Usando I.A (ComfyUI) pra gerar NPCs em desenvolvimento de games
Eu andei atualizando BASTANTE meu projetinho de Comfyui com Docker Compose. Eu acho que é o setup mais completo e testado de todos, com a vantagem de ser em Docker, então é repetitível com zero setup. Leia meu post pra mais detalhes sobre como ele funciona.
Resolvi documentar neste post sobre um dos workflow mais complexos que eu testei que funciona nesse meu setup: como desenvolver Character Sheets de personagens aleatórios, em qualquer estilo, seja realista, seja estilo pixar, seja estilo cartoon, o que você quiser. O resultado é um sheet como no exemplo abaixo. Em várias poses, várias iluminações, várias expressões de emoção, com índice de cor, tudo gerado do absoluto zero pela “I.A.”. Em meia hora de processamento na minha RTX 4090.

Imagine que você é estag em estúdio de jogos. Seu trabalho: criar 100 personagens de fundo (NPCs). No fim tem que gerar 100 desses. Mas só porque é personagem secundário, não pode fazer de qualquer jeito, tem que ser todos coerentes, em todas as poses. Imagina quantos dias você iria levar. E se desse pra automatizar? É pra esse tipo de cenário que I.A. é interessante. Gaste mais tempo nos personagens principais, faça manualmente, mas não perca tempo nos secundários e não baixe a qualidade final de tudo.
Eu não fiz esse workflow, quem fez foi o Mickmumpitz. Assista o video inteiro dele pra saber como funciona esse workflow, não vou repetir o que ele já explica:
Também não vou compartilhar o workflow dele, porque ele tem um Patreon pago (é super barato, só USD 10 por mês), que te dá acesso a baixar o pacote de workflow inteiro dele neste link
Mas só isso não adianta, os requerimentos que você precisa:
- uma máquina parruda com pelo menos uma RTX 3090 com 24GB de VRAM. Importante aqui é VRAM, os modelos usados fácil ultrapassam uso de 20GB. CPU é menos importante, eu uso uma 7950X3D mas uma 7800 já daria conta.

- caso não tenha máquina assim, dá mais trabalho mas você pode alugar uma na RUNPOD. Eles tem várias configurações de GPU, mas você vai precisar saber configurar um pouco Linux ou escolher Windows e fazer o tutorial do Mickmumptiz tudo na mão (vai por mim, você vai sofrer se fizer assim).
- precisa ter pelo menos 500GB de espaço disponível e internet boa pra baixar. Na primeira vez que meu Docker rodar, ele baixa automaticamente todas as extensions de ComfyUI e todos os modelos pra tudo. Dá pra editar o arquivo
models.confantes e remover modelos que sabe que nunca vai usar. Mas só este workflow exige pelo menos uns 30GB de modelos, não tem como fugir disso. - esse workflow é particularmente PESADO porque são várias funcionalidades (que podemos desligar partes, pra customizar pro nosso fluxo de trabalho). Mas pra 1 personagem, o fluxo inteiro pode levar 30 MINUTOS. Mesmo numa RTX 4090 como a minha.
Se fez tudo certo até este ponto, tem ComfyUI rodando com todas as dependências já baixadas e comprou o Workflow. Quando carregar vai ter que consertar algumas coisas manualmente.
Primeira coisa é que vai ver um erro em vários Nodes em vermelho, todos de Ultimate SD Upscale, basta clicar com o botão direito do mouse em cada um e escolher “Fix Recreate” que vai consertar automaticamente:

O ComfyUI exige que cada slot de output de um Node se ligue no slot de input de outro Node compatível, mas frequentemente os workflow ficam tão grandes que tem fiozinho conectando coisa espalhado pra tudo que é canto e fica bem difícil de saber o que liga no que. Literalmente fica macarrônico.
Mas existe uma extension (que eu já deixei pré-instalado) chamado cg-use-everywhere. Toda extension é um projetinho do GitHub, clonado no sub-diretório custom_nodes. Ele permite conectar a saída de Node nesse node Anything Elsewhere, digamos a saída “clip” do Node “Load Clip”. Agora, todo outro Node que tiver como input o campo “clip” e não tiver nada conectando explicitamente nele, vai usar esse Anything que foi criado. Funciona super bem.
Só nesse workflow do Mick que, sei lá porque, todos os Anywheres estão quebrados. Mas é fácil consertar. Basta procurar esses Nodes, apagar, criar novos e reconectar. Tem vários logo no começo, anote quem liga em cada um, apague e crie um novo pra reconectar:

Tem também alguns no grupo 02 de Upscale:

Nodes pequenos, só com o título, estão COLAPSADOS. Só clicar com o botão direito e escolher EXPAND pra ver os detalhes. É outra forma de organizar a bagunça.
Por último, tem que rechecar o nome correto dos modelos em todos os Nodes de “Load” alguma coisa logo no começo do workflow (ainda bem que ele organizou esses nodes tudo junto):

No workflow dele, o Node vem procurando por “FLUX/flux1-dev-fp8.safetensors” mas aí você vai na lista (que puxa o que está mesmo no diretório “models/checkpoints” na sua máquina) e escolhe o que tem o mesmo nome. Isso acontece frequentemente porque diferentes pessoas organizam sub-diretórios diferentes pros modelos. Mas depois de configurar é só salvar e pronto. Tem que fazer isso pro checkpoint, controlnet, ic-light, etc.
Os erros do ComfyUI não são amigáveis. São stacktraces de Python, que não são amigáveis porque ele mostra que linha do código deu pau, mas não mostra o que tinha nas variáveis passadas pra função que deu pau. Daí não dá pra saber onde foi. Mas normalmente na interface web, o Node fica em vermelho, daí você checa e normalmente é porque esqueceu de baixar o modelo ou escolher o certo da lista.
Última coisa nesse workflow é baixar a image de OpenPose da página de Patreon dele, que linkei no começo do post, e carregar:

OpenPose é um formato de arquivo padrão que descreve poses, formato aberto que pode ser editar em várias ferramentas. E tem diversos modelos pré-treinados pra extrair poses nesse formato a partir de imagens, então nem precisamos editar na mão. Podemos baixar várias poses pré-prontas e abertas neste site:


Na primeira parte, tem a configuração e checagem manual dos modelos. Só tem que arrumar uma vez e salvar. Depois sempre vai funcionar igual. Nesse primeiro menu também dá pra ligar e desligar alguns dos grupos de Nodes, por exemplo, pra pular a primeira etapa de gerar personagem do zero e poder usar suas próprias fotos:

Se optar por gerar personagem do zero, tem em verde uma caixa de prompt pra digitar como quer que seja sua personagem, em que estilo. Prompts de Texto são decodificados por modelos de CLIP (Contrastive Language Image Pre-Training), que são específicos pra determinadas categorias de UNETs (como SDXL pra Stable Diffusion ou o melhor e mais popular FLUX agora). Parte do aprendizado é começar a aprender quais sub-modelos (clips, clip_vision, vaes, loras, etc) são compatíveis com quais unets (unet, checkpoints, diffusion_models). Não pode misturar qualquer coisa. Grosseiramente, é meio que se você escolhe fazer um texto em alemão, todos os plugins tem que ser em alemão.

Não vou mostrar o workflow completo porque nem cabe, mas dá pra ver em verde os prompts, no meio onde escolhemos que pode queremos (tá no Patreon dele), e em cima a image gerada pelo modelo flux1-dev-fp8, um dos melhores e mais populares por ter excelente qualidade e não ser tão pesado (fp8 em vez de fp32, por exemplo).
Isso é uma das vantagens de usar ferramentas fora dos Dalle ou Midjourney da vida: podemos controlar todos os aspectos da geração da imagem não só com prompts de texto, mas com prompts de imagens, como o OpenPose.
Outro detalhe. Expliquei no meu post anterior sobre KSampler ou Samplers em geral, que são o motor que faz todo o trabalho de juntar todos os modelos, imagens, prompts, controlnet, vaes e produz a imagem final. Os parâmetros do KSampler como steps, cfg, denoise, scheduler e mais DEPENDEM do modelo escolhido. Tem modelos bem documentados, tem modelos mal documentados.
Por exemplo, digamos que você leu numa thread de Reddit sobre esse outro modelo mais otimizado chamado “TurboVisionXL”, que está disponível no site Civit.ai:

Realmente é um bom modelo mas e agora? O que eu configuro no KSampler pra ele? Felizmente se scrolar a página (sempre leia a documentação original!!) vai encontrar estas recomendações:

Viu só? Ele explica o que configurar e quais são limitações conhecidas. Mais embaixo vai ter comentários de outras pessoas que podem dar mais dicas ou compartilhar erros que você já tenha visto. É uma enorme comunidade, precisa aprender a participar dela.

Mas voltando da tangente, no segundo grupo de nodes do Mick, ele pega a primeira imagem em “Pose T” e passa por um processo de “Multi View” usando Diffuser MV que faz isso automaticamente. É a mesma pose, mas como se a câmera desse um 360 graus ao redor dela, pegando ângulos diferentes e, principalmente, gerando novas imagens coerentes com a original (veja como o modelo é usado até pra inventar as costas da personagem).
Nesse passo também ele extrai só o rosto da primeira imagem pra fazer outros tratamentos em paralelo. Reconhecimento e extração de rostos é super comum. Todo sistema de segurança usa, Google Photos usa pra organizar álbuns dinâmicos. E vale você aprender pra usar em seus produtos. É um processo razoavelmente leve e rápido hoje em dia e tem vários algoritmos e modelos pré-prontos pra usar. Nesse caso acho que nem usa I.A. propriamente dito, é um algoritmo mesmo.
Outro detalhe: modelos de geração de imagens normalmente trabalham em BAIXA RESOLUÇÃO. Normalmente abaixo de 1024x1024. Não espere gerar imagens 4K logo de cara. Mas não tem problema, porque a solução é primeiro gerar uma image de baixa resolução e depois passar por outro modelo de I.A. especializado em UPSCALING como o RealESRGAN que já falei no meu outro post sobre upscaling de anime
Diferente do que faz um Photoshop ou qualquer editor de imagens, se tentar aumentar uma imagem, ele só vai pegar um pixel e tentar duplicar, quadruplicar os pixels ao redor. Mas isso costuma só deixar a imagem maior mas borrada (blurred), porque ele não tem como saber os detalhes, e nem vai tentar “inventar” detalhes.
Pra “inventar” detalhes, precisa de um modelo pré-treinado que aprendeu o que desenhar. É como funciona também o DLSS 3 da NVIDIA pra games, onde o jogo renderiza em baixa resolução, como 720p e o DLSS, em tempo real, redesenha a nova tela em 4K. Não fica perfeito, mas jogando a 60fps, você raramente vai notar a diferença. Só vai perceber que ficou mais NÍTIDO.
Por isso também, se você usar sua própria foto, ou foto de pessoas conhecidas, vai ver que a nova foto depois de upscaling ficou levemente diferente, não é mais a mesma pessoa, porque o modelo REDESENHA detalhes que não existiam. É um processo de interpretação e não de descobrir detalhes “escondidos” (isso não existe, só na ficção de CSI).

O workflow do Mick vai um passo além e tem uma segunda passada de upscaling, focando em consertar somente o rosto om um Node de Face Detailer, feito especificamente pra consertar e melhorar rostos. E aqui entramos em território de cirurgia plástica e harmonização mesmo kkkk o rosto final vai ser diferente do original. Mas pra NPC e personagens secundários não importa, ninguém vai saber a diferença mesmo, basta não estar deformado, zarolho ou algo assim que salta à vista.

Existem Nodes especializados em expressões, como o Expression Editor (PHM) que parte de uma única foto de rosto e consegue gerar novas fotos nas mais variadas emoções - que podemos configurar exatamente, numericamente, como queremos. Não vou mostrar, mas note que as imagens geradas estão em baixa qualidade, mas o próximo passo do workflow é justamente fazer upscaling delas também.

Esse passo é interessante. Primeiro a parte de cima, com os vários cenários. Eles foram todos gerados via os prompts em verde abaixo deles, prompts que o Mick deixou mas podemos editar como quisermos OU trocar o node de geração e colocar de Load Image pra carregar nossas próprias imagens de fundo, de fotos de verdade.
O objetivo desse passo é gerar os rostos sob diferentes configurações de luz. Muita gente pensa que “luz” em jogos é só “acender a luz vermelha” e todo mundo vai ficar vermelho automaticamente. Em jogos novos, com RAY TRACING sim, por isso é SUPER PESADO. Mas em jogos feitos pra máquinas antigas, jogos indie, não dá pra exigir isso de todo mundo.
Daí se usam “truques” pra falsificar coisas como luzes e sombra. É o processo de BAKING onde literalmente “estampamos a luz na textura” dos objetos e personagens. Com a luz global ligada ou desligada, eles sempre vão estar “pintados” na luz colorida da cena. Pra mudar de cena, carregam novas texturas com outras luzes “baked”. Pra programadores, pense em baking como Caching. Pra que toda vez recalcular tudo dinamicamente, se a luz da cena nunca muda? Economize esse passo e já deixe “cacheado”.
Voltando, esse passo usa a tecnologia IC-Light que é outro projeto open source que vale aprender, mesmo se não se interessa por I.A. Ele consegue manipular a luz de qualquer imagem ou foto. Você, como fotógrafo, pode mudar a luz caso tenha mudado de idéia, em pós-produção. Ferramentas da Adobe ou BlackMagic, acho que já incluem tecnologia similar, mas é bom saber que existe open source e dá pra integrar no seu produto.

Depois de gerar os rostos com diferentes luzes, obviamente tem outro passo de upscaling - que estou pulando de mostrar - e vai pro grupo de nodes final que junta tudo num “sheet”, uma “folha do personagem”. O desenvolvedor de jogos pode usar direto num jogo 2D (pense um visual novel game da vida), ou pode servir de base pra UV Mapping de texturas de um modelo 3D simples com Armature pra animar e já tem alguns rostos de emoções. Bom pra colocar no cenário de fundo, pedestres andando na rua, fazendo compras, sentados na praça ou algo assim.

Além disso, o tutorial do Mick descreve como, é possível criar LORAS (Low-Rank Adaptation). Se quiser conseguir gerar personagens com estilo ou mesmo rostos específicos (sem intervenção “artística” da I.A.), você escolhe um modelo como FLUX ou SDXL e “em cima” dele adiciona um segundo sub-modelo compatível com informações sobre essa pessoa ou personagem.
Pra isso você tira várias fotos limpas e bem iluminadas da pessoas, nos mais diferentes ângulos, nem precisa de muito, só uma dúzia é suficiente. Pra cada imagem cria prompts que descrevam bem, e é isso. Tem ferramentas pra gerar esses Loras localmente ou sites que fazem isso (assista o video).
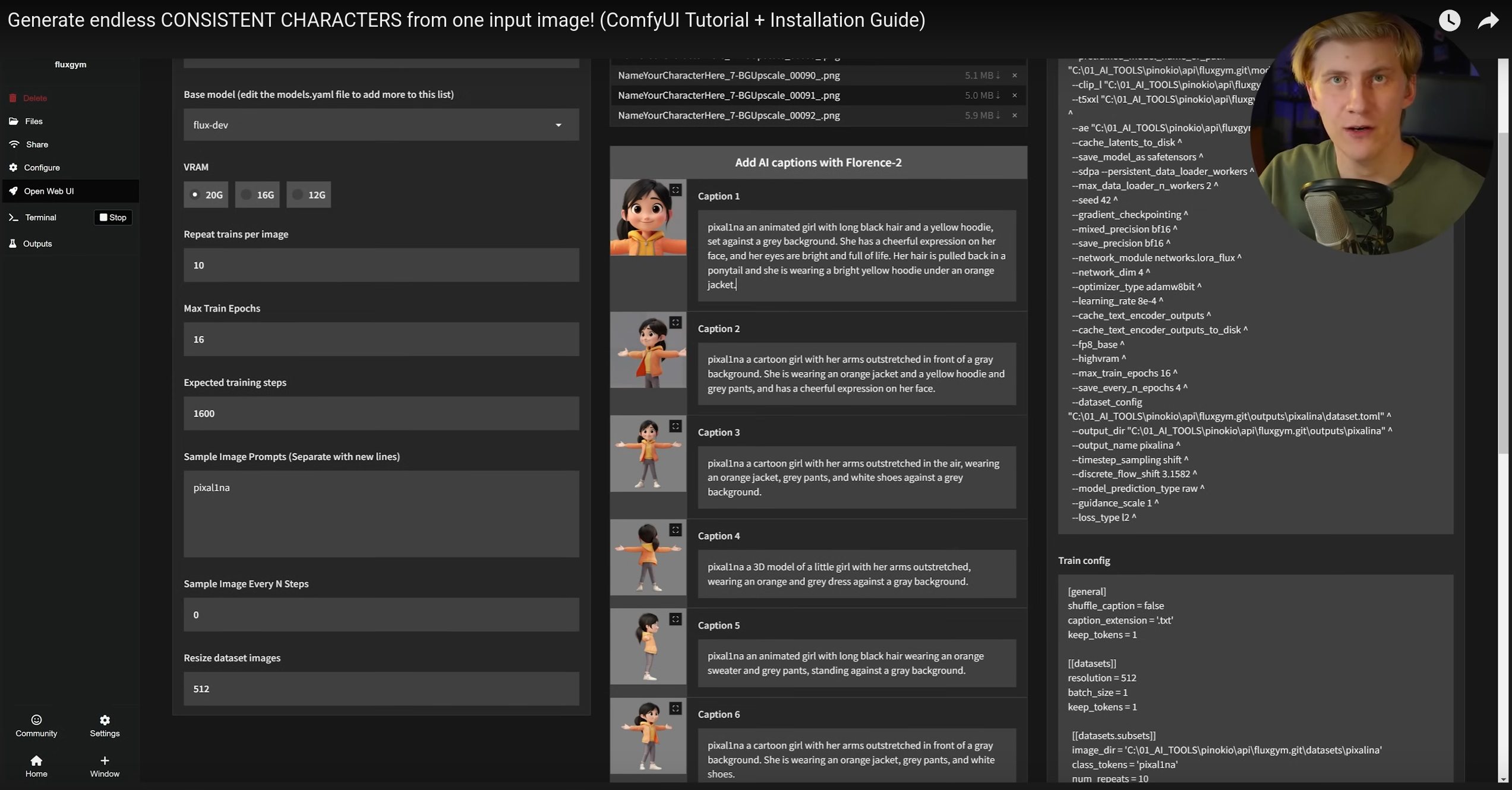
Falando em prompts, em vários workflows existem passos pra descrever prompts detalhados de imagens geradas dinamicamente. Em vez de exigir que o usuário (você) faça isso manualmente, é possível usar um modelo de decoding, que decodifica imagens em prompts de texto. O modelo mais usado pra isso é o FLORENCE 2 da Microsoft.

Esse box de texto embaixo é read-only, você não precisa digitar manualmente. O Node de Florence 2 Run vai ler a imagem e gerar esse texto. Veja como ele descreveu a primeira imagem da mulher na pose de “T”. Fazendo testes, pro seu caso, você determina se só isso é suficiente, se não for basta colocar um segundo Node de prompt e concatenar os dois antes de mandar pra outros nodes.
Enfim, tem MUITA coisa pra explorar só nesse workflow. O Mick fez um excelente trabalho tanto no workflow quanto no video pra explicar e vale a pena pagar os 10 dólares pra contribuir. Existem dezenas de workflows assim disponíveis na Web, basta procurar. E meu setup está cada vez mais complexo. Pretendo ficar ajustando ele pra cada novo workflow interessante que esbarrar. Já tem vários pré-testados na pasta “workflows” do meu projeto pra você brincar.