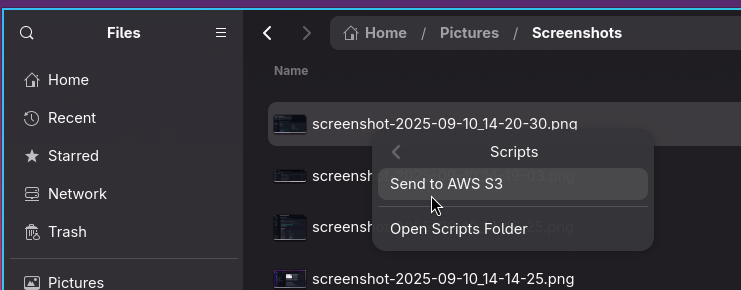
Nautilus suporta scripts de usuário, então fiz o seguinte:
mkdir -p ~/.local/share/nautilus/scripts
nvim ~/.local/share/nautilus/scripts/Send\ to\ AWS\ S3E eis o script:
#!/usr/bin/env bash
#set -euo pipefail
# ---------- config ----------
BUCKET="new-uploads-akitaonrails" # name only
PREFIX="" # e.g., "uploads/"
AWS_PROFILE="${AWS_PROFILE:-default}"
# URL_MODE: presign | public | cloudfront
URL_MODE="public"
PRESIGN_TTL=604800
CLOUDFRONT_DOMAIN=""
MAKE_PUBLIC_ACL=false # keep false unless your bucket denies public reads
# ----------------------------
require() { command -v "$1" >/dev/null 2>&1; }
# clipboard: wl-copy > xclip > none
CLIP_CMD=""
if require wl-copy; then
CLIP_CMD="wl-copy"
elif require xclip; then
CLIP_CMD="xclip -selection clipboard"
fi
region() {
local r
r="$(aws --profile "$AWS_PROFILE" s3api get-bucket-location --bucket "$BUCKET" \
--query 'LocationConstraint' --output text 2>/dev/null || echo "None")"
[[ "$r" == "None" || "$r" == "null" ]] && echo "us-east-1" || echo "$r"
}
public_url() {
local key="$1" r="$2"
if [[ -n "$CLOUDFRONT_DOMAIN" && "$URL_MODE" == "cloudfront" ]]; then
printf 'https://%s/%s\n' "$CLOUDFRONT_DOMAIN" "$key"
else
if [[ "$r" == "us-east-1" ]]; then
printf 'https://%s.s3.amazonaws.com/%s\n' "$BUCKET" "$key"
else
printf 'https://%s.s3.%s.amazonaws.com/%s\n' "$BUCKET" "$r" "$key"
fi
fi
}
presign_url() {
local key="$1"
aws --profile "$AWS_PROFILE" s3 presign "s3://$BUCKET/$key" --expires-in "$PRESIGN_TTL"
}
upload_one() {
local src="$1" key="$2" args=(--only-show-errors --follow-symlinks)
if [[ "$URL_MODE" == "public" && "$MAKE_PUBLIC_ACL" == "true" ]]; then
args+=(--acl public-read)
fi
aws --profile "$AWS_PROFILE" s3 cp "${args[@]}" "$src" "s3://$BUCKET/$key"
}
# allow running from terminal with paths as args
if [[ $# -gt 0 ]]; then
NAUTILUS_SCRIPT_SELECTED_FILE_PATHS="$(printf '%s\n' "$@")"
fi
SEL="${NAUTILUS_SCRIPT_SELECTED_FILE_PATHS:-}"
[[ -n "$SEL" ]] || {
notify-send "S3 upload" "No selection"
exit 0
}
R="$(region)"
urls=()
ok=0
fail=0
errs=()
while IFS= read -r path; do
[[ -e "$path" ]] || {
errs+=("Missing: $path")
((fail++))
continue
}
if [[ -d "$path" ]]; then
base="$(basename "$path")"
while IFS= read -r -d '' f; do
rel="${f#"$path"/}"
key="${PREFIX}${base}/${rel}"
if upload_one "$f" "$key"; then
case "$URL_MODE" in
presign) urls+=("$(presign_url "$key")") ;;
public | cloudfront) urls+=("$(public_url "$key" "$R")") ;;
esac
((ok++))
else
errs+=("Failed: $f")
((fail++))
fi
done < <(find "$path" -type f -print0)
else
ts="$(date +%Y%m%d%H%M%S)"
filename="$(basename "$path")"
key="${PREFIX}${ts}_${filename}"
if upload_one "$path" "$key"; then
case "$URL_MODE" in
presign) urls+=("$(presign_url "$key")") ;;
public | cloudfront) urls+=("$(public_url "$key" "$R")") ;;
esac
((ok++))
else
errs+=("Failed: $path")
((fail++))
fi
fi
done <<<"$SEL"
out="$(printf '%s\n' "${urls[@]}")"
# --- relax only for UX bits ---
set +e
if [[ -n "$out" ]]; then
printf '%s' "$out" | wl-copy -n || true # or xclip fallback
fi
if command -v notify-send >/dev/null 2>&1; then
if ((fail == 0)); then
notify-send "S3 upload: ${ok} ok" "$(printf '%s\n' "${urls[@]:0:5}")" || true
else
notify-send -u critical "S3 upload: ${ok} ok, ${fail} failed" \
"$(printf '%s\n' "${errs[@]}" | head -n 10)" || true
fi
fi
set -e
# --- end relax ---
printf '%s\n' "$out"
((fail == 0)) || exit 1Obviamente troque o BUCKET pelo seu bucket. Se tiver múltiplos buckets, depois reorganize esse script e faça source em múltiplos scripts como Send To Bucket XYZ e Send to Bucket ABC ou algo assim no diretório de nautilus/scripts.
Se quiser testar do terminal, só fazer assim:
# single file
NAUTILUS_SCRIPT_SELECTED_FILE_PATHS="$(printf '%s\n' '/full/path/to/image.png')" \
bash -x ~/.local/share/nautilus/scripts/Send\ to\ AWS\ S3Notem que comentei o set -e do Bash porque ou o wl-copy ou o notify-send está retornando algum warning ou erro e isso está quebrando o script. Sem isso, termina corretamente e copia a URL do upload no clipboard. Daí posso colar direto no editor de textos.
Bônus: Screenshots em Omarchy
Inclusive, dica bônus de Omarchy: do nada o script de screenshot começou a falhar pra mim. Vamos consertar.
Primeiro, eu queria que os screenshots fossem pro diretório Pictures/Screenshots, segundo, depois de uma atualização, sei lá porque o comando hyprshot parou de funcionar com o satty. Sem paciência durante a madrugada eu editei o script de screenshot do Omarchy, que fica em ~/.local/share/omarchy/bin/omarchy-cmd-screenshot (fucem lá), e substituí por isto:
#!/bin/bash
set -euo pipefail
[[ -f ~/.config/user-dirs.dirs ]] && source ~/.config/user-dirs.dirs
OUT="${OMARCHY_SCREENSHOT_DIR:-${XDG_PICTURES_DIR:-$HOME/Pictures}}/Screenshots"
mkdir -p "$OUT"
satty --filename - \
--output-filename "$OUT/screenshot-$(date +'%Y-%m-%d_%H-%M-%S').png" \
--early-exit \
--actions-on-enter save-to-clipboard \
--save-after-copy \
--copy-command 'wl-copy' \
< <(slurp | grim -g - -)Na prática, troquei o hyprshot pelo grim, que permite capturar foto de tela de Wayland (cuidado que tem várias ferramentas que só funcionam em X11, Omarchy é Hyprland, portanto, Wayland).
Além disso o Omarchy não tem opção pra tirar foto de tela com timer. Isso é útil quando quero tirar foto de um menu aberto com ítem selecionado. Se usar o jeito normal com tecla Print-Screen ou usando o menu do Omarchy, o menu que eu tinha aberto pode fechar antes de conseguir a foto de tela. A solução é um timer.
E com grim é fácil, via linha de comando mesmo posso fazer:
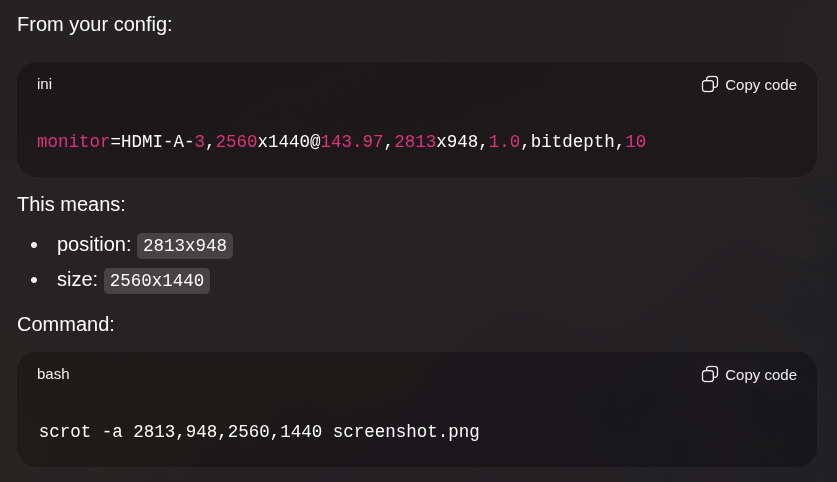
sleep 10 && grim -g "2813,948 2560x1440" ~/Pictures/Screenshots/image-01.pngEm Wayland, dois monitores são como se fossem uma única tela gigante, então precisa dar a geometria correta de onde quero tirar a foto. ChatGPT ajuda pra isso se passar o seu .config/hypr/monitors.conf pra ele.
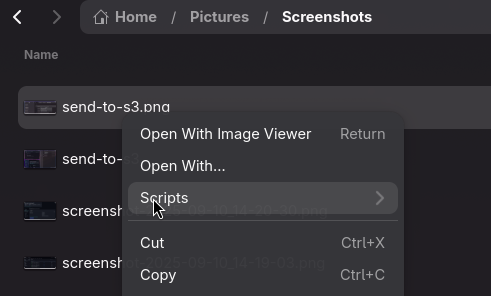
Agora tenho uma forma simples de tirar fotos de tela e enviar direto pro S3, direto do Nautilus, e conseguindo tirar uma foto de tela como esta:
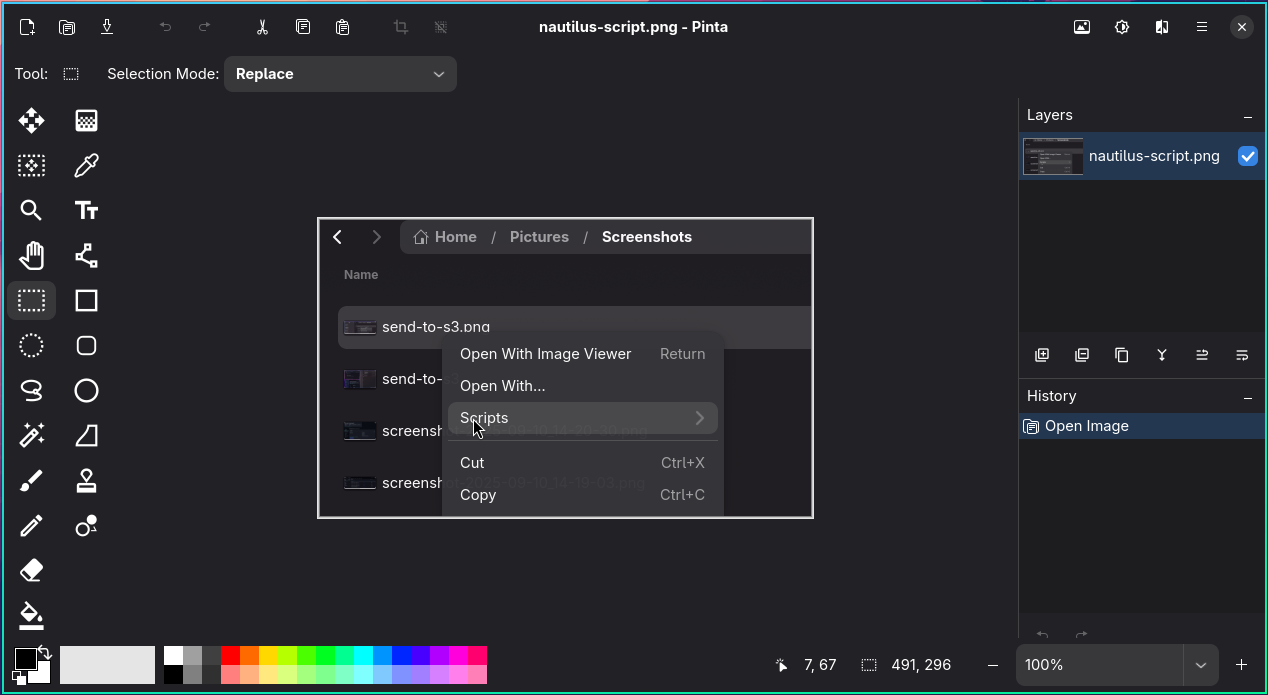
E o programa que eu uso, pra fazer coisas simples como um crop de alguma foto de tela, é o Pinta
Conclusão
Isso é o que lembrei de importante sobre meu novo blog. Acho que ficou muito mais simples de dar manutenção e, mais importante, muito mais simples de escrever artigos: só abrir um editor de textos e pronto. Nenhum deploy mais complicado, tudo automatizado, tudo integrado com meu Omarchy.
Meu blog já tem mais de 20 anos e durante esse tempo eu migrei de engine de blog várias vezes, uma meia dúzia de vezes. Por isso é um esforço inútil achar que você vai acertar logo de primeira e gastar semanas ou meses tentando fazer o engine ideal: você vai fracassar.
No final, a única coisa que interessa é O CONTEÚDO. O exercício de escrever, de escrever o mínimo possível pra comunicar o máximo de informação relevante, de escrever uma história que engaja do começo ao fim, de não virar formato de TCC ou página de Wiki de documentação. Escrever uma documentação é diferente de escrever um post de blog.
É mais importante escrever de uma forma que você mesmo goste de ler depois do que em qualquer linguagem vai fazer sua engine.